数据集的结构:特征值+目标值 (有些可以没有目标值)
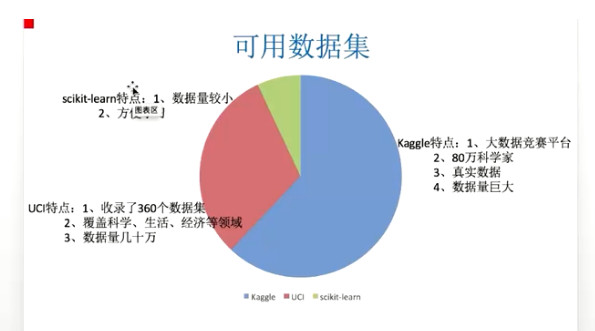
数据集:uci kaggle
数据处理工具:pandas sklearn
缺失值 重复值 不需要处理

转换器是一类实现了特征工程的API:


估计器是一类实现了算法的API:


测试代码:
from sklearn.preprocessing import StandardScaler # 转换器以及估计器 s = StandardScaler() data = s.fit_transform([[1, 2, 3], [4, 5, 6]]) print(data) ss = StandardScaler() print(ss.fit([[1, 2, 3], [4, 5, 6]])) print(ss.transform([[1, 2, 3], [4, 5, 6]])) print(ss.fit([[2, 3, 4], [4, 5, 7]])) print(ss.transform([[1, 2, 3], [4, 5, 6]]))
运行结果:
