算法与数据结构是计算机学习路上的内功心法,也是学好编程语言的重要基础。今天给大家介绍一下十大经典算法。
十大经典算法分别是:冒泡排序,插入排序,选择排序,希尔排序,快速排序,归并排序,桶排序,堆排序,计数排序,基数排序。
预备知识:算法稳定性
如果 a==b,排序前 a 在 b 的前面,排序后 a 在 b 的后面,只要会出现这种现象,我们则说这个算法不稳定(即使两个相等的数,在排序的过程中不断交换,有可能将后面的 b 交换到 a 的前面去)。
一、冒泡排序
冒泡排序(Bubble Sort)是基于交换的排序,它重复走过需要排序的元素,依次比较相邻的两个元素的大小,保证最后一个数字一定是最大的,即它的顺序已经排好,下一轮只需要保证前面 n-1 个元素的顺序即可。
之所以称为冒泡,是因为最大/最小的数,每一次都往后面冒,就像是水里面的气泡一样。
排序的步骤如下:
- 从头开始,比较相邻的两个数,如果第一个数比第二个数大,那么就交换它们位置。
- 从开始到最后一对比较完成,一轮结束后,最后一个元素的位置已经确定。
- 除了最后一个元素以外,前面的所有未排好序的元素重复前面两个步骤。
- 重复前面 1 ~ 3 步骤,直到都已经排好序。
例如,我们需要对数组 [98,90,34,56,21] 进行从小到大排序,每一次都需要将数组最大的移动到数组尾部。那么排序的过程如下动图所示:
二、选择排序
前面说的冒泡排序是每一轮比较确定最后一个元素,中间过程不断地交换。而选择排序就是每次选择剩下的元素中最小的那个元素,直到选择完成。
排序的步骤如下:
- 从第一个元素开始,遍历其后面的元素,找出其后面比它更小的元素,若有,则两者交换,保证第一个元素最小。
- 对第二个元素一样,遍历其后面的元素,找出其后面比它更小的元素,若存在,则两者交换,保证第二个元素在未排序的数中(除了第一个元素)最小。
- 依次类推,直到最后一个元素,那么数组就已经排好序了。
比如,现在我们需要对 [98,90,34,56,21] 进行排序,动态排序过程如下:

三、插入排序
选择排序是每次选择出最小的放到已经排好的数组后面,而插入排序是依次选择一个元素,插入到前面已经排好序的数组中间,当然,这是需要已经排好的顺序数组不断移动。步骤描述如下:
- 从第一个元素开始,可以认为第一个元素已经排好顺序。
- 取出后面一个元素
n,在前面已经排好顺序的数组里从尾部往头部遍历,假设取出来的元素为nums[i],如果num[i]>n,那么将nums[i]移动到后面一个位置,直到找到已经排序的元素小于或者等于新元素的位置,将n放到新空出来的位置上。如果没有找到,那么 nums[i] 就是最小的元素,放在第一个位置。 - 重复上面的步骤 2,直到所有元素都插入到正确的位置。
