Spiders - 爬虫文件
概念
介绍
由一系列定义了一个网址或一组网址类如何被爬取的类组成
具体包括如何执行爬取任务并且如何从页面中提取结构化的数据。
简单来说就是帮助你爬取数据的地方
内部行为流程
初始请求以及默认回调
生成初始的 Requests 来爬取第一个URLS,并且标识一个回调函数,
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求
默认的回调函数是parse方法, 回调函数在下载完成返回response时自动触发
回调函数内解析方式
在回调函数中解析页面内容
通常使用Scrapy自带的Selectors
也可以使用Beutifulsoup,lxml或其他
回调函数处理解析并返回
在回调函数中,解析response并且返回值
返回值可以4种:
- 包含解析数据的字典
- Item对象
- 新的Request对象(新的Requests也需要指定一个回调函数)
- 或者是可迭代对象(包含Items或Request)
持久化处理
针对返回的Items对象将会被持久化到数据库或者其他文件
- 通过Item Pipeline组件存到数据库
- https://docs.scrapy.org/en/latest/topics/item-pipeline.html#topics-item-pipeline)
- 或者导出到不同的文件
- 通过Feed exports:https://docs.scrapy.org/en/latest/topics/feed-exports.html#topics-feed-exports
内部类
#1、scrapy.spiders.Spider
#scrapy.Spider等同于scrapy.spiders.Spider #2、scrapy.spiders.CrawlSpider #3、scrapy.spiders.XMLFeedSpider #4、scrapy.spiders.CSVFeedSpider #5、scrapy.spiders.SitemapSpider
class scrapy.spiders.Spider
这是最简单的spider类,任何其他的spider类都需要继承它(包含你自己定义的)。
该类不提供任何特殊的功能,它仅提供了一个默认的start_requests方法默认从start_urls中读取url地址发送requests请求,并且默认parse作为回调函数
scrapy.spiders.CrawlSpider
对 scrapy.spiders.Spider 更进一步封装了的类
创建爬虫
指定模板创建爬虫
scrapy genspider -t crawl lagou www.lagou.com
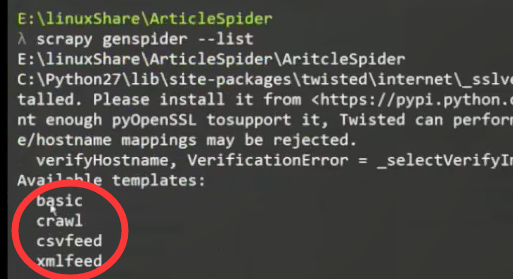
查看支持的模板
默认不指名模板的时候使用第一个 basic 模板
如果使用 basic 模板则使用的是 scrapy.spiders.Spider 类来使用爬虫
crawl ------> scrapy.spiders.CrawlSpider
scrapy genspider --list
使用 - scrapy.spiders.Spider
基础使用框架
import scrapy class AmazonSpider(scrapy.Spider): name = 'amazon' # 爬虫名, 必须唯一 allowed_domains = ['www.amazon.cn'] # 允许爬取的域名 start_urls = ['http://www.amazon.cn/'] # 起始爬取地址
def parse(self,response): # 默认的回调函数, 用于对响应内容进行解析 pass
属性方法
#1、name = 'amazon' 定义爬虫名,scrapy会根据该值定位爬虫程序 所以它必须要有且必须唯一(In Python 2 this must be ASCII only.) #2、allowed_domains = ['www.amazon.cn'] 定义允许爬取的域名,如果OffsiteMiddleware启动(默认就启动), 那么不属于该列表的域名及其子域名都不允许爬取 如果爬取的网址为:https://www.example.com/1.html,那就添加'example.com'到列表. #3、start_urls = ['http://www.amazon.cn/'] 如果没有指定url,就从该列表中读取url来生成第一个请求 #4、custom_settings 值为一个字典,定义一些配置信息,在运行爬虫程序时,这些配置会覆盖项目级别的配置 所以custom_settings必须被定义成一个类属性,由于settings会在类实例化前被加载 #5、settings 通过self.settings['配置项的名字']可以访问settings.py中的配置,如果自己定义了custom_settings还是以自己的为准 #6、logger 日志名默认为spider的名字 self.logger.debug('=============>%s' %self.settings['BOT_NAME']) #5、crawler:了解 该属性必须被定义到类方法from_crawler中 #6、from_crawler(crawler, *args, **kwargs):了解 You probably won’t need to override this directly because the default implementation acts as a proxy to the __init__() method, calling it with the given arguments args and named arguments kwargs. #7、start_requests() 该方法用来发起第一个Requests请求,且必须返回一个可迭代的对象。它在爬虫程序打开时就被Scrapy调用,Scrapy只调用它一次。 默认从start_urls里取出每个url来生成Request(url, dont_filter=True) #针对参数dont_filter,请看自定义去重规则 如果你想要改变起始爬取的Requests,你就需要覆盖这个方法,例如你想要起始发送一个POST请求,如下 class MySpider(scrapy.Spider): name = 'myspider' def start_requests(self): return [scrapy.FormRequest("http://www.example.com/login", formdata={'user': 'john', 'pass': 'secret'}, callback=self.logged_in)] def logged_in(self, response): # here you would extract links to follow and return Requests for # each of them, with another callback pass #8、parse(response) 这是默认的回调函数,所有的回调函数必须返回an iterable of Request and/or dicts or Item objects. #9、log(message[, level, component]):了解 Wrapper that sends a log message through the Spider’s logger, kept for backwards compatibility. For more information see Logging from Spiders. #10、closed(reason) 爬虫程序结束时自动触发
简单实例 - 爬取猫眼电影
循环方式 - 1 递归解析
# -*- coding: utf-8 -*- import scrapy from Maoyan.items import MaoyanItem class MaoyanSpider(scrapy.Spider): # 爬虫名 name = 'maoyan' # 允许爬取的域名 allowed_domains = ['maoyan.com'] offset = 0 # 起始的URL地址 start_urls = ['https://maoyan.com/board/4?offset=0'] def parse(self, response): # 基准xpath,匹配每个电影信息节点对象列表 dd_list = response.xpath('//dl[@class="board-wrapper"]/dd') # dd_list : [<element dd at xxx>,<...>] for dd in dd_list: # 创建item对象 item = MaoyanItem()
# [<selector xpath='' data='霸王别姬'>] # dd.xpath('')结果为[选择器1,选择器2] # .extract() 把[选择器1,选择器2]所有选择器序列化为 unicode 字符串 # .extract_first() : 取第一个字符串
item['name'] = dd.xpath('./a/@title').extract_first().strip() item['star'] = dd.xpath('.//p[@class="star"]/text()').extract()[0].strip() item['time'] = dd.xpath('.//p[@class="releasetime"]/text()').extract()[0] yield item # 此方法不推荐,效率低 self.offset += 10 if self.offset <= 90: url = 'https://maoyan.com/' 'board/4?offset={}'.format(str(self.offset)) yield scrapy.Request( url=url, callback=self.parse )
循环方式 2 - 指定回调
# -*- coding: utf-8 -*- import scrapy from Maoyan.items import MaoyanItem class MaoyanSpider(scrapy.Spider): # 爬虫名 name = 'maoyan2' # 允许爬取的域名 allowed_domains = ['maoyan.com'] # 起始的URL地址 start_urls = ['https://maoyan.com/board/4?offset=0'] def parse(self, response): for offset in range(0, 91, 10): url = 'https://maoyan.com' '/board/4?offset={}'.format(str(offset)) # 把地址交给调度器入队列 yield scrapy.Request( url=url, callback=self.parse_html ) def parse_html(self, response): # 基准xpath,匹配每个电影信息节点对象列表 dd_list = response.xpath( '//dl[@class="board-wrapper"]/dd') # dd_list : [<element dd at xxx>,<...>] for dd in dd_list: # 创建item对象 item = MaoyanItem() item['name'] = dd.xpath('./a/@title').extract_first().strip() item['star'] = dd.xpath('.//p[@class="star"]/text()').extract()[0].strip() item['time'] = dd.xpath('.//p[@class="releasetime"]/text()').extract()[0] yield item
详细框架模板
import scrapy class AmazonSpider(scrapy.Spider): def __init__(self,keyword=None,*args,**kwargs): #在entrypoint文件里面传进来的keyword,在这里接收了 super(AmazonSpider,self).__init__(*args,**kwargs) self.keyword = keyword name = 'amazon' # 必须唯一 allowed_domains = ['www.amazon.cn'] # 允许域 start_urls = ['http://www.amazon.cn/'] # 如果你没有指定发送的请求地址,会默认使用第一个 custom_settings = { # 自定制配置文件,自己设置了用自己的,没有就找父类的 "BOT_NAME": 'HAIYAN_AMAZON', 'REQUSET_HEADERS': {}, } def start_requests(self): url = 'https://www.amazon.cn/s/ref=nb_sb_noss_1/461-4093573-7508641?' url+=urlencode({"field-keywords":self.keyword}) print(url) yield scrapy.Request( url, callback = self.parse_index, #指定回调函数 dont_filter = True, #不去重,这个也可以自己定制 # dont_filter = False, #去重,这个也可以自己定制 # meta={'a':1} #meta代理的时候会用 ) #如果要想测试自定义的dont_filter,可多返回结果重复的即可
常用类 Request

