首发安全客 链接:https://www.anquanke.com/post/id/246020
因为之前发完之后发现某些地方,描述不精确,所以这里做了一点微调
大家好,我是王铁头 一个乙方安全公司搬砖的菜鸡
持续更新移动安全,iot安全,编译原理相关原创视频文章。
因为本人水平有限,文章如果有错误之处,还请大佬们指出,诚心诚意的接受批评。
简介
这篇文章详细讲解了,安卓面试经常会问到的几个技术问题。
以及相关的背景知识,技术原理。
文章中用到的资料代码 和作者的其他技术文章 看这里:https://github.com/wangtietou/Wtt_Mobile_Security
本菜鸡大概面试了30多家公司,因为学历比较差(大专),很多公司看了简历直接就把我刷了。或者简历没看就把我刷了,在boss直聘上看到大佬已读不回 简直是常规操作了。
很多时候根本走不到技术那里。
走到技术那里后,面试失败的概率大概30%左右,有时候是因为我技术菜,有时候是因为要做的细分领域不太一致不太想干,有时候是因为谈不拢工资(我想多要一点,对方不给,哈哈哈哈)。
除了面试经验比较多,面试别人的经验也比较多。
因为我在公司时间也比较长,把之前招我进来的同事成功熬走了,所以现在android逆向面试,移动安全面试这块也是我当面试官。
所以,不管是面试还是被面试,我铁头多少也有一些经验。
安卓逆向面试题汇总 技术篇
面试官经常问的几个问题如下:
- 常见的加固手段有哪些
- 安卓反调试一般有哪些手段,怎么去防范
