1. Zeppelin下载及安装
1.1 安装环境
- Cent os 7.5
- Hadoop 3.2
- Hive-3.1.2
- Scala
- Spark-3.0.0-bin-hadoop3.2
- Flink 1.13.2
- Zeppelin 0.9.0
1.2 Zeppelin下载
Zeppelin 安装包下载地址
http://zeppelin.apache.org/download.html
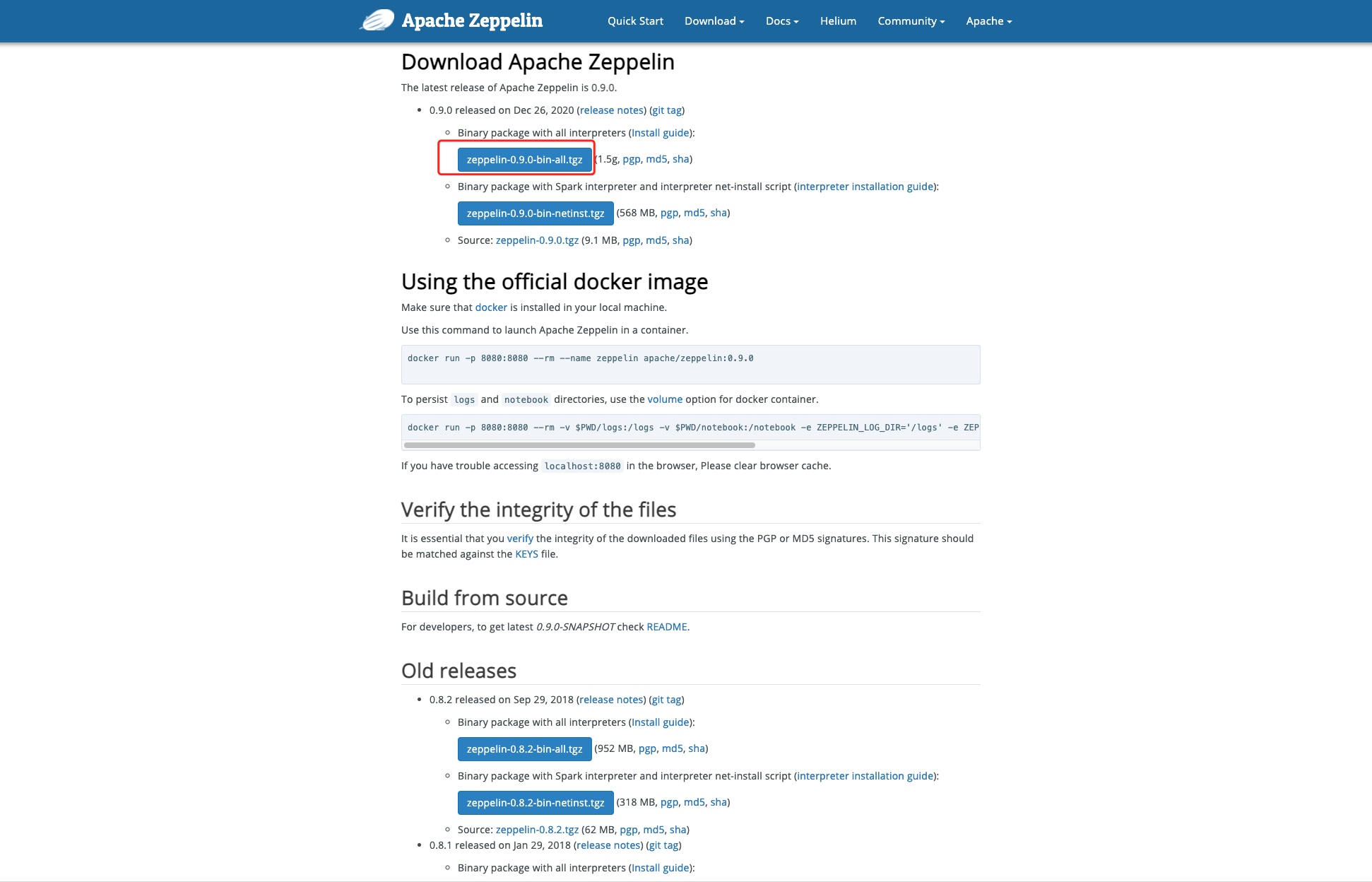
1.3 上传并解压
# 解压zeppelin安装包
tar -zxvf zeppelin-0.9.0-bin-all.tgz -C /data/soft/
注意:如果是正式生产环境,建议部署到/usr/local/目录下。本文以学习为主,部署在/data/Soft目录下。
1.4 修改zeppelin配置文件
- 自定义zeppelin访问端口
修改zeppelin-site.xml文件。由于zeppelin默认的端口号为8080(与Spark默认端口冲突),因此有必要修改zeppelin的默认端口。此处修改为8000。
<property>
<name>zeppelin.server.addr</name>
<value>192.168.21.102</value>
<description>Server binding address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>8000</value>
<description>Server port.</description>
</property>
- 配置zeppelin-env.sh
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoop
export SPARK_MASTER_IP=192.168.21.102
export SPARK_LOCAL_IP=192.168.21.102
1.5 启动
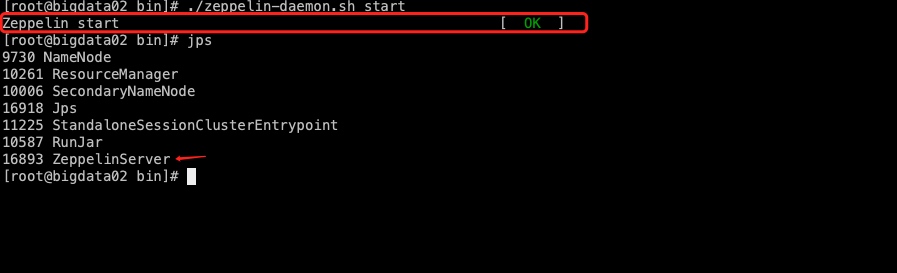
在ZEPPELIN_HOME目录下,进入bin目录下,执行启动命名
./zeppelin-daemon.sh start
如果显示结果如下图,则表示启动成功。
1.6 访问zeppelin Web页面。
zeppelin启动完成后,可使用浏览器访问http://ip:端口,即可看到zeppelin的web界面。
ip和端口与zeppelin-site.xml中配置保持一致。

此处显示的登录用户为admin,而并非默认的annoymous,是因为博主已配置shiro相关内容。默认不配置shiro,无须登录,显示账户为annoymous.
1.7 zeppelin 权限配置
zeppelin默认运行匿名用户访问,即没有用户权限相关要求。如果想实现权限控制,则需要修改shiro配置文件。(有些博主基于0.8.0可能还需要配置修改zeppelin-site.xml中相关内容,在此一并都贴出来)。
修改 zeppelin-site.xml
<property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
<description>Anonymous user allowed by default</description>
</property>
拷贝conf目录下的shiro.ini.template,改为shiro.ini,修改shiro.ini中的内容
cp shiro.ini.template shiro.ini
使用vim工具修改的内容如下
[users]