属性
url 指定请求地址
callback 指定回调函数
method 指定请求方式, 默认为 GET , 在使用 POST 表单提交的时候推荐使用
meta 在 request 和 response 中添加传递信息时使用 scrapy.FormRequest
headers 指定请求头, 字典形式可传递多个键值
body 指定请求体
cookies 指定 cookies , 可以自己设置, 列表或者字典形式
但是 scrapy 会自动处理好( 默认自带一个中间件处理 ), 所以不需要操心这个
priority 优先级, 越高越优先, 默认为 0
dont_filter 默认为 False , 表示不能被过滤, 设置为 True 时, 表示会被过滤
errback 返回 500 或者 404 的时候的回调函数, 发送错误的回调
方法
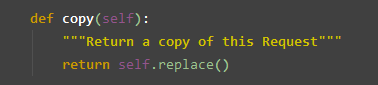
copy() 返回一个当前请求的复制

replace() 返回一个当前请求某些属性的替换后的复制
子类
FormRequest 用于处理 表单POST 方式提交数据请求
XmlRpcRequest 没用过不清楚是干嘛的
常用类 Response
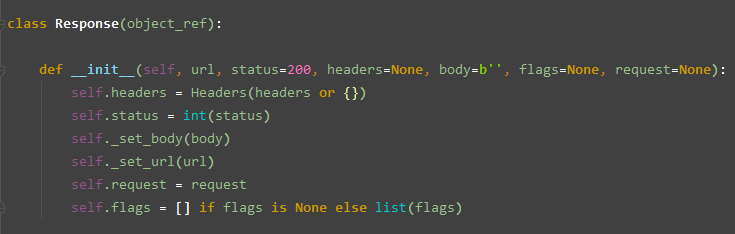
属性
url 当前响应网页的 URL
status 当前响应的 状态码, 默认是 200
headers 服务器返回的响应头
body 当前响应网页的全部内容
request 当前响应之前的请求, 通过此属性可以拿到此响应的发送请求
方法

copy() 当前响应的复制
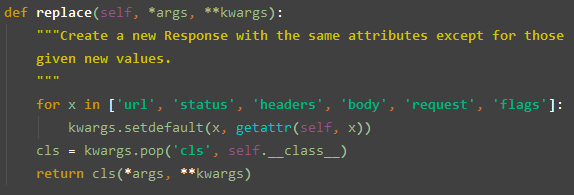
replace() 当前响应替换某些属性后的复制

urljoin() 进行 URL 的拼接
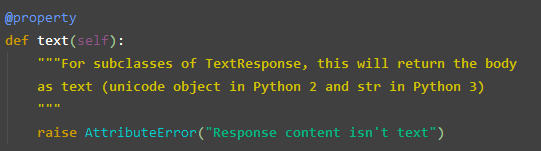
text 当前响应的内容
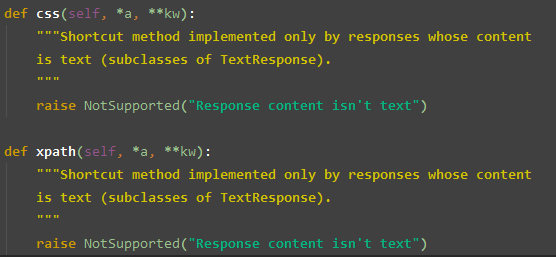
css() / xpath() CSS / Xpath 标签选择器方法
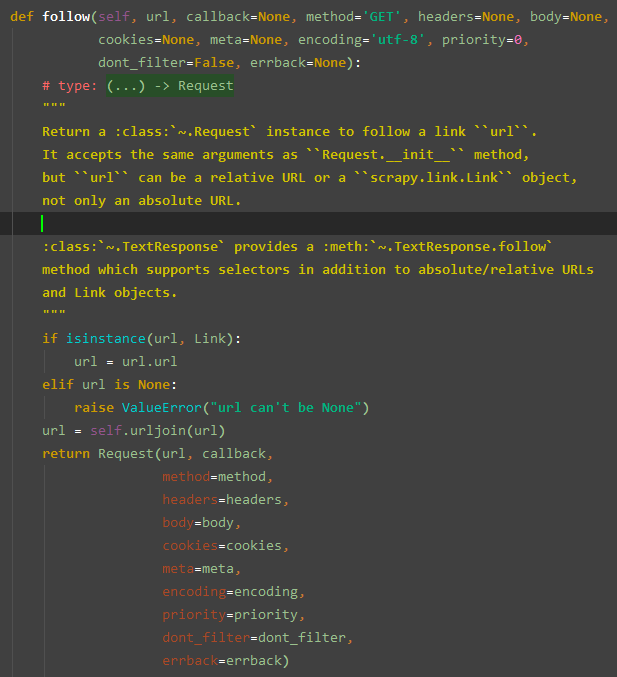
follow
子类
TextResponse 该子类中进行大量的落实操作,对 Response 类进行了大量方法重写