- arm汇编 b bl bx blx 这些指令是什么意思
- ida xx操作的快捷键是哪个?
- Xposed hook 原理 frida hook 原理
- inline hook原理
- ollvm 代码混淆你了解吗?要怎么去处理
上面是一个汇总的目录,下面一个一个仔细拆分 详细说说
安卓逆向面试题详解
1)常见的加固手段
网上有的人把安卓壳分成五代壳,有人分成三代壳。
不同的人对这块的,具体的区分和看法不同,但是五代壳更细分一些。
在加固厂商内部,用的是五代壳的标准,当然他们PPT已经出现了第6 ,7 ,8代壳。
我入行以及搬砖的时候,周围人用的基本都是下图的标准,所以我这里用五代壳来描述。
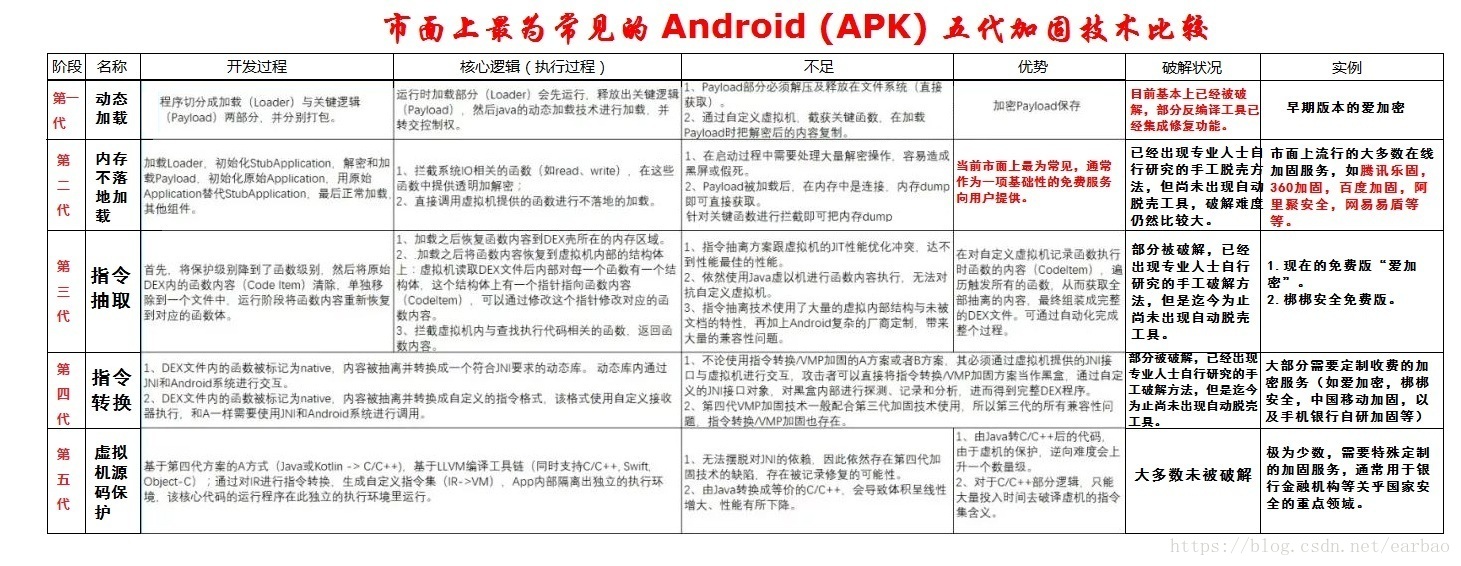
上面的图把安卓五代壳的优缺点,实现逻辑讲的非常好。大佬们理解了上面这两张图,回答第一个问题基本就ok了。
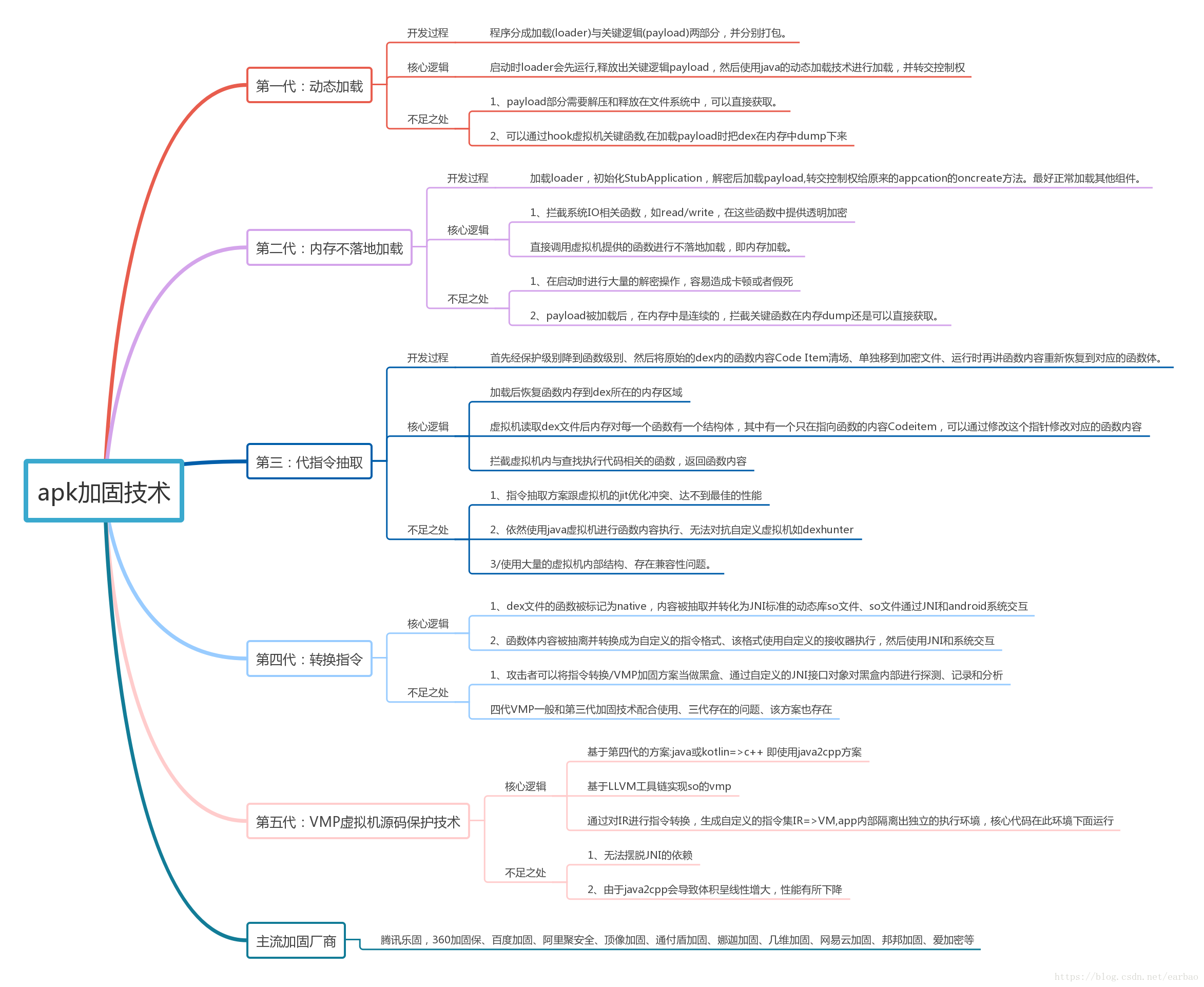
但是,大哥们既然看到了我这个文章,大佬们就可以风骚一点多说一些,说些面试官也不知道的。
毕竟, 唬不住5k,唬得住50k
说完上面的大概就是个及格分,说点下面的,面试官如果不了解这块的话当时就被你给唬住了。
大佬们如果在公司负责甲方安全,采购过企业版加固,或者在加固厂商搬过砖的话就会知道。
加固虽然大体上分为免费版和企业版。
免费版里面有的公司基本没啥加固选项,上传个apk应用包梭哈就完事了。
比如这种。