# List of users with their password allowed to access Zeppelin.
# To use a different strategy (LDAP / Database / ...) check the shiro doc at http://shiro.apache.org/configuration.html#Configuration-INISections
# To enable admin user, uncomment the following line and set an appropriate password.
admin = admin, admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
注意:逗号前面是用户名,逗号后面是登录密码
2. 配置Hive解释器
2.1 前提条件(启动HiverServer2)
要在zeppelin中使用Hive,必须启动hiverserver2服务 以后台方式启动hiveserver2
nohup hive --service hiveserver2 &
2.2 修改配置文件
复制hive-site.xml到zeppline中
cp /data/soft/hive-3.1.2/conf/hive-site.xml /data/soft/zeppelin-0.9.0-bin-all/conf
2.3 配置Hive解释器
新建一个继承jdbc的解释器,命名为hive,如下图所示

| 属性名称 | 属性值 |
|---|---|
| default.url | jdbc:hive2://192.168.21.102:10000 |
| default.driver | org.apache.hive.jdbc.HiveDriver |
属性配置完成够,将以下依赖添加到hive解释器依赖库中。
| Artifate | Exclude |
|---|---|
| org.apache.hive:hive-jdbc:3.1.2 | |
| org.apache.hadoop:hadoop-common:3.2.0 | |
| mysql:mysql-connector-java:5.1.38 |
测试Hive解释器
新建笔记
