一、概述
最近数据库频繁不定时的报出一些耗时长的SQL,甚至SQL执行时间过长,导致连接断开现象。下面是一些排查思路。
二、查询日志的大小,日志组情况
SELECT L.GROUP#, LF.MEMBER, L.ARCHIVED, L.BYTES / 1024 / 1024 "SIZE(M)", L.MEMBERS FROM V$LOG L, V$LOGFILE LF WHERE L.GROUP# = LF.GROUP#;
查询结果:
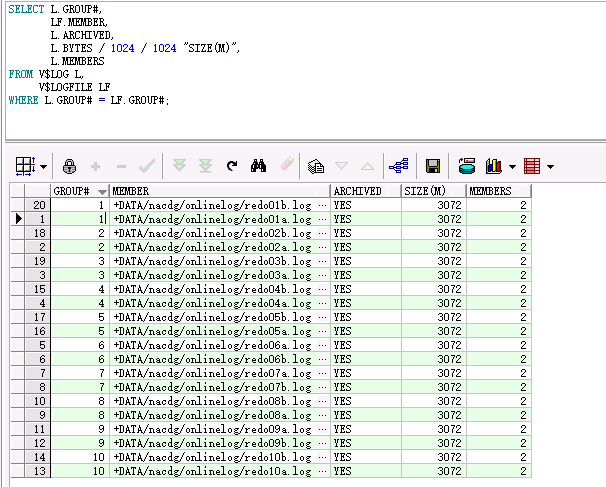
从上图可以看出目前共分为10个日志组,每个日志组2个文件,每个文件大小为3G。
三、查询Oracle最近几天每小时归档日志产生数量
SELECT SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5) Day, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '00', 1, 0)) H00, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '01', 1, 0)) H01, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '02', 1, 0)) H02, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '03', 1, 0)) H03, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '04', 1, 0)) H04, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '05', 1, 0)) H05, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '06', 1, 0)) H06, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '07', 1, 0)) H07, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '08', 1, 0)) H08, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '09', 1, 0)) H09, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '10', 1, 0)) H10, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '11', 1, 0)) H11, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '12', 1, 0)) H12, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '13', 1, 