有的公司还是 比较人性化的,用户可以根据自己需求选择加固选项。比如这种

可以看到,免费版这里,厂商玩的花样并不多,有的就是上传一个包,啥加固选项没有,有的虽然有,加固选项也就几个。
但是企业版这里,厂商们花样都比较多。
假设某加固公司,企业版实现了6个功能(一般是十几个 二十几个 我这里做个比喻)。
功能如下:
- 签名校验。
- 密钥白盒
- 反xposed frida
- 源代码深度混淆
- h5加固
- 内存防dump
这上面的功能是插件化的,你可以根据实际应用场景选择其中几个功能,也可以都要。
比如你的app根本么有h5页面,你选个h5加固不是白花钱吗。
这里套餐不同,价格也是不同的。(企业壳大概一年几万吧)
销售那里不同的功能组合有不同的报价,就像A公司选了1,3,5。 你选了 2,4,6. 虽然都是企业版,但是你和别人的企业版还是有区别的。
说这些就是表示,不同apk即使用了同一家厂商的企业版加固,选择的加固方式也是不一样的。
而且,一些行业的客户,加固厂商各自也会有针对行业的一些加固手法。
比如一些手游,加固厂商就会有一些反外挂的操作,针对内存读写的强检测,一些金融客户哪,因为对用户信息保密程度要求高,就会做一些安全键盘和防录屏截屏操作。
这里一些加固公司还把加固方式也做成了插件化,比如一个apk,同时用2代壳和4代壳的加固方式都用上。2代壳不落地加载结合4代壳dexvmp,或者3代壳指令抽取结合4代壳dexvmp,这里混合也是他们的常用套路,不会影响app正常运行。
说到这里有的大佬可能会疑惑,2代3代4代不是不同的加固方式吗?是怎么结合的哪?这里我解释一下
假设加固厂商拿到了一个未加固的dex, 那么2 3 4代壳子是怎么结合的。
-
dex比较重要的部分,比如算法部分,登录模块,这块的方法内容被抽取转换成自定义的指令格式,然后调用系统底层的jni方法执行。(4代壳dexvmp)
-
其他不重要方法体直接抽空, 单独加密,运行的时候方法体内容再动态还原(3代抽取)。
-
加载这个dex的时候(现在的dex已经经过了上面2步处理 里面的方法很多被抽空,一些被dexvmp保护), 并不是写出到文件系统用 dexclassloader这样的api去加载, 而是读到内存中直接加载,直接调用c层API加载内存中的dex(2代不落地加载)
还有一些更深度的定制,反正有钱就是大爷,你钱多干啥都可以商量,一般企业壳加固后你还是可以看到厂商的特征加固文件。比如你看到libjiagu.so就觉得是360 ,深度定制后,特征文件你一个都找不到,而且还可以实现一些定制化的需求。