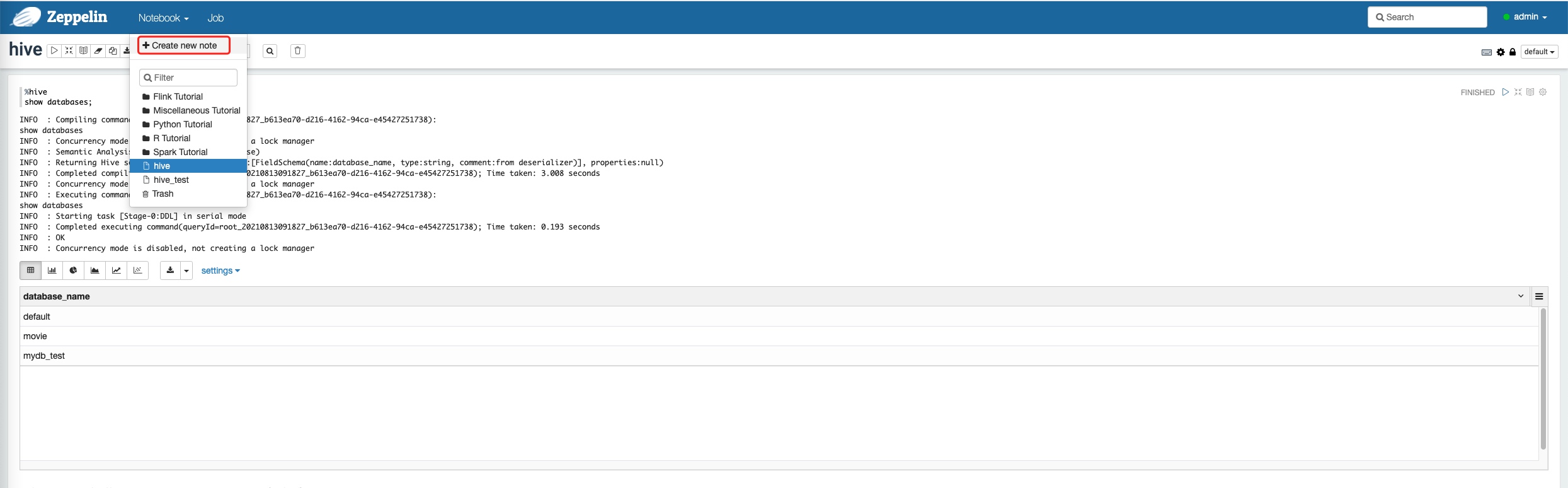
在笔记中输入以下测试笔记
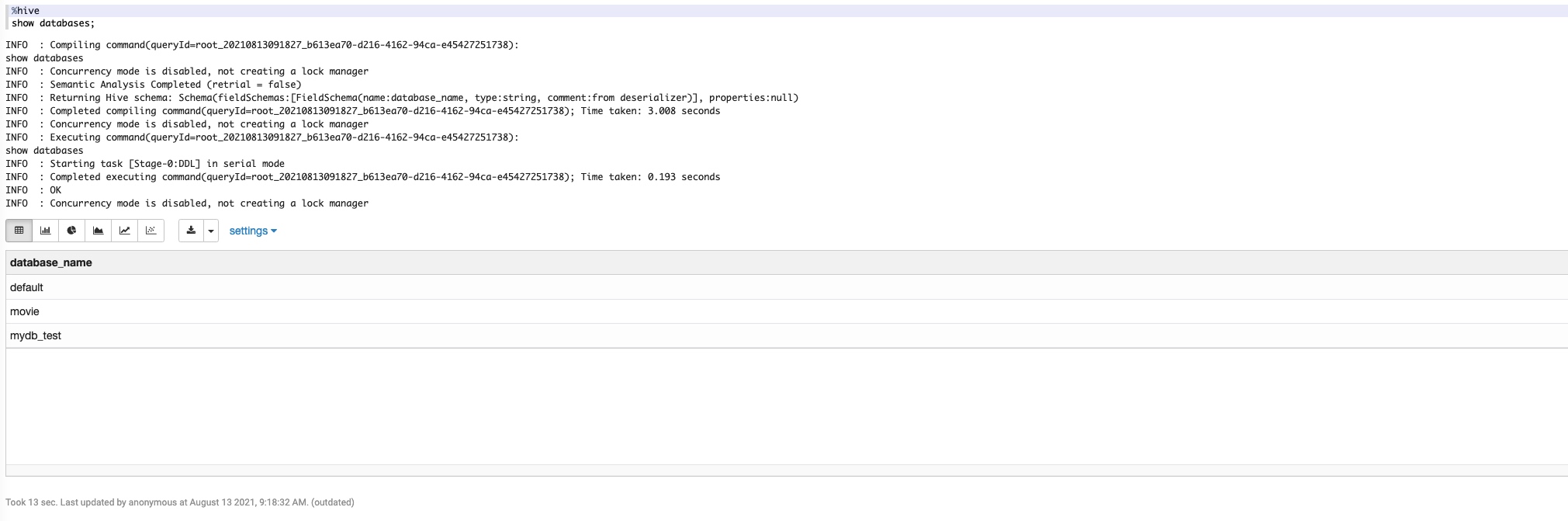
%hive
show databases;
3. 配置Spark解释器
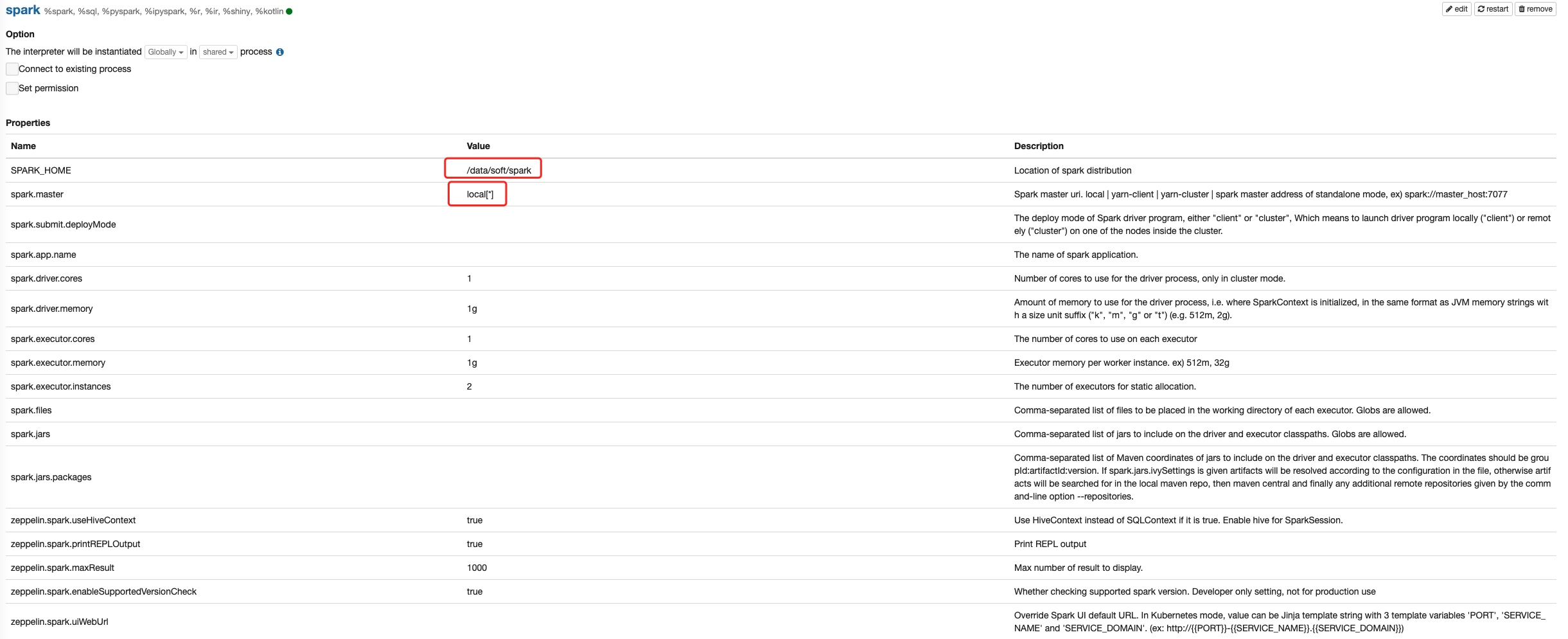
Zeppelin默认的spark解释器包括%spark , %sql , %dep , %pyspark , %ipyspark , %r等子解释器,在实际应用中根据spark集群的参数修改具体的属性 进入解释器配置界面,默认为local[*],Spark采用何种运行模式,参数配置信息如下。
local模式:使用local[*],[]中为线程数,*代表线程数与计算机的CPU核心数一致。
standalone模式: 使用spark://master:7077
yarn模式:使用yarn-client或yarn-cluster
mesos模式:使用mesos://zk://zk1:2181,zk2:2182,zk3:2181/mesos或mesos://host:5050
测试