1 class TextResponse(Response): 2 3 _DEFAULT_ENCODING = 'ascii' 4 5 def __init__(self, *args, **kwargs): 6 self._encoding = kwargs.pop('encoding', None) 7 self._cached_benc = None 8 self._cached_ubody = None 9 self._cached_selector = None 10 super(TextResponse, self).__init__(*args, **kwargs) 11 12 def _set_url(self, url): 13 if isinstance(url, six.text_type): 14 if six.PY2 and self.encoding is None: 15 raise TypeError("Cannot convert unicode url - %s " 16 "has no encoding" % type(self).__name__) 17 self._url = to_native_str(url, self.encoding) 18 else: 19 super(TextResponse, self)._set_url(url) 20 21 def _set_body(self, body): 22 self._body = b'' # used by encoding detection 23 if isinstance(body, six.text_type): 24 if self._encoding is None: 25 raise TypeError('Cannot convert unicode body - %s has no encoding' % 26 type(self).__name__) 27 self._body = body.encode(self._encoding) 28 else: 29 super(TextResponse, self)._set_body(body) 30 31 def replace(self, *args, **kwargs): 32 kwargs.setdefault('encoding', self.encoding) 33 return Response.replace(self, *args, **kwargs) 34 35 @property 36 def encoding(self): 37 return self._declared_encoding() or self._body_inferred_encoding() 38 39 def _declared_encoding(self): 40 return self._encoding or self._headers_encoding() 41 or self._body_declared_encoding() 42 43 def body_as_unicode(self): 44 """Return body as unicode""" 45 return self.text 46 47 @property 48 def text(self): 49 """ Body as unicode """ 50 # access self.encoding before _cached_ubody to make sure 51 # _body_inferred_encoding is called 52 benc = self.encoding 53 if self._cached_ubody is None: 54 charset = 'charset=%s' % benc 55 self._cached_ubody = html_to_unicode(charset, self.body)[1] 56 return self._cached_ubody 57 58 def urljoin(self, url): 59 """Join this Response's url with a possible relative url to form an 60 absolute interpretation of the latter.""" 61 return urljoin(get_base_url(self), url) 62 63 @memoizemethod_noargs 64 def _headers_encoding(self): 65 content_type = self.headers.get(b'Content-Type', b'') 66 return http_content_type_encoding(to_native_str(content_type)) 67 68 def _body_inferred_encoding(self): 69 if self._cached_benc is None: 70 content_type = to_native_str(self.headers.get(b'Content-Type', b'')) 71 benc, ubody = html_to_unicode(content_type, self.body, 72 auto_detect_fun=self._auto_detect_fun, 73 default_encoding=self._DEFAULT_ENCODING) 74 self._cached_benc = benc 75 self._cached_ubody = ubody 76 return self._cached_benc 77 78 def _auto_detect_fun(self, text): 79 for enc in (self._DEFAULT_ENCODING, 'utf-8', 'cp1252'): 80 try: 81 text.decode(enc) 82 except UnicodeError: 83 continue 84 return resolve_encoding(enc) 85 86 @memoizemethod_noargs 87 def _body_declared_encoding(self): 88 return html_body_declared_encoding(self.body) 89 90 @property 91 def selector(self): 92 from scrapy.selector import Selector 93 if self._cached_selector is None: 94 self._cached_selector = Selector(self) 95 return self._cached_selector 96 97 def xpath(self, query, **kwargs): 98 return self.selector.xpath(query, **kwargs) 99 100 def css(self, query): 101 return self.selector.css(query) 102 103 def follow(self, url, callback=None, method='GET', headers=None, body=None, 104 cookies=None, meta=None, encoding=None, priority=0, 105 dont_filter=False, errback=None): 106 # type: (...) -> Request 107 """ 108 Return a :class:`~.Request` instance to follow a link ``url``. 109 It accepts the same arguments as ``Request.__init__`` method, 110 but ``url`` can be not only an absolute URL, but also 111 112 * a relative URL; 113 * a scrapy.link.Link object (e.g. a link extractor result); 114 * an attribute Selector (not SelectorList) - e.g. 115 ``response.css('a::attr(href)')[0]`` or 116 ``response.xpath('//img/@src')[0]``. 117 * a Selector for ``<a>`` or ``<link>`` element, e.g. 118 ``response.css('a.my_link')[0]``. 119 120 See :ref:`response-follow-example` for usage examples. 121 """ 122 if isinstance(url, parsel.Selector): 123 url = _url_from_selector(url) 124 elif isinstance(url, parsel.SelectorList): 125 raise ValueError("SelectorList is not supported") 126 encoding = self.encoding if encoding is None else encoding 127 return super(TextResponse, self).follow(url, callback, 128 method=method, 129 headers=headers, 130 body=body, 131 cookies=cookies, 132 meta=meta, 133 encoding=encoding, 134 priority=priority, 135 dont_filter=dont_filter, 136 errback=errback 137 )
HtmlResponse 啥都没做就继承了 TextResponse