企业版功能插件化,套餐化,加壳方式组合这些东西,一般来说很多人是不知道的,所以说说这些,能很快的把你从众多普通面试者中区分出来。

把这一点说上,到时候面试官说不定因为过于欣赏你,把他大学刚毕业,没有男朋友的妹妹介绍给你了。
所以,当面试官问加固方式这块的时候,你除了把两张图的内容说清楚,还可以清清嗓子,一脸高手寂寞的神情。
悠悠地说:
其实吧,很多我搞过的企业壳,看的出来挺多都是定制化的,有的是2代壳结合4代壳的加固,有的是2代3代混合4代。
感觉很多企业壳根据不同的业务场景,买了不同的加固套餐,比如xx应用,我脱壳的时候,发现有 清场sdk, ollvm混淆。 另一个企业壳根本就没有这些,大部分逻辑在后端,不过也搞了密钥白盒和H5加固。
还有一些游戏的企业壳,内存读写明显防护是比较厉害的。金融这块的也基本都有安全键盘,和防截屏的一些保护。
这时候,状若无意的对面试官说:“你说是吧”。
perfect.
2)安卓逆向反调试的手段有哪些
这里比较常用的反调试手段有
-
ptrace检测
背景知识:ptrace是linux提供的API, 可以监视和控制进程运行,可以动态修改进程的内存,寄存器值。一般被用来调试。ida调试so,就是基于ptrace实现的。
因为一个进程只能被ptrace一次, 所以进程可以自己ptrace自己,这样ida和别的基于ptrace的工具和调试器或就无法调试这个进程了。
实现代码:
int check_ptrace()
{
// 被调试返回-1,正常运行返回0
int n_ret = ptrace(PTRACE_TRACEME, 0, 0, 0);
if(-1 == n_ret)
{
printf("阿偶,进程正在被调试
");
return -1;
}
printf("没被调试 返回值为:%d
",n_ret);
return 0;
}
定位方法:直接在ptrace函数下断点。
绕过方法:手动patch,或者用frida之类的工具hook ptrace直接返回0.
实例演示