以数组 [98,90,34,56,21] 为例,动态排序过程如下:

四、希尔排序
希尔排序(Shell's Sort)又称“缩小增量排序”(Diminishing Increment Sort),是插入排序的一种更高效的改进版本,同时该算法是首次冲破 O(n^2*n*2) 的算法之一。
插入排序的痛点在于不管是否是大部分有序,都会对元素进行比较,如果最小数在数组末尾,想要把它移动到数组的头部是比较费劲的。希尔排序是在数组中采用跳跃式分组,按照某个增量 gap 进行分组,分为若干组,每一组分别进行插入排序。再逐步将增量 gap 缩小,再每一组进行插入排序,循环这个过程,直到增量为 1。
希尔排序基本步骤如下:
- 选择一个增量
gap,一般开始是数组的一半,将数组元素按照间隔为gap分为若干个小组。 - 对每一个小组进行插入排序。
- 将
gap缩小为一半,重新分组,重复步骤 2(直到gap为 1 的时候基本有序,稍微调整一下即可)。
以数组 [98,90,34,56,21,11,43,61] 为例子,排序的动图如下:

五、快速排序
快速排序比较有趣,选择数组的一个数作为基准数,一趟排序,将数组分割成为两部分,一部分均小于/等于基准数,另外一部分大于/等于基准数。然后分别对基准数的左右两部分继续排序,直到序列有序。这体现了分而治之的思想,其中还应用到挖坑填数的策略。
算法的步骤如下:
- 从数组中挑一个元素作为基准数,一半情况下我们选择第一个
nums[i],保存为standardNum,可以理解为nums[i]坑位的数被拎出来了,留下空的坑位。 - 取数组的左边界索引为
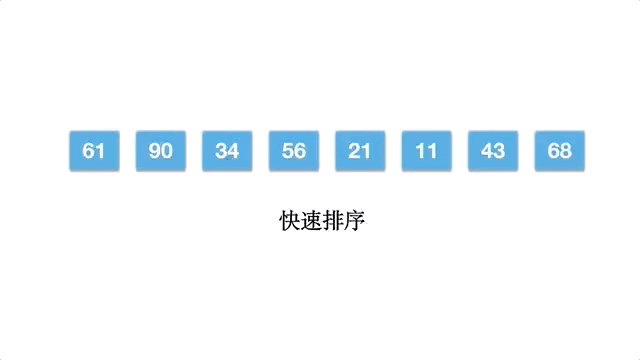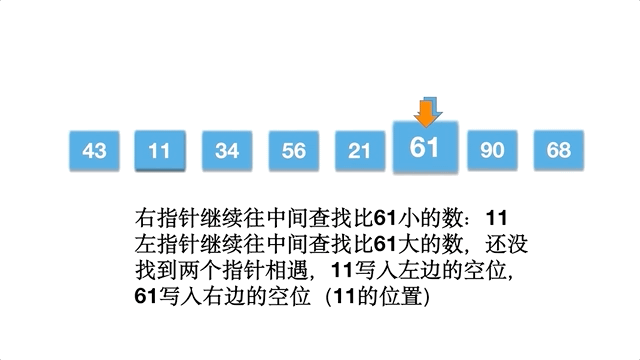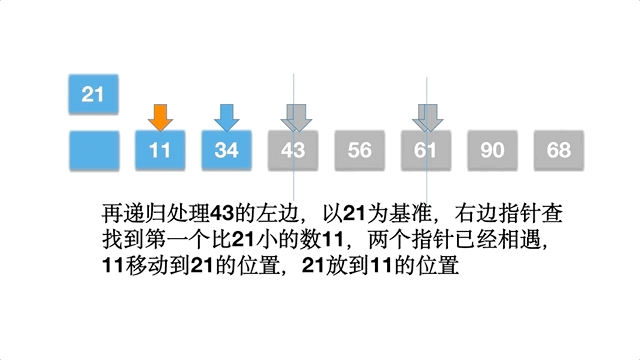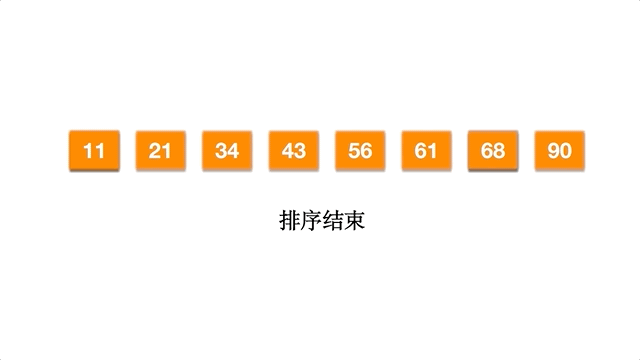
i,右边界索引j,j从右边往左边,寻找到比standardNum小的数,停下来,写到nums[i]的坑位,nums[j]的坑位空出来。i从左边往右边找,寻找比standardNum大的数,停下来,写到nums[j]的坑位,这个时候,num[i]的坑位空出来(前提是i和j不相撞)。 - 上面的