特殊操作
cookie / session 处理
在 scrapy 中是无法使用 session = requests.session() 这种方式来处理的
但是 scrapy的 yield scrapy.Request() 在一起请求后会自动处理好 session 相关的处理
并且延续到之后的所有操作, 但是如果中间又需要更新则需要重新发起一次来更新
实例
实际使用场景 - 知乎的反爬策略会在多次爬取时返回 403 错误, 需要验证码登录等
此时需要重来一次发送请求来刷新 cookie
def login(self, response): response_text = response.text match_obj = re.match('.*name="_xsrf" value="(.*?)"', response_text, re.DOTALL) xsrf = '' if match_obj: xsrf = (match_obj.group(1)) if xsrf: post_url = "https://www.zhihu.com/login/phone_num" post_data = { "_xsrf": xsrf, "phone_num": "", "password": "", "captcha": "" } import time t = str(int(time.time() * 1000)) # 验证码请求地址 captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t) # 将数据传递到回调函数中在处理,且将cookie 也传递下去 yield scrapy.Request(captcha_url, headers=self.headers, meta={"post_data": post_data}, callback=self.login_after_captcha) def login_after_captcha(self, response): # 验证码保存本地 with open("captcha.jpg", "wb") as f: f.write(response.body) # 文件是保存在 body 中的, 不是text 中了 f.close() from PIL import Image try: # 打开看一眼验证码然后手动验证 im = Image.open('captcha.jpg') im.show() im.close() except: pass # 手动输入验证码... captcha = input("输入验证码 >") # 上一轮传递过来的数据 post_data = response.meta.get("post_data", {}) post_data["captcha"] = captcha post_url = "https://www.zhihu.com/login/phone_num" # 通过 FormRequest 发起请求 return [scrapy.FormRequest( url=post_url, formdata=post_data, headers=self.headers, callback=self.check_login )] def check_login(self, response): # 验证服务器的返回数据判断是否成功 text_json = json.loads(response.text) if "msg" in text_json and text_json["msg"] == "登录成功": for url in self.start_urls: yield scrapy.Request(url, dont_filter=True, headers=self.headers)
去重
去重规则应该多个爬虫共享的,但凡一个爬虫爬取了,其他都不要爬了,实现方式如下
#方法一: 1、新增类属性 visited=set() #类属性 2、回调函数parse方法内: def parse(self, response): if response.url in self.visited: return None ....... self.visited.add(response.url) #方法一改进:针对url可能过长,所以我们存放url的hash值 def parse(self, response): url=md5(response.request.url) if url in self.visited: return None ....... self.visited.add(url) #方法二:Scrapy自带去重功能 配置文件: DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' #默认的去重规则帮我们去重,去重规则在内存中 DUPEFILTER_DEBUG = False JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen,去重规则放文件中 scrapy自带去重规则默认为RFPDupeFilter,只需要我们指定 Request(...,dont_filter=False) ,如果dont_filter=True则告诉Scrapy这个URL不参与去重。 #方法三: 我们也可以仿照RFPDupeFilter自定义去重规则, from scrapy.dupefilter import RFPDupeFilter,看源码,仿照BaseDupeFilter #步骤一:在项目目录下自定义去重文件cumstomdupefilter.py ''' if hasattr("MyDupeFilter",from_settings): func = getattr("MyDupeFilter",from_settings) obj = func() else: return MyDupeFilter() ''' class MyDupeFilter(object): def __init__(self): self.visited = set() @classmethod def from_settings(cls, settings): '''读取配置文件''' return cls() def request_seen(self, request): '''请求看过没有,这个才是去重规则该调用的方法''' if request.url in self.visited: return True self.visited.add(request.url) def open(self): # can return deferred '''打开的时候执行''' pass def close(self, reason): # can return a deferred pass def log(self, request, spider): # log that a request has been filtered '''日志记录''' pass #步骤二:配置文件settings.py # DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' #默认会去找这个类实现去重 #自定义去重规则 DUPEFILTER_CLASS = 'AMAZON.cumstomdupefilter.MyDupeFilter' # 源码分析: from scrapy.core.scheduler import Scheduler 见Scheduler下的enqueue_request方法:self.df.request_seen(request)
start_urls 定制
内部原理
scrapy引擎来爬虫中取起始URL:
1. 调用start_requests并获取返回值
2. v = iter(返回值)
3.
req1 = 执行 v.__next__()
req2 = 执行 v.__next__()
req3 = 执行 v.__next__()
...
4. req全部放到调度器中
自定义实例
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] cookie_dict = {} def start_requests(self): # 方式一: for url in self.start_urls: yield Request( url=url, callback=self.parse, method='POST' # 自己写的优先级更高。因此在这里可以指定 post 请求也可以作为起始了 ) # 方式二: # req_list = [] # for url in self.start_urls: # req_list.append(Request(url=url)) # return req_list
设置随机 User-Agent
方式一
利用 random 进行随机的在代理列表里面选择, 然后赋值给属性, 虽然简单
但是每次在发送请求的时候都要进行这个操作, 代码重复很多不合适
方式二
利用下载器中间件完成
设置代理IP
内置方式设置
os.envrion设置代理
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] cookie_dict = {} def start_requests(self): import os os.environ['HTTPS_PROXY'] = "http://root:yangtuo@192.168.11.11:9999/" os.environ['HTTP_PROXY'] = '19.11.2.32', for url in self.start_urls: yield Request(url=url,callback=self.parse)
meta 方式设置
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] cookie_dict = {} def start_requests(self): for url in self.start_urls: yield Request(url=url,callback=self.parse,meta={'proxy':'"http://root:yangtuo@192.168.11.11:9999/"'})
中间件方式实现 - 自定义方式设置
import base64 import random from six.moves.urllib.parse import unquote try: from urllib2 import _parse_proxy except ImportError: from urllib.request import _parse_proxy from six.moves.urllib.parse import urlunparse from scrapy.utils.python import to_bytes class XdbProxyMiddleware(object): def _basic_auth_header(self, username, password): user_pass = to_bytes( '%s:%s' % (unquote(username), unquote(password)), encoding='latin-1') return base64.b64encode(user_pass).strip() def process_request(self, request, spider): PROXIES = [ "http://root:yangtuo@192.168.11.11:9999/", "http://root:yangtuo@192.168.11.12:9999/", "http://root:yangtuo@192.168.11.13:9999/", "http://root:yangtuo@192.168.11.14:9999/", "http://root:yangtuo@192.168.11.15:9999/", ] url = random.choice(PROXIES) orig_type = "" proxy_type, user, password, hostport = _parse_proxy(url) proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', '')) if user: creds = self._basic_auth_header(user, password) else: creds = None request.meta['proxy'] = proxy_url if creds: request.headers['Proxy-Authorization'] = b'Basic ' + creds
URL 拼接
适用场景
某些 URL 是基于当前额页面进行的相对地址 URL
直接通过 a[@href] 或者 a::attr() 是只能拿到残缺的 URL
需要一种手段实现讲当前页面的域名进行拼接
解决方法
scrapy中 response 提取的没有主域名的url拼接
# 1.导入urllib的parse
# 2.调用parse.urljoin()进行拼接
例子中response.url会自动提取出当前页面url的主域名
get_url是从response中的元素中提取的没有主域名的url
from urllib import parse url = parse.urljoin(response.url, get_url)
传递参数
设置 meta 可以将上一次请求的某些参数传递到响应中供下一次的请求来使用
代码
def parse1(self, response): item = ... yield = scrapy.Request( url=url, meta={'item': item} callback = self.parse2 ) def parse2(self, response): item = response.meta['item'] ...
传递参数实例
#在items模块中有下面三个参数: import scrapy class TextItem(spider.Item): title = scrapy.Field() price = scrapy.Field() image = scrapy.Field() #在spider爬虫中: class TaobaoSpider(scrapy.Spider): name = ['taobao'] allowed_domains = ['www.taobao.com'] def parse1(self,response): ''' 需要知道的是item是一个字典 ''' item = TextItem() for product in response.css('......').extract(): item['title'] = product.css('......').extract_first() item['price'] = product.css('......').extract_first() url = product.css('......').extract_first() yield = scrapy.Request(url=url, meta={'item':item} callback=self.parse2) ''' 比如我们要爬取淘宝上的商品,我们在第一层爬取时候获得了标题(title)和价格(price), 但是还想获得商品的图片,就是那些点进去的大图片,假设点进去的链接是上述代码的url, 利用scrpy.Request请求url后生成一个Request对象,通过meta参数,把item这个字典赋值给meta字典的'item'键, 即meta={'item':item},这个meta参数会被放在Request对象里一起发送给parse2()函数。 ''' def parse2(self,response): item = response.meta['item'] for product in response.css('......').extract(): item[imgae] = product.scc('......').extract_first() return item ''' 这个response已含有上述meta字典,此句将这个字典赋值给item,完成信息传递。 这个item已经和parse中的item一样了 之后我们就可以做图片url提取的工作了, 数据提取完成后return item ,这样就完成了数据抓取的任务了。 '''
命令行传递参数
# 我们可能需要在命令行为爬虫程序传递参数,比如传递初始的url,像这样 # 命令行执行 scrapy crawl myspider -a category=electronics #在__init__方法中可以接收外部传进来的参数 import scrapy class MySpider(scrapy.Spider): name = 'myspider' def __init__(self, category=None, *args, **kwargs): super(MySpider, self).__init__(*args, **kwargs) self.start_urls = ['http://www.example.com/categories/%s' % category] #... #注意接收的参数全都是字符串,如果想要结构化的数据,你需要用类似json.loads的方法
爬虫暂停重启
原理
爬虫的暂停重启是需要文件支持
在启动的命令里选择一个路径
不同的爬虫不能共用,
相同的爬虫如果公用同一个就会给予这个文件的上一次状态继续爬取
该命令的中断命令是基于 windows Ctrl+c / 杀进程 或者 Linux 里面的 kill -f -9 main.py
因此在 pycharm 中的中断是做不到的, 只能在命令行中处理
scrapy crawl lagou -s JOBDIR=job_info/001
配置文件方式
指定 文件路径可以在 settings.py 中设置
这样就是全局设置了
JOBDIR="job_info/001"
或者在单爬虫类中设置
cutom_settings = {
"JOBDIR": "job_info/001"
}
总结
但是还是和上面的说法一样.....pycharm 里面没办法中断, 因此还是没有啥意义,
还是只能使用命令行方式
爬虫 - 数据分析
内置了很多的简单的分析
""" Scrapy extension for collecting scraping stats """ import pprint import logging logger = logging.getLogger(__name__) class StatsCollector(object): def __init__(self, crawler): self._dump = crawler.settings.getbool('STATS_DUMP') self._stats = {} def get_value(self, key, default=None, spider=None): return self._stats.get(key, default) def get_stats(self, spider=None): return self._stats def set_value(self, key, value, spider=None): self._stats[key] = value def set_stats(self, stats, spider=None): self._stats = stats def inc_value(self, key, count=1, start=0, spider=None): d = self._stats d[key] = d.setdefault(key, start) + count def max_value(self, key, value, spider=None): self._stats[key] = max(self._stats.setdefault(key, value), value) def min_value(self, key, value, spider=None): self._stats[key] = min(self._stats.setdefault(key, value), value) def clear_stats(self, spider=None): self._stats.clear() def open_spider(self, spider): pass def close_spider(self, spider, reason): if self._dump: logger.info("Dumping Scrapy stats: " + pprint.pformat(self._stats), extra={'spider': spider}) self._persist_stats(self._stats, spider) def _persist_stats(self, stats, spider): pass class MemoryStatsCollector(StatsCollector): def __init__(self, crawler): super(MemoryStatsCollector, self).__init__(crawler) self.spider_stats = {} def _persist_stats(self, stats, spider): self.spider_stats[spider.name] = stats class DummyStatsCollector(StatsCollector): def get_value(self, key, default=None, spider=None): return default def set_value(self, key, value, spider=None): pass def set_stats(self, stats, spider=None): pass def inc_value(self, key, count=1, start=0, spider=None): pass def max_value(self, key, value, spider=None): pass def min_value(self, key, value, spider=None): pass
简单的使用示例
设置信号量追踪, 然后设置一个计数器递增, 将 404 的页面url 放入容器中
from scrapy.xlib.pydispatch import dispatcher from scrapy import signals
handle_httpstatus_list = [404] def __init__(self, **kwargs): self.fail_urls = []
def parse(self, response): if response.status == 404: self.fail_urls.append(response.url) self.crawler.stats.inc_value("failed_url") ...
使用 - scrapy.spiders.CrawlSpider
概念
官方文档 - 这里
作为一个更好封装的爬虫类, 里面提供更简单的使用方式
创建爬虫
指定模板 crawl 时使用此类创建爬虫
scrapy genspider -t crawl lagou www.lagou.com
基础模板
import scrapy from scrapy.spiders import CrawlSpider, Rule from scrapy.linkextractors import LinkExtractor class MySpider(CrawlSpider): name = 'example.com' allowed_domains = ['example.com'] start_urls = ['http://www.example.com'] rules = ( # Extract links matching 'category.php' (but not matching 'subsection.php') # and follow links from them (since no callback means follow=True by default). Rule(LinkExtractor(allow=('category.php', ), deny=('subsection.php', ))), # Extract links matching 'item.php' and parse them with the spider's method parse_item Rule(LinkExtractor(allow=('item.php', )), callback='parse_item'), ) def parse_item(self, response): self.logger.info('Hi, this is an item page! %s', response.url) item = scrapy.Item() item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (d+)') item['name'] = response.xpath('//td[@id="item_name"]/text()').get() item['description'] = response.xpath('//td[@id="item_description"]/text()').get() return item
简单说明
CrawlSpider 的使用几乎类似于 Spider , 也拥有 name , allowed_domains , start_urls 属性作用同 Spider
但是内部提供了一个变量 rules
▨ rules
内部使用了 LinkExtractor 方法
▧ LinkExtractor
此方法内部含有两个参数,
▧ allow 指明匹配规则
callback 指明回调函数, 传值为字符串形式, 因为是类方法, 无 self 可以调用
源码解析
全部代码
class CrawlSpider(Spider): rules = () def __init__(self, *a, **kw): super(CrawlSpider, self).__init__(*a, **kw) self._compile_rules() def parse(self, response): return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True) def parse_start_url(self, response): return [] def process_results(self, response, results): return results def _build_request(self, rule, link): r = Request(url=link.url, callback=self._response_downloaded) r.meta.update(rule=rule, link_text=link.text) return r def _requests_to_follow(self, response): if not isinstance(response, HtmlResponse): return seen = set() for n, rule in enumerate(self._rules): links = [lnk for lnk in rule.link_extractor.extract_links(response) if lnk not in seen] if links and rule.process_links: links = rule.process_links(links) for link in links: seen.add(link) r = self._build_request(n, link) yield rule.process_request(r) def _response_downloaded(self, response): rule = self._rules[response.meta['rule']] return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow) def _parse_response(self, response, callback, cb_kwargs, follow=True): if callback: cb_res = callback(response, **cb_kwargs) or () cb_res = self.process_results(response, cb_res) for requests_or_item in iterate_spider_output(cb_res): yield requests_or_item if follow and self._follow_links: for request_or_item in self._requests_to_follow(response): yield request_or_item def _compile_rules(self): def get_method(method): if callable(method): return method elif isinstance(method, six.string_types): return getattr(self, method, None) self._rules = [copy.copy(r) for r in self.rules] for rule in self._rules: rule.callback = get_method(rule.callback) rule.process_links = get_method(rule.process_links) rule.process_request = get_method(rule.process_request) @classmethod def from_crawler(cls, crawler, *args, **kwargs): spider = super(CrawlSpider, cls).from_crawler(crawler, *args, **kwargs) spider._follow_links = crawler.settings.getbool( 'CRAWLSPIDER_FOLLOW_LINKS', True) return spider def set_crawler(self, crawler): super(CrawlSpider, self).set_crawler(crawler) self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
parse
CrawlSpider 是继承自 Spider , 但是没有重写 start_requests 方法, 只能基于 Spider 来进行的爬虫入口
但是内部重写了 parse 方法, 在 Spider 的时候是基于直接在爬虫文件中进行重写 此函数, 但是在 CrawlSpider 中是不能这样做的