-
TracerPid检测:
背景知识:TracerPid是进程的一个属性值,如果为0,表示程序当前没有被调试,如果不为0,表示正在被调试, TracerPid的值是调试程序的进程id。
实现代码:
#define MAX_LENGTH 260
//获取tracePid
int get_tarce_pid()
{
//初始化缓冲区变量和文件指针
char c_buf_line[MAX_LENGTH] = {0};
char c_path[MAX_LENGTH] = {0};
FILE* fp = 0;
//初始化n_trace_pid 获取当前进程id
int n_pid = getpid();
int n_trace_pid = 0;
//拼凑路径 读取当前进程的status
sprintf(c_path, "/proc/%d/status", n_pid);
fp = fopen(c_path, "r");
//打不开文件就报错
if (fp == NULL)
{
return -1;
}
//读取文件 按行读取 存入缓冲区
while (fgets(c_buf_line, MAX_LENGTH, fp))
{
//如果没有搜索到TracerPid 继续循环
if (0 == strstr(c_buf_line, "TracerPid"))
{
memset(c_buf_line, 0, MAX_LENGTH);
continue;
}
//初始化变量
char *p_ch = c_buf_line;
char c_buf_num[MAX_LENGTH] = {0};
//把当前文本行 包含的数字字符串 转成数字
for (int n_idx = 0; *p_ch != '�'; p_ch++)
{
//比较当前字符的ascii码 看看是不是数字
if (*p_ch >= 48 && *p_ch <= 57)
{
c_buf_num[n_idx] = *p_ch;
n_idx++;
}
}
n_trace_pid = atoi(c_buf_num);
break;
}
fclose(fp);
return n_trace_pid;
}
相关特征 定位方法: 一般检测TracerPid都会读取 /proc/进程号/status 这个文件
所以可以直接搜索 /status 这种字符串,这里也会用到getpid, fgets这种API,所以也可以通过这两个api定位。
绕过手法:
- 直接手动patch, nop掉调用
- 编译内核,修改linux kernel源代码,让 TracerPid永久为0. 修改方法 https://cloud.tencent.com/developer/article/1193431
实例演示:
这里用android studio 调试app 查看app进程对应的 status,status里查看TracerPid的值


可以看到TracerPid的值 是调试器的进程id。

没被调试的时候,TracerPid的值是0。
-
自带调试检测函数android.os.Debug.isDebuggerConnected()
背景知识:自带调试检测api, 被调试时候返回 true, 否则返回 false。
import static android.os.Debug.isDebuggerConnected;
public static boolean is_debug()
{
boolean b_ret = isDebuggerConnected();
return b_ret;
}
相关特征 定位方法: 直接搜索isDebuggerConnected函数名即可。
绕过手法:frida之类的工具直接hook函数,直接返回false.

- 检测调试器端口 比如 ida 23946 frida 27042 之类的
背景知识:调试器服务端默认会打开一些特定端口,方便客户端通过电脑usb线,或者直接通过局域网进行连接。
实现代码:
//返回找到的特征端口数量
int check_debug_port()
{
//特征端口字符串数组 0x5D8A是23946的十六进制 69a2是27042十六进制
//这里为了提高精确度 加个 :
char* p_strPort_ary[] = {":5D8A", ":69A2"};
int n_port_num = 2; //特征端口数量
//找到特征端口数量 返回值
int n_find_num = 0;
//初始化文件指针 路径 和缓冲区
FILE* fp = 0;
char c_line_buf[MAX_LENGTH] = {0};
char* p_str_tcp = "/proc/net/tcp";
fp = fopen(p_str_tcp, "r");
if(NULL == fp )
{
return -1;
}
//读取文件 看当前文件包含了几个特征端口号
while(fgets(c_line_buf, MAX_LENGTH - 1, fp))
{
for (int i = 0; i < n_port_num; ++i)
{
//如果从当前文本行 找到特定端口号
char* p_line = p_strPort_ary[i];
if(NULL != strstr(c_line_buf, p_line))
{
n_find_num++;
}
}
memset(c_line_buf, 0, MAX_LENGTH);
}
fclose(fp);
//返回找到的特征端口数量
return n_find_num;
}
相关特征 定位方法:读取端口时,一般都会读取 /proc/net/tcp文件,所以可以搜索关键字,或者 popen(管道执行命令) fgets(读取文件行)这种api进行定位。
案例演示:
这里启动 frida_server,然后查看/proc/net/tcp文件内容,果然发现了frida_server对应的端口。



绕过手法:换个端口就可。
android_server 换端口
这里注意 -p 和 端口之间是没有空格的 直接连接
/data/local/tmp/android_server -p8888 //运行android_server 以端口8888运行
adb forward tcp:8888 tcp:8888 //转发端口 8888
frida-server 切换端口 这里切换成 6666端口
/data/local/tmp/frida_server -l 0.0.0.0:6666 //启动frida_server 监听6666
adb forward tcp:6666 tcp:6666 //转发6666端口
frida -H 127.0.0.1:6666 package_name -l hook.js //注入js
-
根据时间差反调试
背景知识:在关键逻辑的开始和结束的地方,获取当前的秒数。结束时间减去开始时间,如果超过一定时间,认定是在调试。因为程序运行速度很快的,卡到2-3秒执行完,除非你逻辑好多,算法很复杂,要不基本不大可能。绕过方法:手动nop掉。
案例演示:

