kafka 生产者
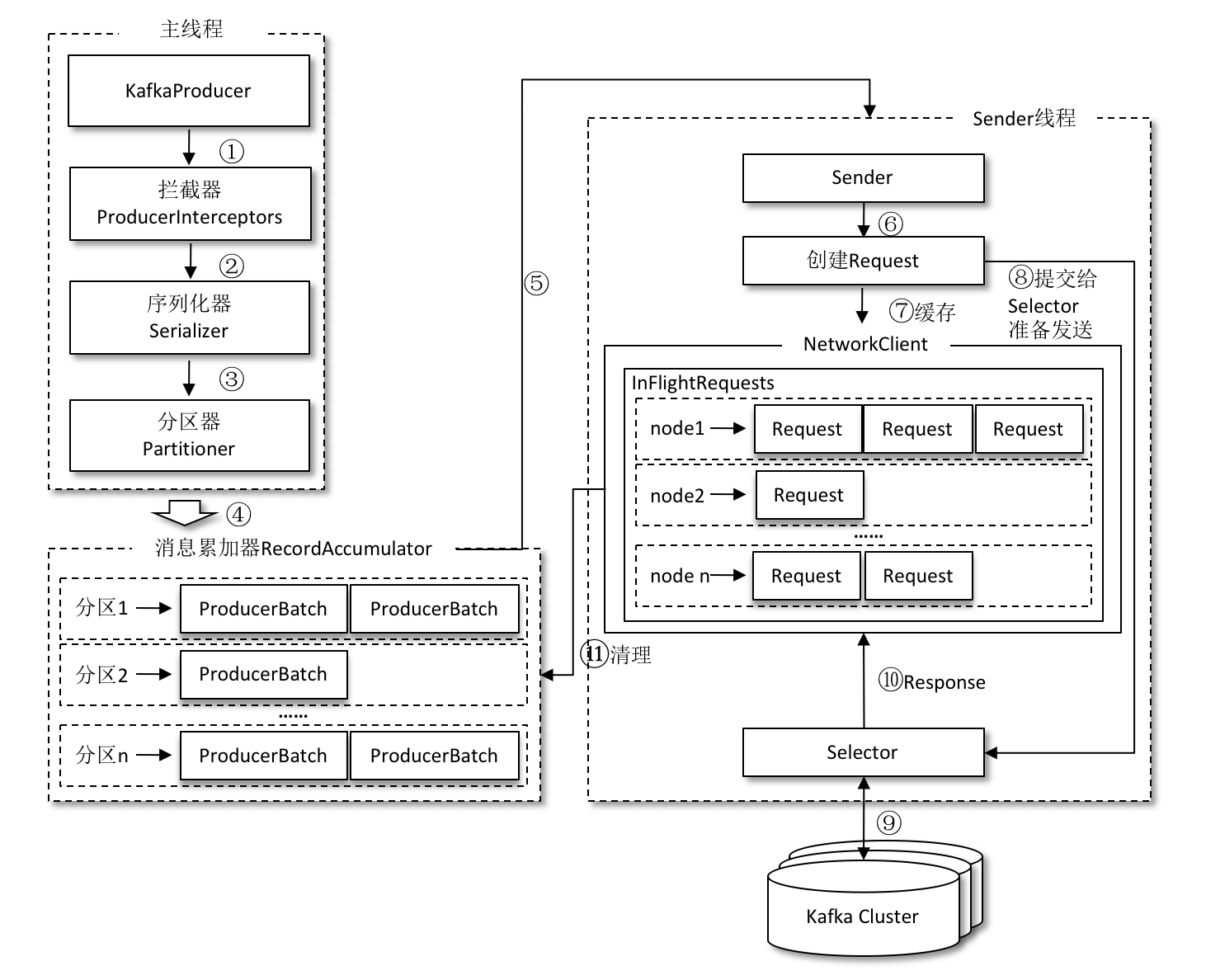
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程(发送线程)。
-
主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。
-
Sender 线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
生产者发送消息的主要步骤(主线程):
- 创建一个ProducerRecord对象:ProducerRecord对象需要包含目标主题和要发送的内容。我们还可以指定键或分区。
- 序列化:在发送ProducerRecord对象时,生产者要先把键和值对象序列化成字节数组。
- 分区器:如果之前在ProducerRecord对象里指定了分区,那么分区器就不会再做任何事情,直接把指定的分区返回。如果没有指定分区,那么分区器会根据ProducerRecord对象的键来选择一个分区。选好分区以后,生产者就知道该往哪个主题和分区发送这条记录了。
- 添加批次里,发送给broker:这个批次里的所有消息会被发送到相同的主题和分区上。有一个独立的线程负责把这些记录批次发送到相应的broker上。
RecordAccumulator
主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
RecordAccumulator 缓存的大小可以通过生产者客户端参数buffer.memory 配置,默认值为 33554432B,即 32MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候KafkaProducer的send()方法调用要么被阻塞,要么抛出异常,这个取决于参数max.block.ms的配置,此参数的默认值为60000,即60秒。
Sender 线程
Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区,Deque<ProducerBatch>>的保存形式转变成<Node,List<ProducerBatch>的形式,其中Node表示Kafka集群的broker节点。在转换成<Node,List<ProducerBatch>>的形式之后,Sender 还会进一步封装成<Node,Request>的形式,这样就可以将Request请求发往各个Node了。
请求在从Sender线程发往Kafka之前还会保存到InFlightRequests中,InFlightRequests保存对象的具体形式为 Map<NodeId,Deque<Request>>,它的主要作用是缓存了已经发出去但还没有收到响应的请求(NodeId 是一个String 类型,表示节点的 id 编号)
生产者发送消息有3种方式:
第一种:发送并忘记(fire-and-forget)我们把消息发送给服务器,但并不关心它是否正常到达。
第二种:同步发送使用send()方法发送消息,它会返回一个Future对象,调用get()方法进行等待,就可以知道消息是否发送成功。
第三种:异步发送我们调用send()方法,并指定一个回调函数,服务器在返回响应时调用该函数。
生产者配置参数:
-
acks:
acks参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。
acks = 0 :生产者在成功写入消息之前不会等待任何来自服务器的响应。也就是说,如果当中出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。
acks = 1:只要集群的首领节点收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法到达首领节点(比如首领节点崩溃,新的首领还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新首领,消息还是会丢失。
acks = all:只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
-
buffer.memory:
该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候,send()方法调用要么被阻塞,要么抛出异常,取决于如何设置block.on.buffer.full参数(在0.9.0.0版本里被替换成了max.block.ms,表示在抛出异常之前可以阻塞一段时间)。