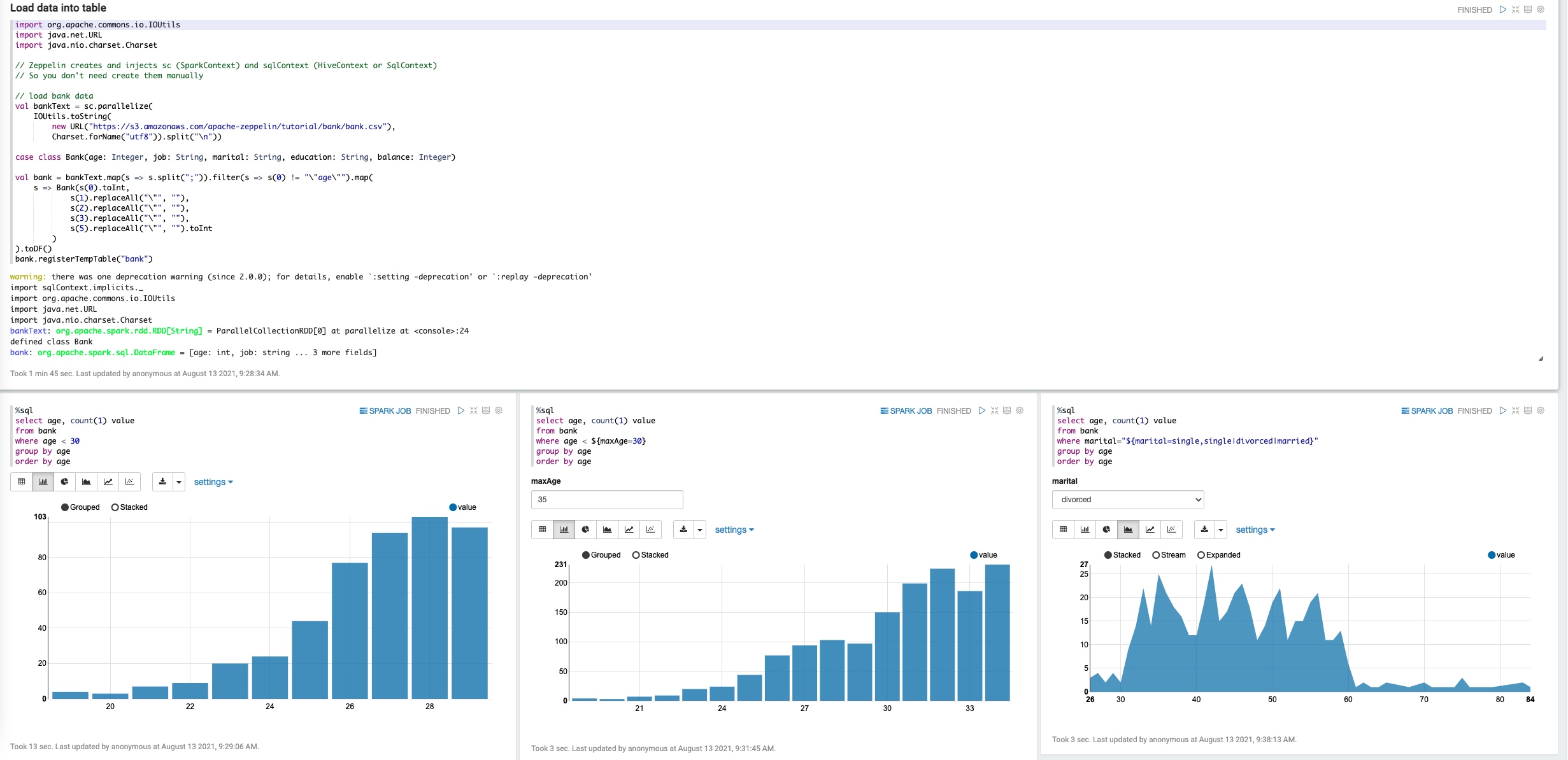
运行Zeppelin自带的Basic Feature(Spark)案例。

import org.apache.commons.io.IOUtils
import java.net.URL
import java.nio.charset.Charset
// Zeppelin creates and injects sc (SparkContext) and sqlContext (HiveContext or SqlContext)
// So you don't need create them manually
// load bank data
val bankText = sc.parallelize(
IOUtils.toString(
new URL("https://s3.amazonaws.com/apache-zeppelin/tutorial/bank/bank.csv"),
Charset.forName("utf8")).split("
"))