这里不用说的太全,说几个常见的就行了。说全了时间也不太够。
3)arm汇编 B、BL、BX、BLX区别和指令含义
这里对这几条指令有个简单记忆的方法 那就是对几条指令中的字母单独记忆,然后遇到字母的组合,就把字母代表的含义加起来就可了。
单独记忆法:
字母 B: 跳转 类似jmp
字母 L: 把下一条指令地址存入LR寄存器
字母 X: arm和thumb指令的切换
注意:这样去记 是为了快速记住上面几条指令的含义 而不是 单字母本身在汇编里面有这些含义
所以,4条指令的的含义就是
-
B 这里跟x86汇编的 jmp比较像,可以理解成无条件跳转
-
BL :这里理解成 字母B + 字母L 作用是 把下一条指令地址存入LR寄存器 然后跳转。 像x86汇编里面的 call , 只不过call指令把下一条指令的地址压入栈,BL是把下一条指令的地址放到 LR寄存器。
-
BX 这里理解成 字母B + 字母X 这里表示跳转到一个地址,同时切换指令模式 当前如果是arm 就会切换成 Thumb 如果是Thumb 就会切换成arm
-
BLX 这里是 字母B + 字母L + 字母X 表示跳转到一个新的地址,跳转的时候把下一条指令地址存入LR寄存器 同时切换指令模式 arm转thumb thumb转arm
可以这样去理解: blx = call + 切换指令模式
4)ida 使用 快捷键
G :跳转到指定地址

Shift + F12:字符串窗口,用于字符串搜索

Y:修改变量类型 函数声明快捷键

除了修改变量类型 也可以修改函数的返回值类型 和 参数类型

X : 查看 变量 常量 函数 的引用

在定位算法的时候 用x查看关键变量的引用也是很有效的一种方式

同样可以按X查看常量的引用 定位一些字符串到底在哪个函数还是蛮好用的

Ctrl+S:查看节表

5)frida hook原理 xposed注入原理
- frida注入原理
frida 注入是基于 ptrace实现的。frida 调用ptrace向目标进程注入了一个frida-agent-xx.so文件。后续骚操作是这个so文件跟frida-server通讯实现的
ida调试也是基于 ptrace实现的。
那为什么有人能动静结合用 frida 和 ida一起调试哪?一个进程只能被ptrace一次,那这里为啥两个能结合?
答案是:先用frida注入,然后用调试器调试。
frida在使用完ptrace之后 马上就释放了,并没有一直占用,所以ida后续是可以附加,继续使用ptrace的。

- xposed注入原理
安卓所有的APP进程是用 Zygote(孵化器)进程启动的。
Xposed替换了 Zygote 进程对应的可执行文件/system/bin/app_process,每启动一个新的进程,都会先启动xposed替换过的文件,都会加载xposed相关代码。这样就注入了每一个app进程。
6)inline hook原理
这里 我画了一个图,大佬们自己看图
原理描述:修改函数头,跳转到自定义函数,自定义函数就是自己想执行的逻辑,执行完自己的逻辑再跳转回来。