i和j循环步骤 2,直到i和j相撞,将基准值standardNum写到坑位nums[i]中,这时候,standardNum左边的数都小于等于它本身,右边的数都大于等于它本身。 - 分别对 standardNum 左边的子数组和右边的子数组,循环执行前面的 1,2,3,直到不可再分,并且有序。
以数组 [61,90,34,56,21,11,43,68] 为例,动态排序过程如下:
六、归并排序
前面学的快速排序,体现了分治的思想,但是不够典型,而归并排序则是非常典型的分治策略。归并的总体思想是先将数组分割,再分割...分割到一个元素,然后再两两归并排序,做到局部有序,不断地归并,直到数组又被全部合起来。
排序步骤大致如下:
- 将长度为
n的数组分割成为n/2的两个子数组。 - 子数组也不断分割成为更小的子数组,直到不能分割。
- 最小子数组之间开始两两合并,合并之后的结果再合并。合并的时候可以申请一个临时空间,利用两个索引指针比较的方式,将两个子数组的结果合并到临时数组中去。
- 循环 3 步骤,直到合并成为长度为 n 的已经排序的数组。
以数组 [61,90,34,56,21,11,43,68] 为例,每一次都是对数组分成两半,直至不能拆分,再两两合并,合并的时候相当于对有序的两个子数组合并。
动态执行过程如下:

七、计数排序
计数排序,不是基于比较,而是基于计数。
计数排序步骤如下:
- 遍历数组,找出最大值和最小值。
- 根据最大值和最小值,初始化对应的统计元素数量的数组。
- 遍历元素,统计元素个数到新的数组。
- 遍历统计的数组,按照顺序输出排序的数组元素。
假设有几个青少年,他们年龄很接近,分别是 11、9、11、 13、12、14、15、13,现在需要给他们按照年龄排序。首先先遍历一遍,找出最小的 min 和最大的元素 max,创建一个大小为 max - min + 1 的数组,再遍历一次,统计数字个数,写到数组中。
然后再遍历一次统计数组,将每个元素置为前面一个元素加上自身,为什么这样做呢?
为了让统计数组存储的元素值等于相应整数的最终排序位置,这样我们就可以做到稳定排序,比如下面的 15 对应的是 8,也就是 15 在数组中出现的是第 8 个元素,从后面开始遍历,我们就可以保持稳定性。
比如原数组从后往前遍历到 13 的时候, 13 对应的位置是 6,那么此时从后往前遍历到的第一个 13 就是在第 6 个元素位置。后面再遇到 13,就放到第 5 个元素位置,不会打乱它们的相对位置。
动态过程如下:

八、桶排序
桶排序,是指用多个桶存储元素,每个桶有一个存储范围,先将元素按照范围放到各个桶中,每个桶中是一个子数组,然后再对每个子数组进行排序,最后合并子数组,成为最终有序的数组。这其实和计数排序很相似,只不过计数排序每个桶只有一个元素,而且桶的值为元素的个数。