0)) H13, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '14', 1, 0)) H14, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '15', 1, 0)) H15, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '16', 1, 0)) H16, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '17', 1, 0)) H17, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '18', 1, 0)) H18, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '19', 1, 0)) H19, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '20', 1, 0)) H20, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '21', 1, 0)) H21, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '22', 1, 0)) H22, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '23', 1, 0)) H23, COUNT(*) TOTAL FROM v$log_history a WHERE first_time >= to_char(sysdate - 10) GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5) ORDER BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5) DESC;
查询结果
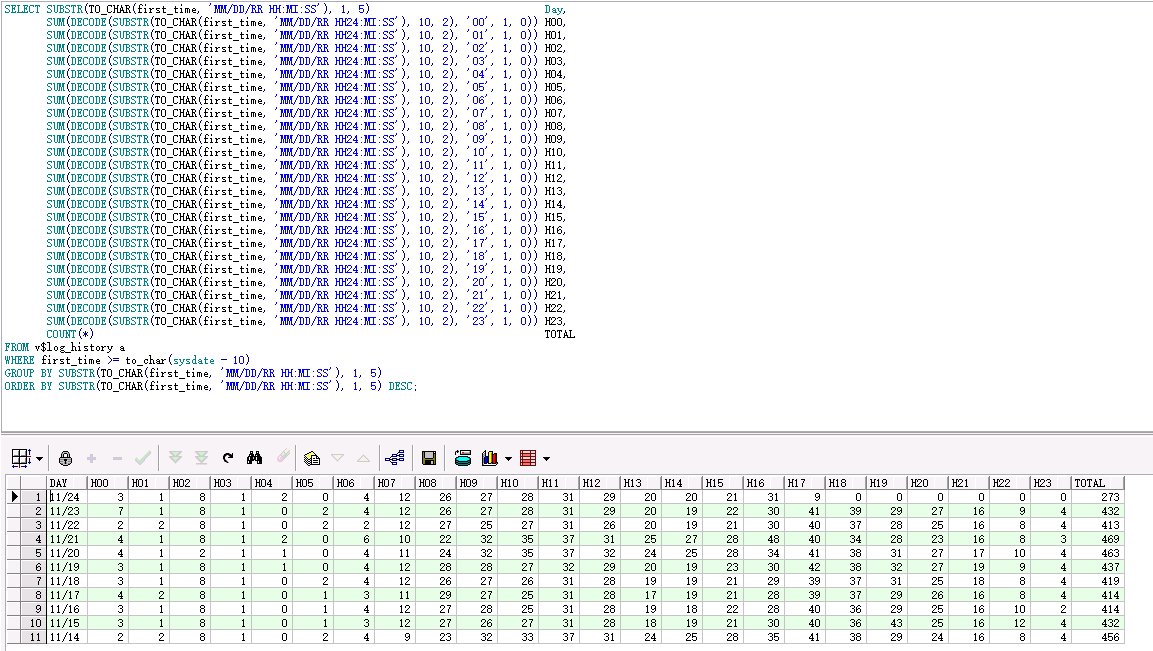
从上图可以看出业务高峰期每小时产生40个日志文件左右(目前设定的每个日志文件大小为3G),平均1.5分钟产生一个3G的日志文件。而oracle官方建议Redo日志平均30分钟切换一次最好。
四、查看最近2小时"块改变"最多的segment
redo大量产生必然是由于大量产生"块改变"。从awr视图中找到"块改变"最多的segment。
这是查询最近2小时(120分钟)的,begin_interval_time> sysdate - 120/1440,大家也可以自定义修改查询最近多少分钟的。
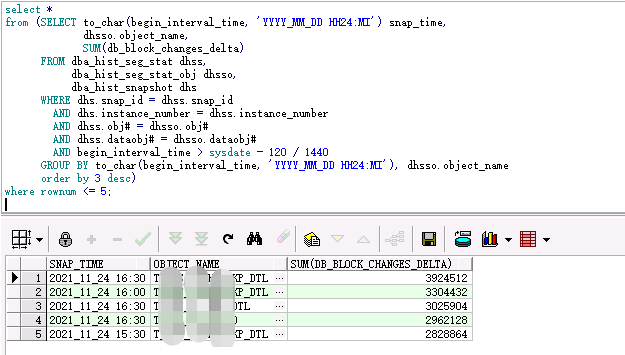
