最近有一个需求是这样的,
根据键值对存储类型数据,也算是数据缓存块模块功能设计。
一个键对应多个值。每一个键的值类型相同,但是每个不同的键之间类型不一定相同。
Java 设计如下
HashMap<String, ArrayList<Object>>
java把数据添加到集合中
TestIterator tIterator = new TestIterator(); ArrayList<Object> objs = new ArrayList<>(); objs.add("sdfsfdsfdsf"); objs.add("sdfsfdsfdsf"); objs.add("sdfsfdsfdsf"); objs.add("sdfsfdsfdsf"); tIterator.getList().put("Key1", objs); objs = new ArrayList<>(); objs.add(1); objs.add(2); objs.add(3); objs.add(4); tIterator.getList().put("Key2", objs); objs = new ArrayList<>(); objs.add(new String[]{"1", ""}); objs.add(new String[]{"2", ""}); objs.add(new String[]{"3", ""}); objs.add(new String[]{"4", ""}); tIterator.getList().put("Key3", objs);
添加进数据缓存后,然后读取数据,我们先忽略,缓存集合的线程安全性问题,
{ ArrayList<Object> getObjs = tIterator.getList().get("Key1"); for (Object getObj : getObjs) { System.out.println("My is String:" + (String) getObj); } } { ArrayList<Object> getObjs = tIterator.getList().get("Key2"); for (Object getObj : getObjs) { System.out.println("My is int:" + (int) getObj); } } { ArrayList<Object> getObjs = tIterator.getList().get("Key3"); for (Object getObj : getObjs) { String[] strs = (String[]) getObj; System.out.println("My is String[]:" + strs[0] + " : " + strs[1]); } }
我们发现。使用的时候,每个地方都需要转换。
(String[]) getObj; (int) getObj (String) getObj
同样代码需要重复写,那么我们是否可以封装一次呢?
public <T> ArrayList<T> getValue(String keyString, Class<T> t) { ArrayList<T> rets = new ArrayList<>(); ArrayList<Object> getObjs = _List.get(keyString); if (getObjs != null) { for (Object getObj : getObjs) { //if (getObj instanceof T) { rets.add((T) getObj); //} } } return rets; }
这里我发现一个问题,不支持泛型检查,据我很浅的知识了解到,java算是动态类型数据。
并且是伪泛型类型所以不支持泛型类型判定
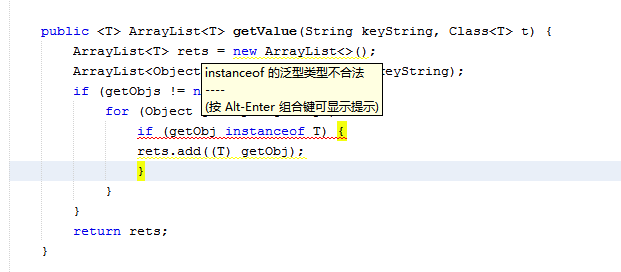
这点很不爽了,为啥不能泛型类型判定。也许是我知识浅薄~!望前辈指点;
再次查看调用
{ ArrayList<String> value = tIterator.getValue("Key1", String.class); for (String value1 : value) { } } { ArrayList<Integer> value = tIterator.getValue("Key1", Integer.class); for (Integer value1 : value) { } } { ArrayList<String[]> value = tIterator.getValue("Key1", String[].class); for (String[] value1 : value) { } }
稍稍觉得清爽了一点吧。当然,我这里都是用到基础类型,如果用到复杂类型,和满篇调用的时候才能体现出这段代码的优越性。
更加的符合面向对象编程的重构行和复用性;
可是上面代码,不晓得大家注意没,出现一个问题,那就是每一次调用都再一次的声明了
ArrayList<T> rets = new ArrayList<>();
对象,如果是需要考虑性能问题的时候,我们肯定不能不能这样。每次调用都需要重新分配ArrayList的内存空间。并且在 ArrayList.add() 的时候每一次都在检查ArrayList的空间够不够,不够,再次开辟新空间。重组。
虽然这个动作很快,可是如果我们缓存的数据过多。那么情况可就不一样了。且伴随着每一次的调用都是一个消耗。访问次数过多的话。那么程序的的性能势必会变的低下。
再次考虑,是否可以用迭代器实现功能呢?