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != ""age"").map(
s => Bank(s(0).toInt,
s(1).replaceAll(""", ""),
s(2).replaceAll(""", ""),
s(3).replaceAll(""", ""),
s(5).replaceAll(""", "").toInt
)
).toDF()
bank.registerTempTable("bank")
4. 配置Flink解释器
4.1 准备Flink环境
配置Flink集群。并启动Flink服务。
# $FLINK_HOME/bin
cd /data/soft/flink-1.12.5/bin
# 启动flink集群
./start-cluster.sh
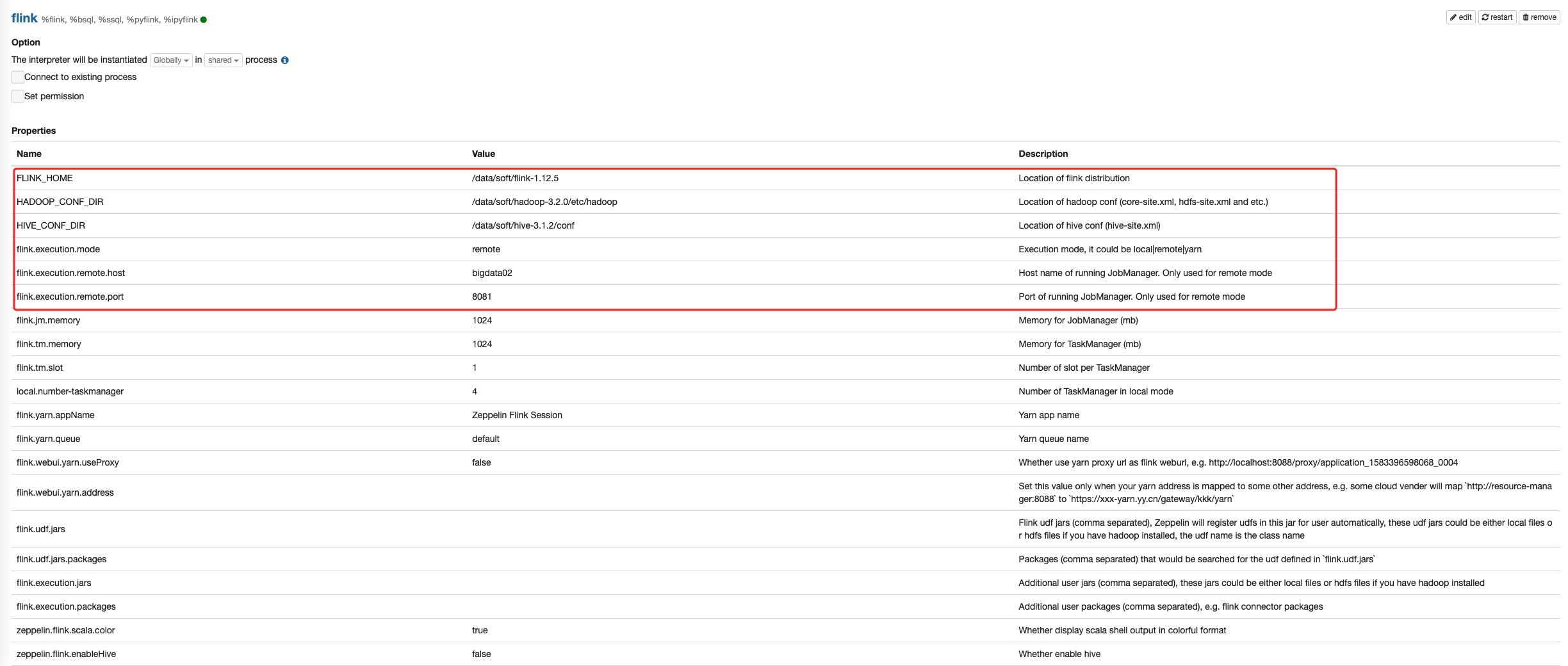
4.2 Zeppelin中配置Flink集群
| 参数名称 | 参数值 | 参数含义 |
|---|---|---|
| FLINK_HOME | Flink集群目录 | |
| HADOOP_CONF_DIR | Hadoop配置文件目录 | |