_parse_response
在 parse 方法中执行了此函数,
if callback:
函数显示从这里开始
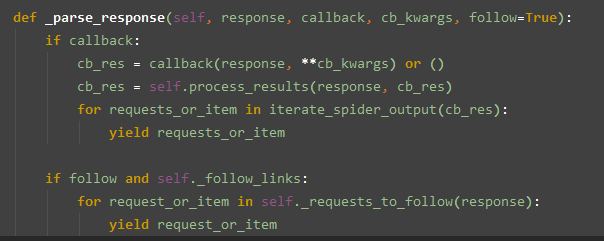
既然不能自己重写 parse 作为回调了, 那 CrawlSpider 也提供了一个接口用来让用户重写作为回调
此函数为 parse_start_url , 此函数很煎蛋.

同时在此函数中还有对 process_results 的调用, 而且此函数方法也是很煎蛋

如果这两个函数为空, 则 callback 是无意义的, 这两个函数是用作用户重写的钩子函数
if follow and self._follow_links:
follow 参数 有默认值为 True , 接着往下执行到了需要一个 _follow_links 属性,
此属性在 set_crawler 函数中, 可见此属性是一个配置文件中的配置属性 CRAWLSPIDER_FOLLOW_LINKS
默认为 True , 如果设置为 False 则就不会往下执行此函数结束, 默认是继续往下执行 _requests_to_follow

_requests_to_follow
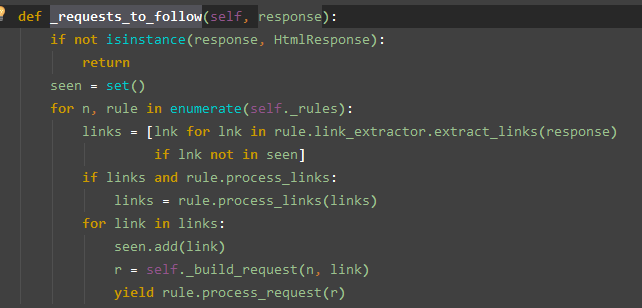
此函数在会进行一个去重,然后将 _rules 改成一个可迭代对象, 那这个 _rules 从何而来?
问问 _compile_rules 吧, 此函数还可以用到一个 process_links ,
追踪此方法, 可见是在 Rule 类中的一个初始化属性, 可见此方法也是个钩子可以自定义一系列操作
这个 Rule 就是我们在爬虫文件中自行定制 rules 用的那个实例类
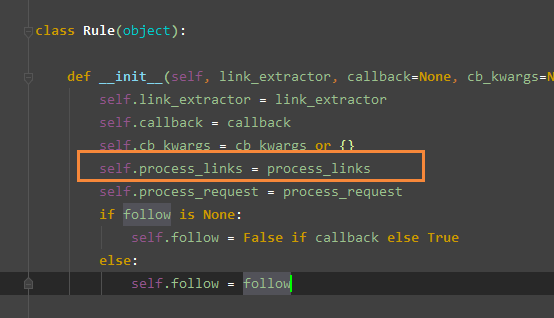
然后对 process_links 处理完后进行集合的添加, 然后进行 _build_request 调用进行请求封装

查看 _build_request 的源码中, 进行了 callback , 此处的回调并不是调用用户自定义的
而是 _response_downloaded

此方法的返回值就是 _parse_response 的运行结果
_parse_response 的执行的最后, 会 yield 进行处理发送请 求开始爬取数据
由此可见就连起来了.
_compile_rules
此函数来完成一个 _rules 的封装, 代码可见到是一个浅拷贝
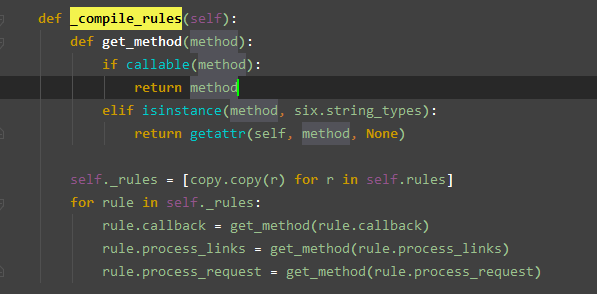
那么此函数何时被使用呢?
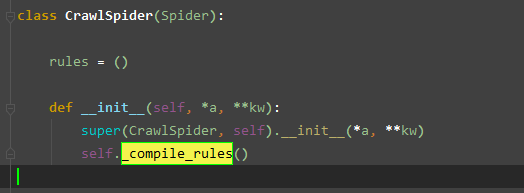
在 CrawlSpider 类实例化的时候自动执行,执行的时候就会遍历所有的规则然后进行