桶排序的具体步骤:
- 遍历数组,查找数组的最大最小值,设置桶的区间(非必需),初始化一定数量的桶,每个桶对应一定的数值区间。
- 遍历数组,将每一个数,放到对应的桶中。
- 对每一个非空的桶进行分别排序(桶内部的排序可以选择 JDK 自带排序)。
- 将桶中的子数组拼接成为最终的排序数组。
以数组 [98,90,34,56,21,11,43,61] 为例,桶排序的动态过程:

先遍历查找出 max 为 98, min 为 11,数组大小为 8,( 98 - 11 )/8 + 1 = 11,桶的个数为 11。先把元素按照区间放进去,对每一个桶分别排序,然后再把桶的元素连起来放在数组中,排序就完成了。
九、堆排序
堆排序,就是利用大顶堆或者小顶堆来设计的排序算法,是一种选择排序。堆是一种完全二叉树:
- 大顶堆:每个节点的数值都大于或者等于其左右孩子节点的数值。
- 小顶堆:每个节点的数值都小于或者等于其左右孩子节点的数值。
我们一般使用数组来对堆结构进行存储,下面我们只说大顶堆(元素按照从小到大排序),假设数组为 nums[],则第 i 个数满足:num[i] >= nums[2i+1] 且 num[i] >= nums[2i+2],第 i 个数在堆上的左节点就是数组中下标索引 2i+1 的元素,其右节点就是数组中下标索引 2i+2 的元素。
排序的思路为:
- 将无序的数组构建出一个大顶堆,也就是上面的元素比下面的元素大。
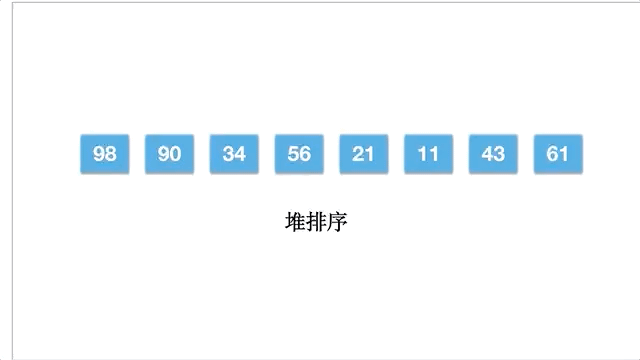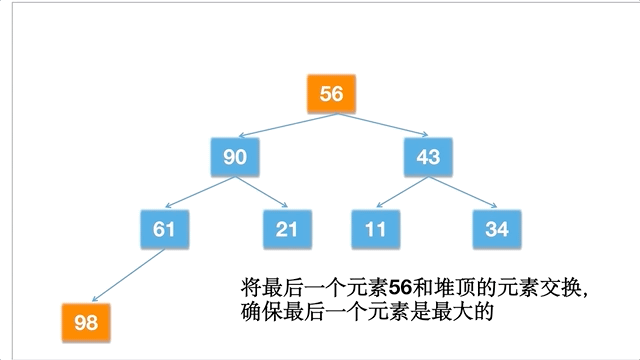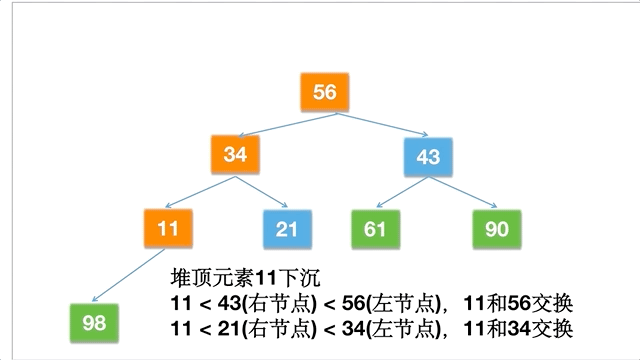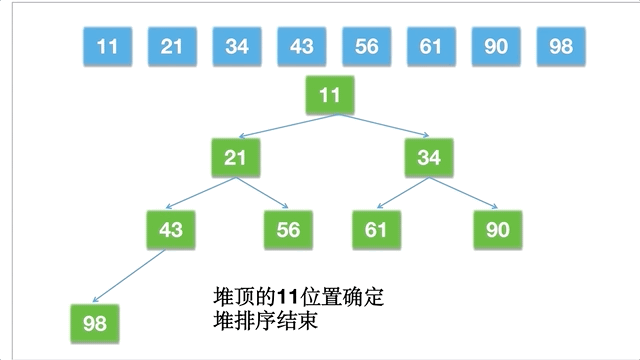
- 将堆顶的元素和堆的最末尾的元素交换,将最大元素下沉到数组的最后面(末端)。
- 重新调整前面的顺序,继续交换堆顶的元素和当前末尾的元素,直到所有元素全部下沉。
倘若一个数组为 [11,21,34,43,56,61,90,98],动态的过程如下:
十、基数排序
基数排序比较特殊,特殊在它只能用在整数(自然数)排序,而且不是基于比较的,其原理是将整数按照位分成不同的数字,按照每个数各位值逐步排序。何为高位,比如 81,1 就是低位, 8 就是高位。 分为高位优先和低位优先,先比较高位就是高位优先,先比较低位就是低位优先。下面我们讲高位优先。
主要的步骤如下:
- 将所有元素统一称为统一数位长度,前面补 0。
