修改hostname(可选)
通过下面命令查看hostname信息
hostnamectl
通过下面命令修改hostname
hostnamectl set-hostname gy01
如图所示

下面我们需要修改一下hostname,我们下查看下我们的ip地址
ip addr
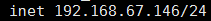
该IP可以去/etc/sysconfig/network-scripts/ifcfg-enp0s3去修改,enp0s3可以在ip addr找到,然后我们修改这个文件

现在我们去修改下hosts文件

现在我们重启reboot
重启后可以看到我们的hostname已经修改

ssh免登陆
这里简单介绍下ssh的原理,ssh(Secure Shell)顾名思义就是安全的shell,因为在机机间进行访问操作是要得到授权的,那这个授权其实就是对方给了你一把钥匙,所以这就相当于怎么把这把钥匙给对方呢。首先通过ssh-keygen -t rsa生成一对公钥和私钥。公钥加密的字符只能由私钥来解密,因此公钥只能加密,私钥只用来解密。好了假设我们现在有两台机器A和B,机器A想拿到机器B的“钥匙”,那么首先机器A将自己的公钥发送给机器B,机器A首先请求(带有用户和hostname)连接机器B,那么机器B通过用户和hostname去authorized_keys中去查找是否有机器A的公钥,如果有那么B就会用这个公钥来机密一个字符串并将加密后的字符串返给A,A这个时候使用私钥来解密这个字符串并将解密后的字符串再发给机器B,机器B用这个解密后的字符串和原字符串对比,如果一致那么久说明A是授权机器,这次连接后续的操作涉及密码输入的都无需再输入了。如果不一致那么不好意思需要输入密码的操作就老老实实的一个个输入吧。

因为我们这是伪分布的场景,那么我们只要保证当前的hostname和后面需要启动的hdfs节点的hostname一致就达到了ssh免密码的目的了。
cd ~/
ssh-keygen -t rsa
cd .ssh
cp id_rsa.pub authorized_keys
more authorized_keys
从最后的root@gy01可以看到我们生成了用户+hostname对应的公钥了。
配置hadoop
我们现在/home目录下上传我们需要使用的软件包

安装jdk
rpm -ivh jdk-8u91-linux-x64.rpm
配置hadoop
先解压hadoop
tar -zxvf hadoop-2.7.2.tar.gz
cd /home/hadoop-2.7.2/etc/hadoop
- hadoop-env.sh
JAVA_HOME=/usr/bin/java/jdk1.8.0_151
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://gy01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-2.7.2/tmp</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>gy01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
格式化hdfs
cd $HADOOP_HOME/bin
./hdfs namenode -format
启动hdfs和yarn管理器
cd $HADOOP_HOME/sbin
./start-all.sh
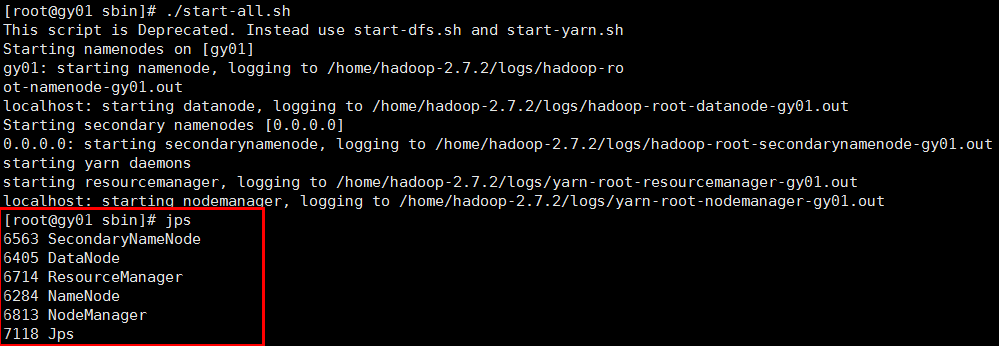
这里启动会报localhost ,你可以通过屏蔽
ssh -o StrictHostKeyChecking=no localhost
测试
这里我们使用hadoop shell可以做一些小测试
我们在/home下创建个文件
echo something > test
hadoop fs -mkdir hdfs://gy01:9000/repository
hadoop fs -put test hdfs://gy01:9000/repository/test
查看我们在hdfs上传的文件
hadoop fs -ls hdfs://gy01:9000/repository

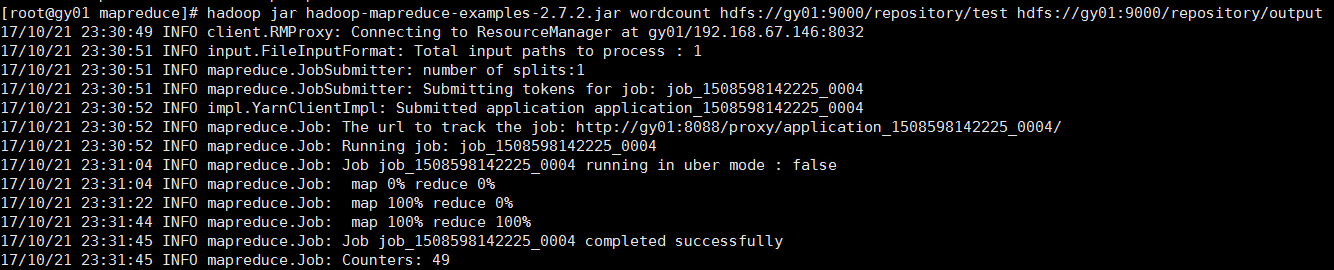
最后一定要来一个helloworld