| HIVE_CONF_DIR | HIVE配置文件目录 | |
| Flink.execution.mode | Flink执行模式,可以选择本地、远程和yarn | |
| Flink.execution.remote.host | 远程模式主机host,仅适用于remote模式 | |
| Flink.execution.remote.port | 8081 | 执行JobManager端口,仅适用于remote模式 |
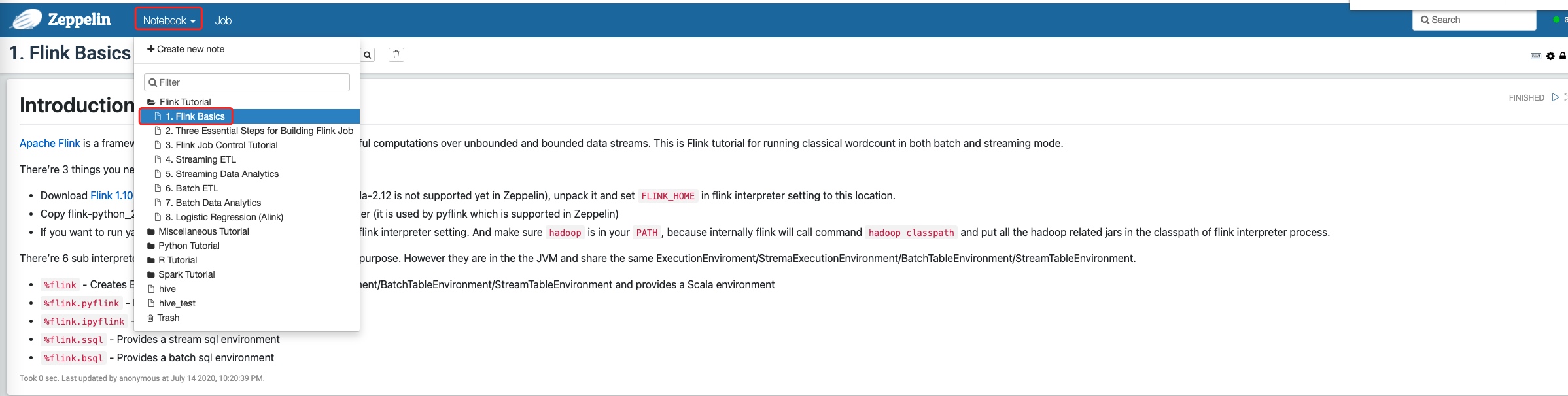
4.3 测试Flink解释器
选择Notebook -->Flink Basics文件夹 -->Flink Basics笔记。
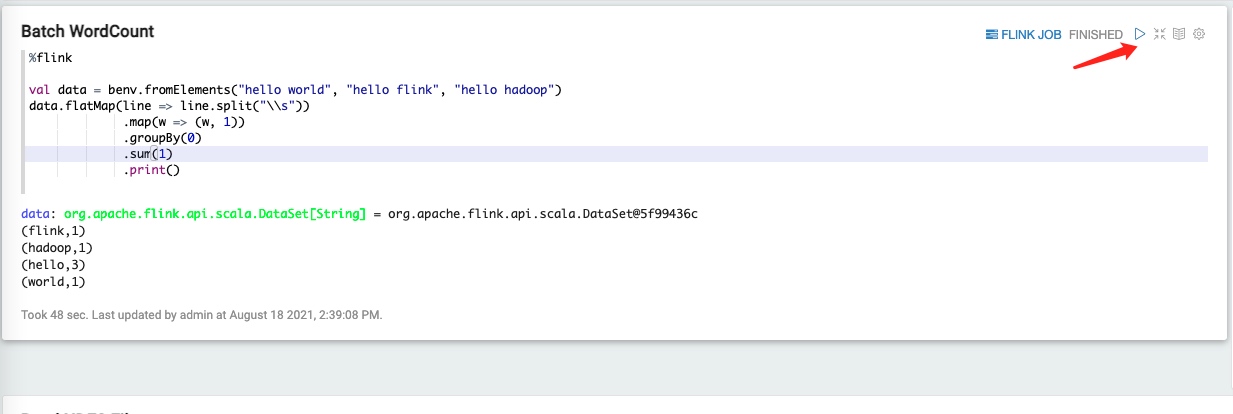
执行第一个Batch WordCount任务。点击运行符号,或输入shift+enter执行任务。
可以在Flink Web UI中看到提交过来的Job和处理的详情

随后可以看到任务已执行完毕,并在笔记界面看到输出结果展示。
Flink Web UI 显示任务已执行完毕。

笔记界面已显示执行结果。
