一、什么是hadoop
hadoop是一个开源的分布式计算和存储的框架。
二、什么是mapreduce?
从总体上来讲,MapReduce主要包括三个阶段,map阶段, shuffle阶段, reduce阶段,如果大家对我前面讲的HDFS还有印象,应该能知道split这个过程,其实是HDFS帮我们做了,下面我从map的输入开始,剖析一下整个MapReduce的过程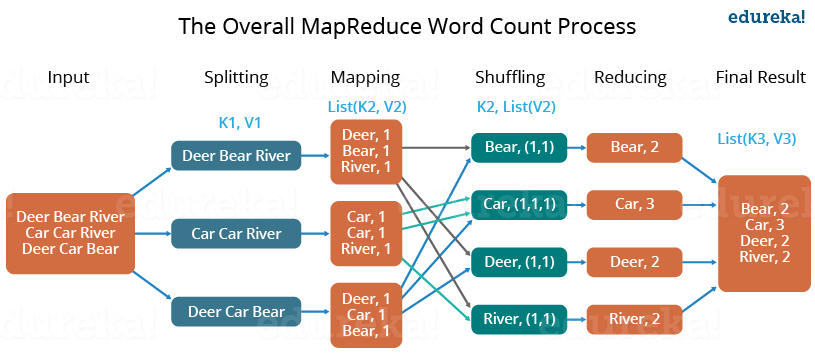
Map 函数拿到数据以后,会根据用户自定义的逻辑对数据进行处理,然后产生输出。
三、什么是shuttle?
Shuffle:MapReduce的“心脏”,是奇迹发生的地方。
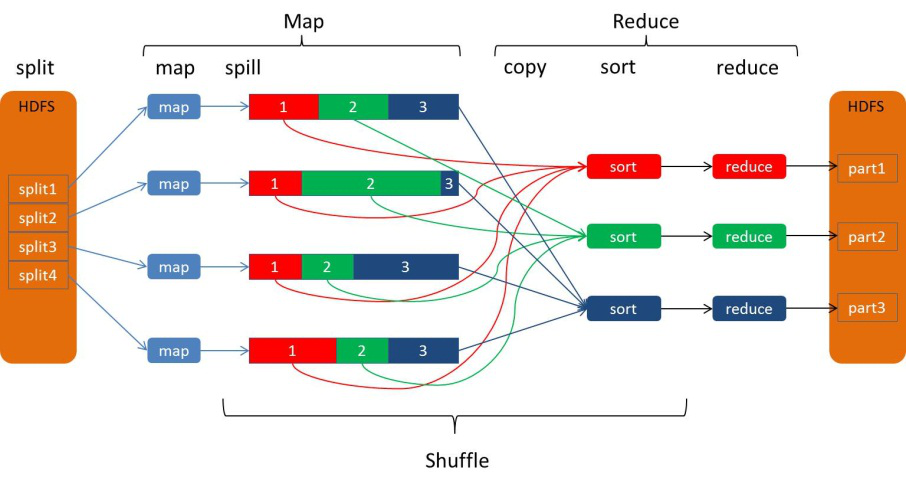
在整个MapReduce的生命周期中,纯粹的Map阶段和过程的reduce过程,其实只占了很小的一部分,整个MapReduce的核心其实是Shuffle过程,也被称为奇迹发生的地方。之前那张Word Count过程图对shuffle这个过程体现的并不是很明显,因为那张图主要是想让大家用Word Count这个实际的列子,对MapReduce整个过程能有一个感性的认识,真正的MapReduce过程,应该像这张图所展示的一样,从map task输出到reduce task输入的这段过程都是shuffle,用一句话概括一下Shuffle做了什么事情就是,把map输出端的结果有序的传递给reduce的输入端。 从上面这个图可以看出,整个shuffle阶段,横跨了Map过程与Reduce过程,所以shuffle阶段又可分为map阶段的shuffle, map-shuffle 和 reduce 阶段的shuffle, reduce-shuffle, 在map-shuffle阶段主要完成了spill这个过程,在reduce-shuffle阶段,主要完成了copy和sort这个过程。 下面我们来详细的看一下shuffle阶段是如何通过spill,copy,sort这个三个过程,把map输出端的结果有序的传递给reduce的输入端。 先来看map-shuffle 阶段的 spill 过程 Spill过程简单来说就是把Map任务输出的中间结果写到本地磁盘上。以后供Reduce调用,做为Reduce端的输入。 但是怎么把中间结果写到磁盘上就比较有讲究了,不是随随便便一写就完事儿了,因为写磁盘的过程中既要考虑到写入的性能,因为不能出一个结果就写一次磁盘,出一个结果就写一次磁盘,这样效率会很低,又要考虑到为后续传递给reduce做准备。因为在实际使用中,一般会不止一个Reduce,而一个Map的输出,最后通常会传递给多个Reduce,如果我们能事先对Map的输出进行分区(这里讲一下partition的概念),或者说的更通俗一点就是把将来要传递给同一个reduce数据都有序的放在一起,这样就可以大大提升接下来从Map输出端拷贝输出结果到Reduce输入端的效率, 纯粹的map和存粹的reduce都只是很小的一部分,在map产生输出的时候,其实就已经的进入到了MapReduce的核心阶段,Shuffle阶段,Shuffle阶段又被称之为“奇迹发生的地方” where the miracle happens 整个shuffle阶段由spill过程,copy过程,sort过程组成。
四、 什么是YARN?
Yarn的定义是 Yet Another Resource Negotiator,另一种资源协调者。 因为在Hadoop刚出来的时候,那时候还没有Yarn,Hadoop的工作调度都是由JobTracker和TaskTracker来做的,但是JobTracker和TaskTracker在设计上存在缺陷,主要问题是,单点压力过大最多只能支持近4000台机器,而且容易造成单点故障问题,所以慢慢的被弃用了,后来就出现了Yarn,Yarn在设计上更具有一般性,实际上MapReduce只是Yarn上的一个应用而已,Yarn上不但能支撑MapReduce,还能支撑自打出生以来就火的不要不要的内存计算并行计算框架Saprk,流式计算框架Storm 等等 … Yarn 由五个独立的实体组成。
Client:用来提交( MapReduce )Job;
ResourcesManager:用来管理协调分配集群中的资源;
NodeManager:用来启动和监控本地计算机资源单位Container的利用情况;
Application Master:用来协调( MapReduce )Job下的Task的运行;
HDFS:用来在其他实体之间共享作业文件。