-
compression.type:
默认情况下,消息发送时不会被压缩。该参数可以设置为snappy、gzip或lz4,它指定了消息被发送给broker之前使用哪一种压缩算法进行压缩。
-
retries:
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领)。在这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms,不过可以通过retry.backoff.ms参数来改变这个时间间隔。
-
batch.size:
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算(而不是消息个数)。
-
linger.ms:
该参数指定了生产者在发送批次之前等待更多消息加入批次的时间。KafkaProducer会在批次填满或linger.ms达到上限时把批次发送出去。
-
client.id:
该参数可以是任意的字符串,服务器会用它来识别消息的来源,还可以用在日志和配额指标里。
-
max.in.flight.requests.per.connection:
该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为1可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。
-
timeout.ms、request.timeout.ms和metadata.fetch.timeout.ms
request.timeout.ms指定了生产者在发送数据时等待服务器返回响应的时间。
timeout.ms指定了broker等待同步副本返回消息确认的时间,与asks的配置相匹配——如果在指定时间内没有收到同步副本的确认,那么broker就会返回一个错误。
metadata. fetch.timeout.ms指定了生产者在获取元数据(比如目标分区的首领是谁)时等待服务器返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误(抛出异常或执行回调)。
-
max.block.ms
该参数指定了在调用send()方法或使用partitionsFor()方法获取元数据时生产者的阻塞时间
-
max.request.size:
该参数用于控制生产者发送的请求大小。它可以指能发送的单个消息的最大值,也可以指单个请求里所有消息总的大小。
拦截器:
可以根据某个规则过滤不符合要求的消息、修改消息的内容等。
序列化器:
在上图可以看到,创建一个生产者对象必须指定序列化器。Kafka还提供了整型和字节数组序列化器,我们也可以自定义序列化器。
分区
分区的好处:
- (1) 便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一
块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
- (2) 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
ProducerRecord
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
.......
}
roducerRecord对象包含了目标主题、键和值。Kafka的消息是一个个键值对,ProducerRecord对象可以只包含目标主题和值,键可以设置为默认的null,不过大多数应用程序会用到键。
键有两个用途:
- 可以作为消息的附加信息,
- 可以用来决定消息该被写到主题的哪个分区。
当键值为null时,并且使用了默认的分区器,那么记录将被随机地发送到主题内各个可用的分区上。分区器使用轮询(Round Robin)算法将消息均衡地分布到各个分区上;
当键值不为空时,并且使用了默认的分区器,那么Kafka会对键进行散列;
自定义分区器
实现:org.apache.kafka.clients.producer.Partitioner 接口
提高生产者的吞吐量:
• batch.size:批次大小,默认16k
• linger.ms:等待时间,修改为5-100ms
• compression.type:压缩snappy
• RecordAccumulator:缓冲区大小,修改为64m