这三个函数的调用, 至此, 整个流程完成
总结流程图
源码还是比较短的, 稍微画个图
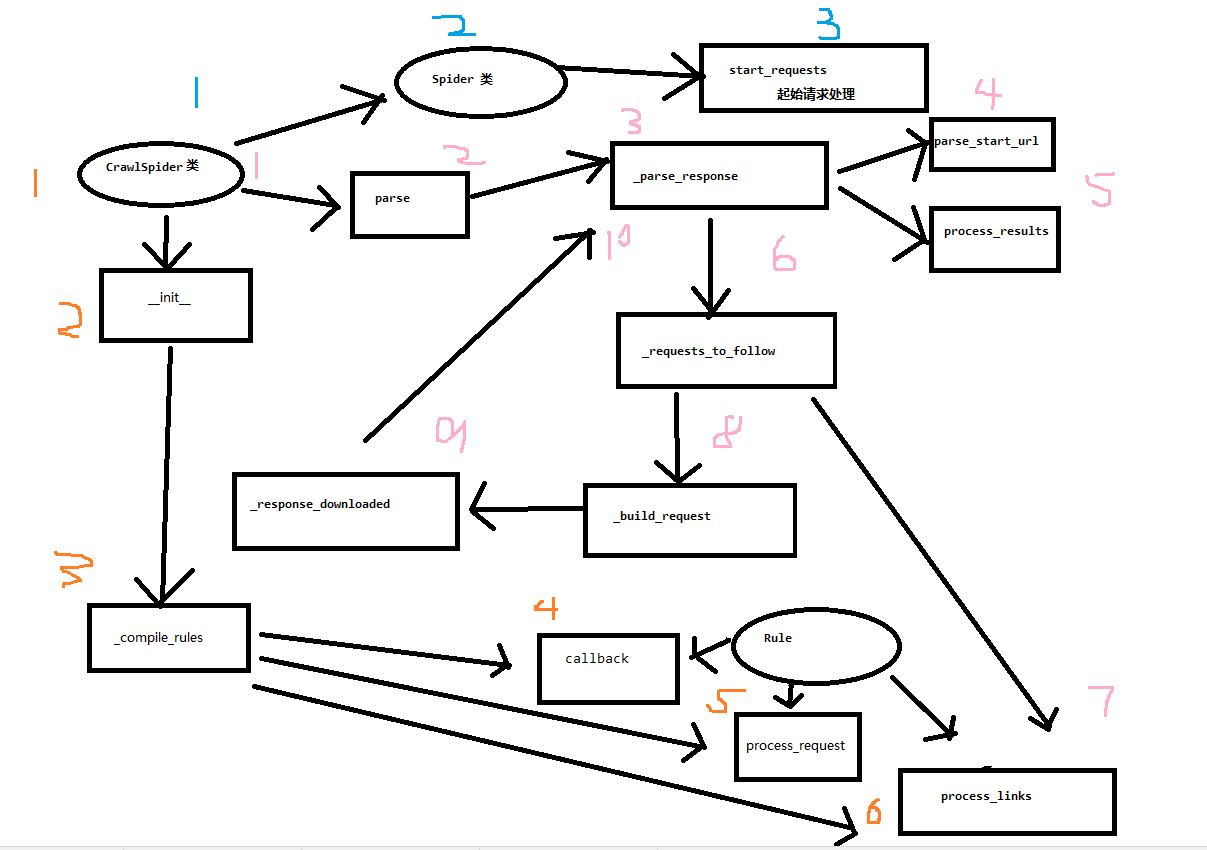
了解了以上的源码流程, 重点就是要看到底怎么用
这里主要围绕 Rule 以及 LinkExtractor 这两个类展开
这两个类也是在爬虫文件中直接要使用的需要被实例化的类
Rule
class Rule(object): def __init__(self, link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=identity): self.link_extractor = link_extractor self.callback = callback self.cb_kwargs = cb_kwargs or {} self.process_links = process_links self.process_request = process_request if follow is None: self.follow = False if callback else True else: self.follow = follow
类实例化相关参数解析
link_extractor LinkExtractor 创建的实例, 下面那个就是
callback 回调的函数
cb_kwargs 传递给 link_extracto 的参数
follow 满足的是否进行跟踪
process_links 自己定制的相关预处理操作接口
process_request 对 request 进行处理的函数接口 - 默认是个很简单的直接传x返回x的函数,可以用来重写或者覆盖
LinkExtractor
class LxmlLinkExtractor(FilteringLinkExtractor): def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(), tags=('a', 'area'), attrs=('href',), canonicalize=False, unique=True, process_value=None, deny_extensions=None, restrict_css=(), strip=True): ...
...
...
def extract_links(self, response): base_url = get_base_url(response) if self.restrict_xpaths: docs = [subdoc for x in self.restrict_xpaths for subdoc in response.xpath(x)] else: docs = [response.selector] all_links = [] for doc in docs: links = self._extract_links(doc, response.url, response.encoding, base_url) all_links.extend(self._process_links(links)) return unique_list(all_links)
类实例化相关参数解析
allow 所有符合的URL, 传入值为正则表达式, 且支持元组形式
deny 不符合的URL
allow_domains 所有域内的URL
deny_domains 不在域内的URL
restrict_xpaths 进一步的限定URL - 基于xpath实现特定位置的标签内寻找 URL
restrict_css 进一步的限定URL - 基于 css 实现特定位置的标签内寻找 URL
tags 在哪里找URL ( 默认是 a, area 标签 ) - 不需要手动修改
attrs 基于tags,找到标签后具体找哪个属性 ( 默认是 href ) - 不需要手动修改
其他参数无视即可
实际使用
rules = ( Rule(LinkExtractor(allow=("zhaopin/.*",)), follow=True), Rule(LinkExtractor(allow=("gongsi/jd+.html",)), follow=True), Rule(LinkExtractor(allow=r'jobs/d+.html'), callback='parse_job', follow=True), )
itemloader
对比
基础的使用方式下, 每个爬虫的 item 字段都需要配置一次 xpath 或者 css 进行选择
因此如果页面抓取次数多了每个回调函数都要进行一次的重复, 非常不便
基础方式
def parse_detail(self, response): article_item = JobBoleArticleItem() # 提取文章的具体字段 title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first("") create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip() praise_nums = response.xpath("//span[contains(@class, 'vote-post-up')]/h10/text()").extract()[0] fav_nums = response.xpath("//span[contains(@class, 'bookmark-btn')]/text()").extract()[0] match_re = re.match(".*?(d+).*", fav_nums) if match_re: fav_nums = match_re.group(1) comment_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] match_re = re.match(".*?(d+).*", comment_nums) if match_re: comment_nums = match_re.group(1) content = response.xpath("//div[@class='entry']").extract()[0] tag_list = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ",".join(tag_list) # 通过css选择器提取字段 front_image_url = response.meta.get("front_image_url", "") #文章封面图 title = response.css(".entry-header h1::text").extract()[0] create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip() praise_nums = response.css(".vote-post-up h10::text").extract()[0] fav_nums = response.css(".bookmark-btn::text").extract()[0] match_re = re.match(".*?(d+).*", fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0] match_re = re.match(".*?(d+).*", comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 content = response.css("div.entry").extract()[0] tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ",".join(tag_list) article_item["url_object_id"] = get_md5(response.url) article_item["title"] = title article_item["url"] = response.url try: create_date = datetime.datetime.strptime(create_date, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() article_item["create_date"] = create_date article_item["front_image_url"] = [front_image_url] article_item["praise_nums"] = praise_nums article_item["comment_nums"] = comment_nums article_item["fav_nums"] = fav_nums article_item["tags"] = tags article_item["content"] = content yield article_item
使用 itemloader 方式
def parse_detail(self, response): article_item = JobBoleArticleItem() #通过item loader加载item front_image_url = response.meta.get("front_image_url", "") # 文章封面图 item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response) item_loader.add_css("title", ".entry-header h1::text") item_loader.add_value("url", response.url) item_loader.add_value("url_object_id", get_md5(response.url)) item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text") item_loader.add_value("front_image_url", [front_image_url]) item_loader.add_css("praise_nums", ".vote-post-up h10::text") item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text") item_loader.add_css("fav_nums", ".bookmark-btn::text") item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text") item_loader.add_css("content", "div.entry") article_item = item_loader.load_item() yield article_item
使用
导入
from scrapy.loader import ItemLoader
实例化
item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response)
item 爬虫的 item 的实例化,
response 爬虫的 回传信息 reponse
实例方法
add_css / add_xpath - 基于选择器
item_loader.add_css("title", ".entry-header h1::text")
item_loader.add_xpath("title", "//div[@class="entry-header"]/h1/text()")
第一个参数 item 的属性键
第二个参数 css 选择规则
返回值 列表
add_value - 基于直接回传的数据
第一个参数 item 的属性键
第二个参数 response 的属性值
返回值 列表
item_loader.add_value("url", response.url)
定制字段字段方法
建立映射后代码变的及其整洁且精简
但是返回数据都是列表形式, 且某系字段的特殊处理也无法在这里完成
因此特殊的操作需要在 item.py 定制的时候进行操作
且自定义的相关方法, 在不同的 item 中也可以被复用
模板
class XXXItem(scrapy.Item): xxx = scrapy.Field( input_processor = MapCompose(func1,func2), output_processor = TakeFirst() )
scrapy.Field 内部的两个字段
▨ input_processor
此字段用来规范计算 item 键值的定制产生
▨ output_processor
此字段用来规范 item 键值的结果输出
定制方法
首先是需要导入这个两个类
from scrapy.loader.processors import MapCompose, TakeFirst, Join
▨ MapCompose(func1,func2)
