python字典底层实现原理
一、python字典及其特征
字典是Python的一种可变、无序容器数据结构,它的元素以键值对的形式存在,键值唯一,它的特点搜索速度很快:数据量增加10000倍,搜索时间增加不到2倍;当数据量很大的时候,字典的搜索速度要比列表快成百上千倍。
二、哈希表
Python字典的底层实现是哈希表。什么是哈希表,简单来说就是一张带索引和存储空间的表,对于任意可哈希对象,通过哈希索引的计算公式:hash(hashable)%k(对可哈希对象进行哈希计算,然后对结果进行取余运算),可将该对象映射为0到k-1之间的某个表索引,然后在该索引所对应的空间进行变量的存储/读取等操。
哈希函数hash()传递的是一个不可变数据类型,返回一个整数值。有以下一个字段:
info = {
'name': 'Jack',
'age': 20,
'gender': 'male'
}
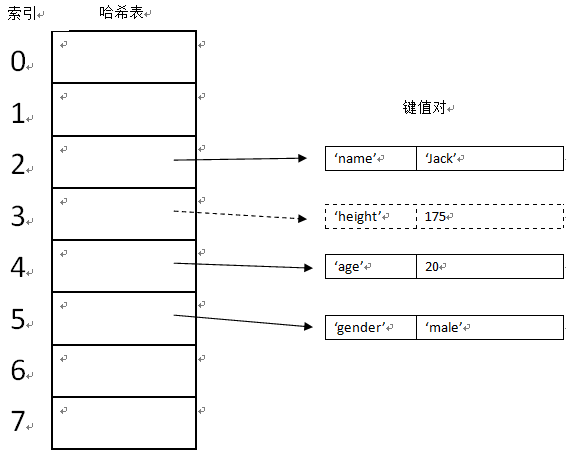
python在底层是这样存储的:

三、Python字典如何运用哈希表
通过描述插入,查询,删除,扩容,哈希碰撞这几个过程来解释这一切。
1、插入
对键进行哈希和取余运算,得到一个哈希表的索引,如果该索引所对应的表地址空间为空,将键值对存入该地址空间。
2、更新
对键进行哈希和取余运算,得到一个哈希表的索引,如果该索引所对应的地址空间中健与要更新的健一致,那么就更新该健所对应的值。
3、查询
对要查找的健进行哈希和取余运算,得到一个哈希表的索引,如果该索引所对应的地址空间中健与要查询的健一致,那么就将该键值对取出来。
4、扩容
字典初始化的时候,会对应初始化一个有k个空间的表,等空间不够用的时候,系统就会自动扩容,这时候会对已经存在的键值对重新进行哈希取余运算(重新进行插入操作)保存到其它位置。
5、碰撞
有时候对于不同的键,经过哈希取余运算之后,得到的索引值一样,这时候怎么办?这时采用公开寻址的方式,运用固定的模式将键值对插入到其它的地址空间,比如线性寻址:如果第i个位置已经被使用,我们就看看第i+1个,第i+2个,第i+3个有没有被使用…直到找到一个空间或者对空间进行扩容。
比如:我们想存储 {’height‘:175}这个键值对,经过哈希和取余运算之后,我们发现,其对应的索引值是2,但是2所指向的空间已经被’name‘占用了,这就是碰撞。怎么办呢?我们看看0+1对应的所以有没有被占用,如果没有,我们就把’height‘放在索引1所对应的地址空间中。取的时候,也按照同样的规则,进行探查。
四、字典比列表查找高效
假设有一栋楼,住着1000人,你有个好朋友小王,住在这栋楼,你有急事要找他,你不知道他住几楼几号房间。这时你怎么办?你找到门卫处,向门卫说,我找小王。
列表查找:
门卫说:我们这里每一个房间住着谁都有记录,这是记录本,你自己找吧!这个记录本有1000条记录,你从第一条开始翻,一条一条往下看,终于在第177条记录的时候找到了你的朋友小王所在的房间号。
字典查找:
门卫说: 我这里有一个公式,只要你记得你的朋友的名字,就能很快的找到你朋友在几号房间。
这个公式是:hash(姓名)%1001
对你的朋友小王的名字进行hash运算,然后对得到的结果对1001进行取余操作,得到的数字就是你的朋友小王的房间号了,经过计算,你发现hash(‘小王’)%1001=177。
总结:
列表查找是按顺序一个一个遍历,当列表越大,查找所用的时间就越久。
字典是通过键值直接计算得到对应的地址空间,查找一步到位。
五、字典的无序
字典中键的顺序取决于添加顺序。无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。这个过程中可能会发生新的散列冲突,导致新散列表中键的次序变化。
六、字典的不足
虽然字典存取速度快,但字典占用的存储空间要比其他数据类型大。我们可以大致的看一下几种数据类型所占的存储空间:
import sys
print(sys.getsizeof('')) # 空字符串
# 49
print(sys.getsizeof([])) # 空列表
# 56
print(sys.getsizeof(())) # 空元祖
# 40
print(sys.getsizeof(dict())) # 空字典
# 232
同样是创建一个对象,创建字典对象比创建其他对象要大的多。
使用字典这种数据类型是用空间换时间。