查看了一下迭代器实现方式,我无法完成我需求的迭代器功能。只能依葫芦画瓢,实现了一个自定义的迭代器功能。
class TestIterator { HashMap<String, ArrayList<Object>> _List = new HashMap<>(); public TestIterator() { } public <T> ArrayList<T> getValue(String keyString, Class<T> t) { ArrayList<T> rets = new ArrayList<>(); ArrayList<Object> getObjs = _List.get(keyString); if (getObjs != null) { for (Object getObj : getObjs) { //if (getObj instanceof T) { rets.add((T) getObj); //} } } return rets; } public HashMap<String, ArrayList<Object>> getList() { return _List; } public void setList(HashMap<String, ArrayList<Object>> _List) { this._List = _List; } public <T> TestIterator.ArrayIterator<T> iterator(String keyString, Class<T> t) { return new ArrayIterator<T>(keyString); } public class ArrayIterator<T> { private String key; int index = -1; private T content; public ArrayIterator(String key) { this.key = key; } public void reset() { index = -1; } public T getContent() { //忽略是否存在键的问题 Object get = TestIterator.this._List.get(key).get(index); return (T) get; } public boolean next() { //忽略是否存在键的问题 if (index >= TestIterator.this._List.get(key).size()) { reset(); return false; } index++; return true; } } }
调用方式
{ TestIterator.ArrayIterator<String> iterator1 = tIterator.iterator("Key1", String.class); while (iterator1.next()) { String content = iterator1.getContent(); } } { TestIterator.ArrayIterator<Integer> iterator1 = tIterator.iterator("Key2", Integer.class); while (iterator1.next()) { Integer content = iterator1.getContent(); } } { TestIterator.ArrayIterator<String[]> iterator = tIterator.iterator("Key3", String[].class); while (iterator.next()) { String[] content = iterator.getContent(); } }
总结了一些问题,
Java的泛型是伪泛型,底层其实都是通过object对象,装箱拆箱完成的。
/** * Shared empty array instance used for empty instances. */ private static final Object[] EMPTY_ELEMENTDATA = {}; /** * Shared empty array instance used for default sized empty instances. We * distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when * first element is added. */ private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; /** * The array buffer into which the elements of the ArrayList are stored. * The capacity of the ArrayList is the length of this array buffer. Any * empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA * will be expanded to DEFAULT_CAPACITY when the first element is added. */ transient Object[] elementData; // non-private to simplify nested class access
这个从我目前代码设计思路我能理解。如果让我自己设计。也行也会设计如此。
但是无法理解为什么使用泛型无法类型判定;
我这个自定义的迭代器无法使用 for each 功能;
说了这么多。接下来我们看看.net;
C# 设计如下
Dictionary<String, List<Object>>
TestIterator tIterator = new TestIterator(); List<Object> objs = new List<Object>(); objs.Add("sdfsfdsfdsf"); objs.Add("sdfsfdsfdsf"); objs.Add("sdfsfdsfdsf"); objs.Add("sdfsfdsfdsf"); tIterator["Key1"] = objs; objs = new List<Object>(); objs.Add(1); objs.Add(2); objs.Add(3); objs.Add(4); tIterator["Key2"] = objs; objs = new List<Object>(); objs.Add(new String[] { "1", "" }); objs.Add(new String[] { "2", "" }); objs.Add(new String[] { "3", "" }); objs.Add(new String[] { "4", "" }); tIterator["Key3"] = objs;
由于有了以上 Java 部分的代码和思路,那么我们直接创建自定义迭代器就可以了;
public class TestIterator : Dictionary<String, List<Object>> { public IEnumerable<T> CreateEnumerator<T>(String name) { if (this.ContainsKey(name)) { List<Object> items = this[name]; foreach (var item in items) { if (item is T) { Console.WriteLine(item); yield return (T)item; } } } } }
查看调用方式
foreach (var item in tIterator.CreateEnumerator<String>("tt1")) { Console.WriteLine(item + "艹艹艹艹"); }
输出结果:
yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf
查看对比一下调用方式
foreach (var item in tIterator.CreateEnumerator<String>("Key1")) { Console.WriteLine("foreach : " + item); } Console.WriteLine("===============分割线=============="); IEnumerable<String> getObjs = tIterator.CreateEnumerator<String>("Key1").ToList(); foreach (var item in getObjs) { Console.WriteLine("foreach : " + item); }
主要上面的两张调用方式。输出结果完全不同
yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf ===============分割线============== yield return : sdfsfdsfdsf yield return : sdfsfdsfdsf yield return : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf foreach : sdfsfdsfdsf foreach : sdfsfdsfdsf foreach : sdfsfdsfdsf
可以看出第二种调用方式是全部返回了数据,那么就和之前java的设计如出一辙了.
public <T> ArrayList<T> getValue(String keyString, Class<T> t) { ArrayList<T> rets = new ArrayList<>(); ArrayList<Object> getObjs = _List.get(keyString); if (getObjs != null) { for (Object getObj : getObjs) { //if (getObj instanceof T) { rets.add((T) getObj); //} } } return rets; }
虽然表面看上去没有声明List对象,可实际底层依然做好了底层对象的分配对性能也是有所消耗;
C# 迭代器实现了泛型类型判定检测;
且没有多余的开销,
总结。
Java的自定义迭代。多出了一下定义
private String key; int index = -1; private T content;
不支持泛型的类型判别;
C# 的自定义迭代器 没什么多余的代码开销,但其实底层依然做了我们类使用Java的自定义代码段。只是我们无需再定义而已。
C# 支持 泛型类型的判别。
其实这些都是语法糖的问题。没有什么高明或者不高明之处。但是在面对快速开发和高性能程序的基础上,优势劣势。自己判别了。
以上代码不足之处,还请各位看客之处。
不喜勿碰~!~!~!