配合 input_processor 字段一起使用, 对item 的键值进行自定函数加工
参数可传递多个函数, 会遍历执行这两个函数的结果作为此 item 键的值
多个函数的执行是线性的, 后面函数的结果会叠加而不是覆盖
配合 output_processor 字段使用可以起到对结果值的覆盖.
▨ TakeFirst()
无参数, 配合 output_processor 字段一起使用用于只输出第一个对象
解决返回数据都是列表的问题, 如果确定键的值是唯一的, 可以加此属性
但是如果字段过多都需要每个添加比较麻烦, 可以使用 自定制 ltemloader
▨ 自定制 Itemloader 输出列表首项
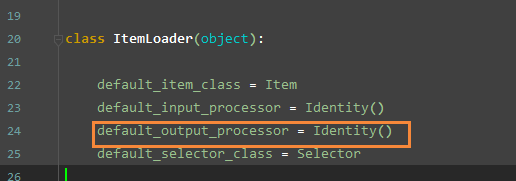
默认的 itemloader 的 out_processor 是 Identily
自定义继承然后进行特换为 TakeFirst 即可实现所有的字段都是用列表首项
从而取消单数据被迫使用列表问题
但是这样导致所有的字段都产出单数据, 因此对原产出多数据的需要用 Join 处理
from scrapy.loader import ItemLoader
class ArticleItemLoader(ItemLoader): # 自定义itemloader default_output_processor = TakeFirst()
▨ Join 指定列表进行连接
在被使用 全局列表首项产出时, 对多数据进行原有形式产出.
保留所有数据并可以指定连接符号产出字符串
tags = scrapy.Field( input_processor=MapCompose(remove_comment_tags), output_processor = Join(",") )
定制示例
内置的去除tags
item_loader.add_css("job_addr", ".work_addr")
-----------------------------------------
from w3lib.html import remove_tags ----------------------------------------- job_addr = scrapy.Field( input_processor=MapCompose(remove_tags), )
自定义添加时间格式
def date_convert(value): try: create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() return create_date ---------------------------------------------------------- create_date = scrapy.Field( input_processor=MapCompose(date_convert), )
自定义正则处理字段在多字段中复用
def get_nums(value): match_re = re.match(".*?(d+).*", value) if match_re: nums = int(match_re.group(1)) else: nums = 0 return nums ------------------------------------------------- praise_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) comment_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) fav_nums = scrapy.Field( input_processor=MapCompose(get_nums) )
例子合集
#例一: import scrapy class MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com'] start_urls = [ 'http://www.example.com/1.html', 'http://www.example.com/2.html', 'http://www.example.com/3.html', ] def parse(self, response): self.logger.info('A response from %s just arrived!', response.url) #例二:一个回调函数返回多个Requests和Items import scrapy class MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com'] start_urls = [ 'http://www.example.com/1.html', 'http://www.example.com/2.html', 'http://www.example.com/3.html', ] def parse(self, response): for h3 in response.xpath('//h3').extract(): yield {"title": h3} for url in response.xpath('//a/@href').extract(): yield scrapy.Request(url, callback=self.parse) #例三:在start_requests()内直接指定起始爬取的urls,start_urls就没有用了, import scrapy from myproject.items import MyItem class MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com'] def start_requests(self): yield scrapy.Request('http://www.example.com/1.html', self.parse) yield scrapy.Request('http://www.example.com/2.html', self.parse) yield scrapy.Request('http://www.example.com/3.html', self.parse) def parse(self, response): for h3 in response.xpath('//h3').extract(): yield MyItem(title=h3) for url in response.xpath('//a/@href').extract(): yield scrapy.Request(url, callback=self.parse) #例四: # -*- coding: utf-8 -*- from urllib.parse import urlencode # from scrapy.dupefilter import RFPDupeFilter # from AMAZON.items import AmazonItem from AMAZON.items import AmazonItem ''' spiders会循环做下面几件事 1、生成初始请求来爬取第一个urls,并且绑定一个回调函数 2、在回调函数中,解析response并且返回值 3、在回调函数中,解析页面内容(可通过Scrapy自带的Seletors或者BeautifuSoup等) 4、最后、针对返回的Items对象(就是你从返回结果中筛选出来自己想要的数据)将会被持久化到数据库 Spiders总共提供了五种类: #1、scrapy.spiders.Spider #scrapy.Spider等同于scrapy.spiders.Spider #2、scrapy.spiders.CrawlSpider #3、scrapy.spiders.XMLFeedSpider #4、scrapy.spiders.CSVFeedSpider #5、scrapy.spiders.SitemapSpider ''' import scrapy class AmazonSpider(scrapy.Spider): def __init__(self,keyword=None,*args,**kwargs): #在entrypoint文件里面传进来的keyword,在这里接收了 super(AmazonSpider,self).__init__(*args,**kwargs) self.keyword = keyword name = 'amazon' # 必须唯一 allowed_domains = ['www.amazon.cn'] # 允许域 start_urls = ['http://www.amazon.cn/'] # 如果你没有指定发送的请求地址,会默认使用只一个 custom_settings = { # 自定制配置文件,自己设置了用自己的,没有就找父类的 "BOT_NAME": 'HAIYAN_AMAZON', 'REQUSET_HEADERS': {}, } def start_requests(self): url = 'https://www.amazon.cn/s/ref=nb_sb_noss_1/461-4093573-7508641?' url+=urlencode({"field-keywords":self.keyword}) print(url) yield scrapy.Request( url, callback = self.parse_index, #指定回调函数 dont_filter = True, #不去重,这个也可以自己定制 # dont_filter = False, #去重,这个也可以自己定制 # meta={'a':1} #meta代理的时候会用 ) #如果要想测试自定义的dont_filter,可多返回结果重复的即可 def parse_index(self, response): '''获取详情页和下一页的链接''' detail_urls = response.xpath('//*[contains(@id,"result_")]/div/div[3]/div[1]/a/@href').extract() print(detail_urls) # print("%s 解析 %s",(response.url,(len(response.body)))) for detail_url in detail_urls: yield scrapy.Request( url=detail_url, callback=self.parse_detail #记得每次返回response的时候记得绑定一个回调函数 ) next_url = response.urljoin(response.xpath(response.xpath('//*[@id="pagnNextLink"]/@href').extract_first())) # 因为下一页的url是不完整的,用urljoin就可以吧路径前缀拿到并且拼接 # print(next_url) yield scrapy.Request( url=next_url, callback=self.parse_index #因为下一页也属于是索引页,让去解析索引页 ) def parse_detail(self,response): '''详情页解析''' name = response.xpath('//*[@id="productTitle"]/text()').extract_first().strip()#获取name price = response.xpath('//*[@id="price"]//*[@class="a-size-medium a-color-price"]/text()').extract_first()#获取价格 delivery_method=''.join(response.xpath('//*[@id="ddmMerchantMessage"]//text()').extract()) #获取配送方式 print(name) print(price) print(delivery_method) #上面是筛选出自己想要的项 #必须返回一个Item对象,那么这个item对象,是从item.py中来,和django中的model类似, # 但是这里的item对象也可当做是一个字典,和字典的操作一样 item = AmazonItem()# 实例化 item["name"] = name item["price"] = price item["delivery_method"] = delivery_method return item def close(spider, reason): print("结束啦")
Selectors
scray 自带的用于在回调函数中解析页面内容的组件
相关方法
xpath 方式
#1 // 与 /
#2 text
#3 extract与extract_first:从selector对象中解出内容
#4 属性:xpath的属性加前缀@
#4 嵌套查找
#5 设置默认值
#4 按照属性查找
#5 按照属性模糊查找
#6 正则表达式
#7 xpath相对路径
#8 带变量的xpath