7) ollvm 代码混淆了解过吗 ,一般怎么处理
一般这个难度的问题会放到靠后,除非你在简历里就写了自己锤过很多 ollvm混淆过的代码.
这里大佬们要是实在不会 对这块没啥了解,也建议大佬们挣扎一下,把下面我列的说一下 。也能争取点卷面分
ollvm是一个代码混淆的框架
这个框架通过以下三种方式实现了代码混淆
| 英文全称 | 简称/参数表示 | |
|---|---|---|
| 控制流平坦化 | Control Flow Flattening | fla |
| 虚假控制流 | Bogus Control Flow | bcf |
| 指令替换 | Instructions Substitution | sub |
| 这三种可以全部选择。也可以随意组合,具体怎样组合看具体根据具体场景去决定。 |
下面一个一个详细讲解
-
被混淆前的源代码 在ida中的样子
在没有使用控制流平坦化之前 代码在反编译工具里面看的都是比较清晰的
#include <cstdio>
int main(int n_argc, char** argv)
{
int n_num = n_argc * 2;
//scanf("%2d", &n_num);
if (20 == n_num)
{
puts("20");
}
if(10 == n_num)
{
puts("10");
}
if(2 == n_num)
{
puts("2");
}
puts("error");
return -1;
}
拖入ida后 流程图如下 这里可以看到流程还是很清晰的

下面是 源代码 加了不同参数后 被ollvm混淆后的样子




这里我用自己的话简单描述 ollvm的3种混淆方式
-
fla 控制流平坦化:
混淆前混淆后如下图所示:混淆前:

混淆后:
代码本来是依照逻辑顺序执行的,控制流平坦化是把,原来的代码的基本块拆分。
把本来顺序执行的代码块用 switch case打乱分发,根据case值的变化,把原本代码的逻辑连接起来。让你不知 道代码块的原本顺序。让逆向的小老弟一眼看过去不知道所以然,不知道怎么去分析。
-
bcf 虚假控制流:一般是通过全局变量,构造恒等式(一定会成立),和恒不等式(一定不成立),插入大量这种看似有用,实际上就是在为难你的代码。
if(x == 0) { ...代码A } if(y == 0) { ...代码B }上面写了两段伪代码。 假设 x的值是0 y的值是1
那么 在上面的代码中
if(x == 0) 这个条件一定是成立的
if(y == 0)这个条件是一定不成立的。bcf虚假控制流,通过构造x,y 这种全局变量。让编译器不能推断x,y的值.(不透明维词)
通过大量插入一些跟上面类似的恒等式,和恒不等式(不可达分支),然后在这些分支在里面写一些代码,把原逻辑串联起来。 -
sub指令替换
指令替换对程序的基本块架构没有任何影响。对比下面两个图 混淆跟没有混淆进行对比之后,可以发现。
程序控制流和基本块的顺序,执行流程没有什么变化。当然这也跟这个函数基本没啥运算指令有关系。

只是把 x = x + 1 这样的代码 替换成类似于 x = x + 2 + 1 - 2 这样的代码
增大代码体积,把简单的指令变复杂。增大分析的难度
这里,大佬们在回答 ollvm这块的话 把我上面写的说一下就大概差不多了。
面试官如果问大佬们怎么解决:
大佬们可以这么说
-
通过unicorn 模拟执行去除控制流平坦化
https://bbs.pediy.com/thread-252321.htm -
通过angr 符号执行 去除控制流平坦化
https://security.tencent.com/index.php/blog/msg/112 -
通过angr 符号执行 去除虚假控制流
https://bbs.pediy.com/thread-266005.htm -
通过Miasm符号执行移除OLLVM虚假控制流
https://www.52pojie.cn/thread-995577-1-1.html
总结:
上面讲解了安卓逆向面试中,经常问的几个技术问题,背后的原理,该怎么回答。
当然除了技术篇,还会问一些发展方向,技术追求,看你稳定性之类的。
希望大佬们都能顺利拿到 offer, 如果看完文章有所收获,而且还顺利入职的话,大佬们可以过来还愿下。
以上
2021.7.1 王铁头于公司办公楼
相关参考:
https://segmentfault.com/a/1190000037697547
https://blog.csdn.net/earbao/article/details/82379117
https://blog.csdn.net/qq_42186263/article/details/113711359
--文章结束--
持续更新移动安全,iot安全,编译原理相关原创视频文章
演示视频:https://space.bilibili.com/430241559