- 从最高位开始,依次排序,从最高位到最低位遍历完,数组就是有序的。
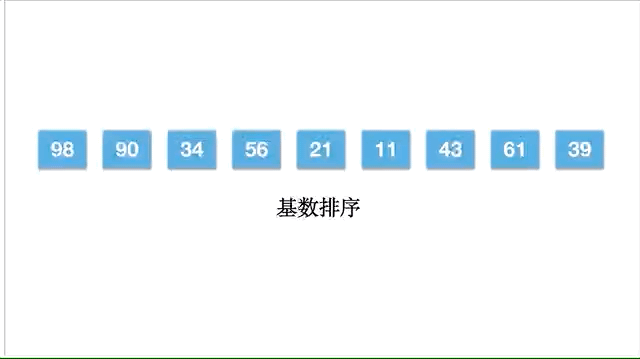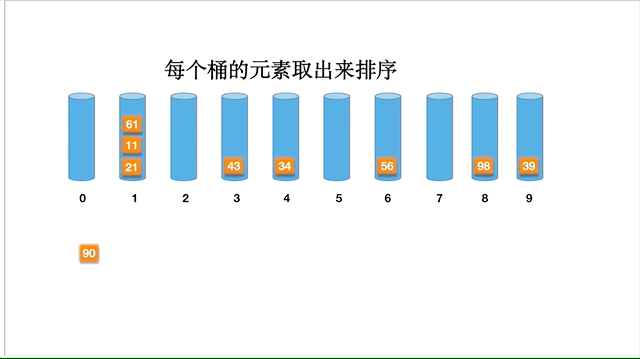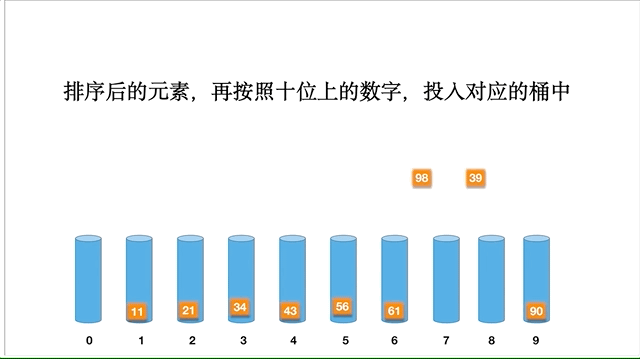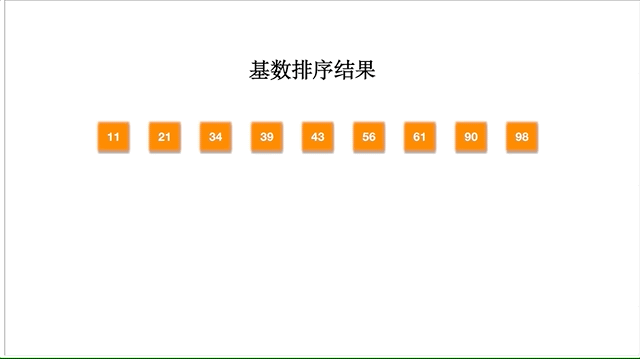
以数组 [98,90,34,56,21,11,43,61,39] 为例,动态的排序过程如下:
十个算法的复杂度以及特点总结一下:
- 冒泡排序:基本最慢,时间复杂度最好为
O(n),最坏为O(n2),平均时间复杂度为O(n2),空间复杂度为O(1),稳定排序算法。 - 选择排序:时间复杂度很稳定,最好最坏或者平均都是
O(n2),空间复杂度为O(1),可以做到稳定排序。 - 插入排序:时间复杂度最好为
O(n),最坏为O(n2),平均时间复杂度为O(n2),空间复杂度为O(1),稳定排序算法。 - 希尔排序:希尔增量下最坏的情况时间复杂度是
O(n2),最好的时间复杂度是O(n)(也就是数组已经有序),平均时间复杂度是O(n3/2),属于不稳定排序。 - 快速排序:时间复杂度最差的情况是
O(n2),平均时间复杂度为O(nlogn),空间复杂度,虽然快排本身没有申请额外的空间,但是递归需要使用栈空间,递归数的深度是log2n,空间复杂度也就是O( log2n),属于不稳定排序。 - 归并排序:排序复杂度为
nlog2n,不存在好坏的情况,但是代价就是需要申请额外的空间,申请空间的大小最大为n,所以空间复杂度为O(n),属于稳定排序。 - 计数排序:时间复杂度为
O(n+k),申请了一个统计数组和一个新数组,空间复杂度为O(n+k),没有所谓最好最坏,都是一个复杂度,一般适用于小范围整数排序,属于稳定排序。 - 桶排序:最好情况时间复杂度
O(n),最坏情况时间复杂度为O(n2),平均的时间复杂度为O(n+k)。由于在中间过程中会申请桶的数量m,所以空间复杂度为O(n+m),稳定性决定于桶内部排序。 - 堆排序:时间复杂度为
O(nlogn),没有申请额外的空间,空间复杂度为O(1),属于不稳定排序。 - 基数排序:时间复杂度为
O(d(2n))。一般只使用于整数排序,不适合小数或者文字排序。由于需要申请桶的空间,假设有k个桶(上面是10个桶),则空间复杂度为O(n+k),一般k较小,所以近似为O(n),属于稳定排序。
每一种排序,都有其优缺点,我们应该根据场景选择合适的排序算法。
如果你觉得有用的话就给这篇文章一个赞吧!