1 select * 2 from (SELECT to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI') snap_time, 3 dhsso.object_name, 4 SUM(db_block_changes_delta) 5 FROM dba_hist_seg_stat dhss, 6 dba_hist_seg_stat_obj dhsso, 7 dba_hist_snapshot dhs 8 WHERE dhs.snap_id = dhss.snap_id 9 AND dhs.instance_number = dhss.instance_number 10 AND dhss.obj# = dhsso.obj# 11 AND dhss.dataobj# = dhsso.dataobj# 12 AND begin_interval_time > sysdate - 120 / 1440 13 GROUP BY to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI'), dhsso.object_name 14 order by 3 desc) 15 where rownum <= 5;
查询结果:
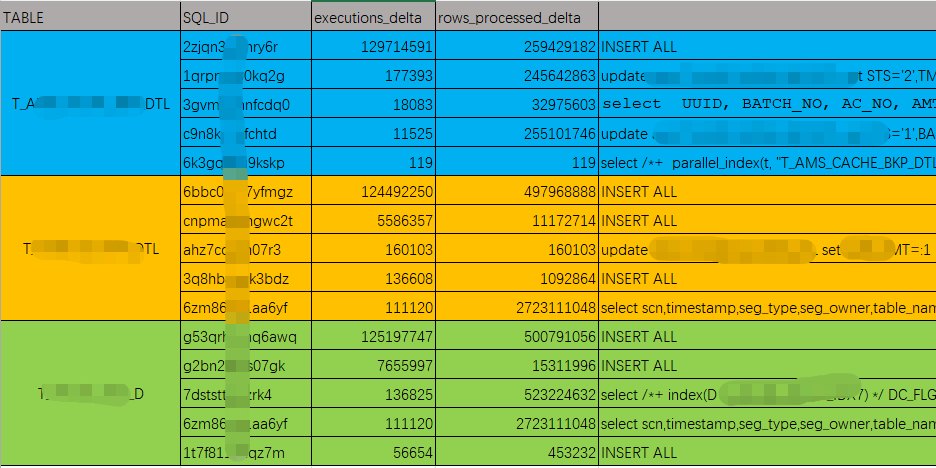
五、从awr视图中找出步骤四中排序靠前的对象涉及的SQL
说明:LIKE '%MON_MODS$%'中MON_MODS是步骤1中查询出来的OBJECT_NAME
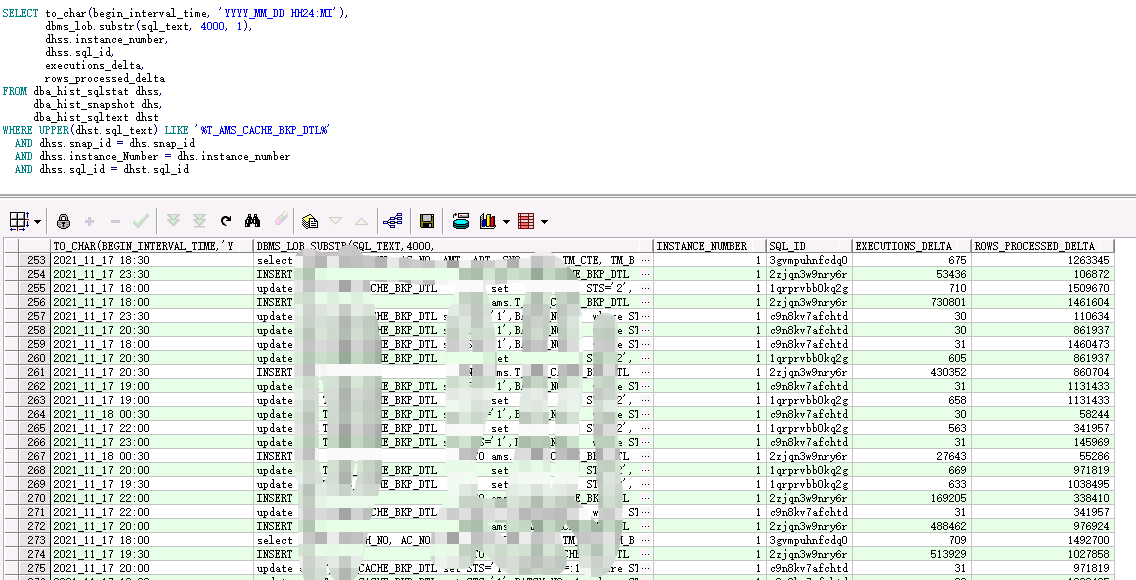
1 SELECT to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI'), 2 dbms_lob.substr(sql_text, 4000, 1), 3 dhss.instance_number, 4 dhss.sql_id, 5 executions_delta, 6 rows_processed_delta 7 FROM dba_hist_sqlstat dhss, 8 dba_hist_snapshot dhs, 9 dba_hist_sqltext dhst 10 WHERE UPPER(dhst.sql_text) LIKE '%MON_MODS$%' 11 AND dhss.snap_id = dhs.snap_id 12 AND dhss.instance_Number = dhs.instance_number 13 AND dhss.sql_id = dhst.sql_id;
查询结果
六、从ASH相关视图找到执行这些SQL的session、module和machine
1 select * from dba_hist_active_sess_history WHERE sql_id = 'c9n8kv7afchtd'; 2 select * from v$active_session_history where sql_Id = 'c9n8kv7afchtd';
c9n8kv7afchtd是SQL_ID,替换第二步查询的结果SQL_ID列
七、排查问题SQL
通过第四步,我们确定了导致产生大量redo日志主要涉及三张表,再通过第五步确定了每张表排名前五的SQL。针对这些产生大量Redo日志的SQL,就是需要做优化的地方。