为什么使用kafka
多个生产者
Kafka可以无缝地支持多个生产者,不管客户端在使用单个主题还是多个主题。所以它很适合用来从多个前端系统收集数据,并以统一的格式对外提供数据。
多个消费者
支持多个生产者外,Kafka也支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。
基于磁盘的数据存储
Kafka不仅支持多个消费者,还允许消费者非实时地读取消息,这要归功于Kafka的数据保留特性。消息被提交到磁盘,根据设置的保留规则进行保存。
伸缩性
Broker可以随着数据量不断增长,扩展到上百个。对在线集群进行扩展丝毫不影响整体系统的可用性。也就是说,一个包含多个broker的集群,即使个别broker失效,仍然可以持续地为客户提供服务。
高性能
上面提到的所有特性,让Kafka成为了一个高性能的发布与订阅消息系统。通过横向扩展生产者、消费者和broker, Kafka可以轻松处理巨大的消息流。
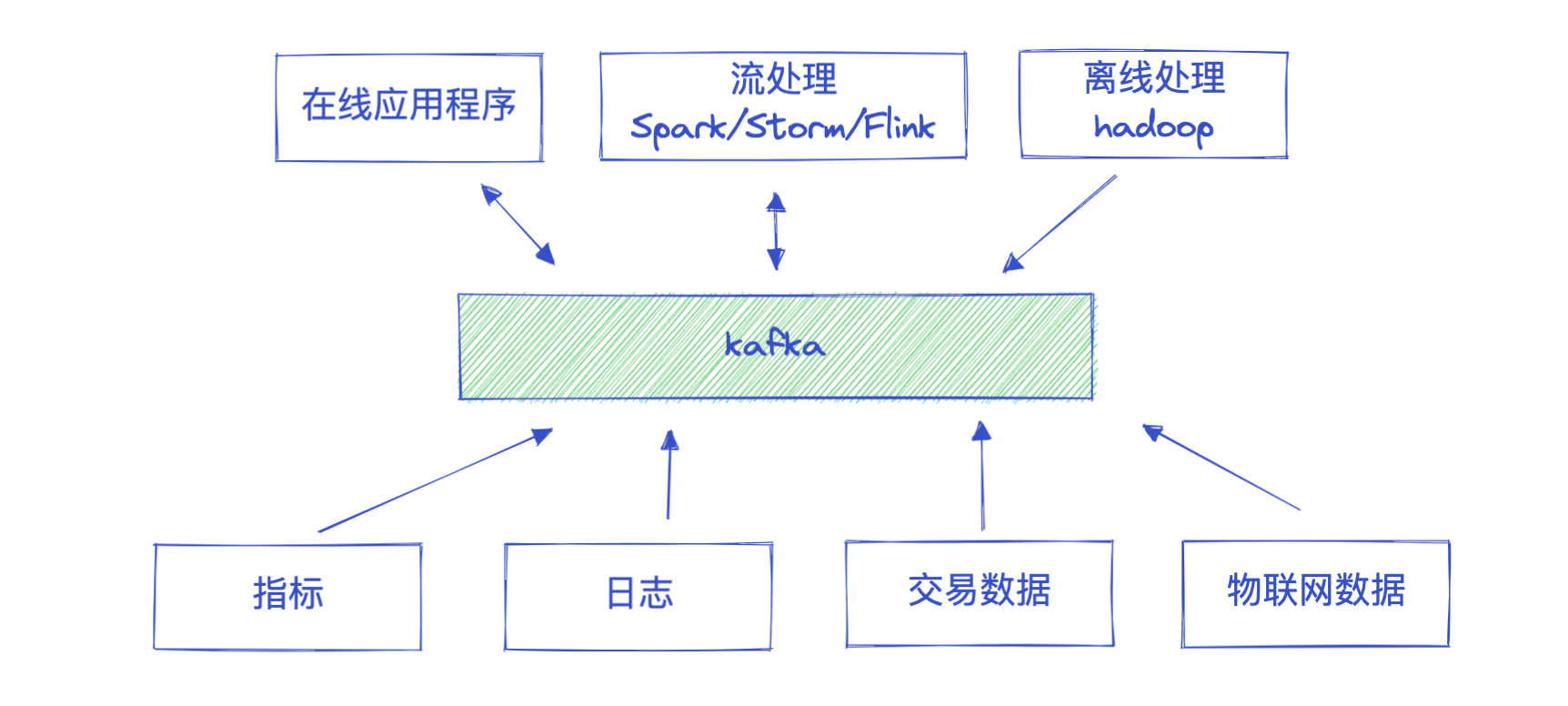
使用场景:
- 活动跟踪:Kafka最初的使用场景是跟踪用户的活动。网站用户与前端应用程序发生交互,前端应用程序生成用户活动相关的消息。这些消息可以是一些静态的信息,比如页面访问次数和点击量,也可以是一些复杂的操作,比如添加用户资料。这些消息被发布到一个或多个主题上,由后端应用程序负责读取。这样,我们就可以生成报告,为机器学习系统提供数据,更新搜索结果,或者实现其他更多的功能。
- 消息传递:Kafka的另一个基本用途是传递消息。
- 度量指标:Kafka也可以用于收集应用程序和系统度量指标以及日志。Kafka支持多个生产者的特性在这个时候就可以派上用场。应用程序定期把度量指标发布到Kafka主题上,监控系统或告警系统读取这些消息。Kafka也可以用在像Hadoop这样的离线系统上,进行较长时间片段的数据分析,比如年度增长走势预测。
- 日志记录:日志消息也可以被发布到Kafka主题上,然后被路由到专门的日志搜索系统(比如Elasticsearch)或安全分析应用程序。更改目标系统(比如日志存储系统)不会影响到前端应用或聚合方法,这是Kafka的另一个优点。
- 提交日志:我们可以把数据库的更新发布到Kafka上,应用程序通过监控事件流来接收数据库的实时更新。这种变更日志流也可以用于把数据库的更新复制到远程系统上,或者合并多个应用程序的更新到一个单独的数据库视图上。数据持久化为变更日志提供了缓冲区,也就是说,如果消费者应用程序发生故障,可以通过重放这些日志来恢复系统状态。
- 流处理:流处理是又一个能提供多种类型应用程序的领域。可以说,它们提供的功能与Hadoop里的map和reduce有点类似,只不过它们操作的是实时数据流,而Hadoop则处理更长时间片段的数据,可能是几个小时或者几天,Hadoop会对这些数据进行批处理。通过使用流式处理框架,用户可以编写小型应用程序来操作Kafka消息,比如计算度量指标,为其他应用程序有效地处理消息分区,或者对来自多个数据源的消息进行转换。