css 方式
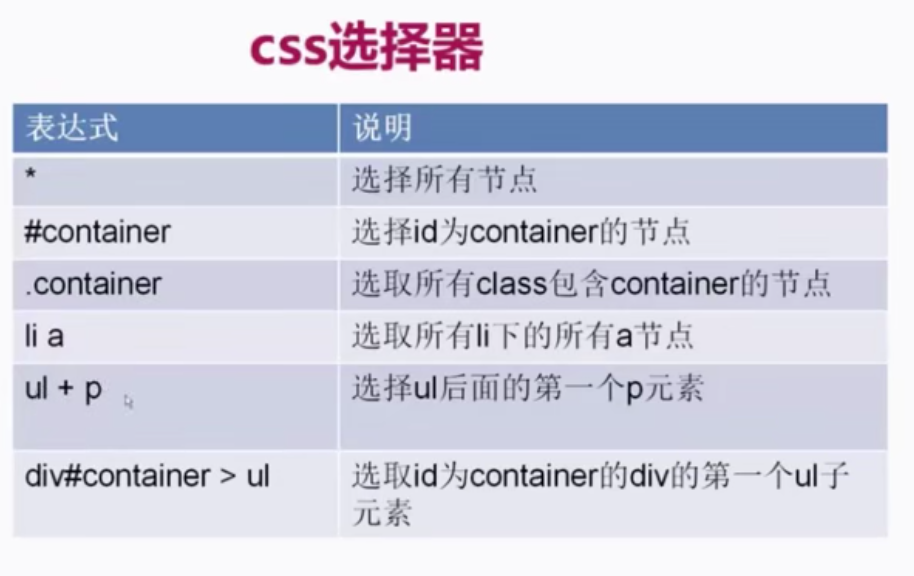

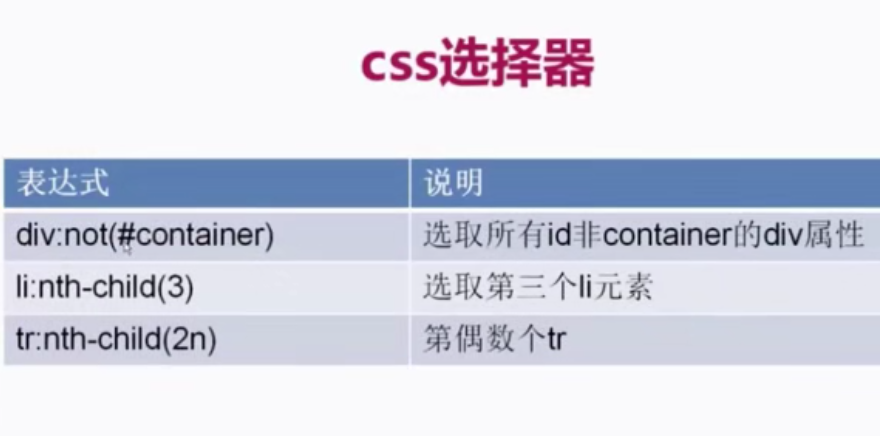
详细操作展示
response.selector.css() response.selector.xpath() 可简写为 response.css() response.xpath() #1 //与/
# // 子子孙孙 / 儿子 .// 当前往下找子子孙孙
response.xpath('//body/a/')# response.css('div a::text') >>> response.xpath('//body/a') #开头的//代表从整篇文档中寻找,body之后的/代表body的儿子 [] >>> response.xpath('//body//a') #开头的//代表从整篇文档中寻找,body之后的//代表body的子子孙孙 [<Selector xpath='//body//a' data='<a href="image1.html">Name: My image 1 <'>, <Selector xpath='//body//a' data='<a href="image2.html">Name: My image 2 <'>, <Selector xpath='//body//a' data='<a href=" image3.html">Name: My image 3 <'>, <Selector xpath='//body//a' data='<a href="image4.html">Name: My image 4 <'>, <Selector xpath='//body//a' data='<a href="image5.html">Name: My image 5 <'>] #2 text >>> response.xpath('//body//a/text()') >>> response.css('body a::text') #3、extract与extract_first:从selector对象中解出内容 >>> response.xpath('//div/a/text()').extract() ['Name: My image 1 ', 'Name: My image 2 ', 'Name: My image 3 ', 'Name: My image 4 ', 'Name: My image 5 '] >>> response.css('div a::text').extract() ['Name: My image 1 ', 'Name: My image 2 ', 'Name: My image 3 ', 'Name: My image 4 ', 'Name: My image 5 '] >>> response.xpath('//div/a/text()').extract_first() 'Name: My image 1 ' >>> response.css('div a::text').extract_first() 'Name: My image 1 ' #4、属性:xpath的属性加前缀@ >>> response.xpath('//div/a/@href').extract_first() 'image1.html' >>> response.css('div a::attr(href)').extract_first() 'image1.html' #4、嵌套查找 >>> response.xpath('//div').css('a').xpath('@href').extract_first() 'image1.html' #5、设置默认值 >>> response.xpath('//div[@id="xxx"]').extract_first(default="not found") 'not found' #4、按照属性查找 response.xpath('//div[@id="images"]/a[@href="image3.html"]/text()').extract() response.css('#images a[@href="image3.html"]/text()').extract() #5、按照属性模糊查找 response.xpath('//a[contains(@href,"image")]/@href').extract() response.css('a[href*="image"]::attr(href)').extract() response.xpath('//a[contains(@href,"image")]/img/@src').extract() response.css('a[href*="imag"] img::attr(src)').extract() response.xpath('//*[@href="image1.html"]') response.css('*[href="image1.html"]') #6、正则表达式 response.xpath('//a/text()').re(r'Name: (.*)') response.xpath('//a/text()').re_first(r'Name: (.*)') #7、xpath相对路径 >>> res=response.xpath('//a[contains(@href,"3")]')[0] >>> res.xpath('img') [<Selector xpath='img' data='<img src="image3_thumb.jpg">'>] >>> res.xpath('./img') [<Selector xpath='./img' data='<img src="image3_thumb.jpg">'>] >>> res.xpath('.//img') [<Selector xpath='.//img' data='<img src="image3_thumb.jpg">'>] >>> res.xpath('//img') #这就是从头开始扫描 [<Selector xpath='//img' data='<img src="image1_thumb.jpg">'>, <Selector xpath='//img' data='<img src="image2_thumb.jpg">'>, <Selector xpath='//img' data='<img src="image3_thumb.jpg">'>, <Selector xpa th='//img' data='<img src="image4_thumb.jpg">'>, <Selector xpath='//img' data='<img src="image5_thumb.jpg">'>] #8、带变量的xpath >>> response.xpath('//div[@id=$xxx]/a/text()',xxx='images').extract_first() 'Name: My image 1 ' >>> response.xpath('//div[count(a)=$yyy]/@id',yyy=5).extract_first() #求有5个a标签的div的id 'images'
