为了防止无良网站的爬虫抓取文章,特此标识,转载请注明文章出处。LaplaceDemon/ShiJiaqi。
http://www.cnblogs.com/shijiaqi1066/p/4631466.html
1. Fork/Join框架
fork操作的作用是把一个大的问题划分成若干个较小的问题。在这个划分过程一般是递归进行的。直到可以直接进行计算。需要恰当地选取子问题的大小。太大的子问题不利于通过并行方式来提高性能,而太小的子问题则会带来较大的额外开销。每个子问题计算完成后,可以得到关于整个问题的部分解。join操作的作用是把这些分解手机组织起来,得到完整解。
简单的说,ForkJoin其核心思想就是分治。Fork分解任务,Join收集数据。

在fork/join框架中,若某个子问题由于等待另一个子问题的完成而无法继续执行。那么处理该子问题的线程会主动寻找其他尚未运行完成的子问题来执行。这种方式减少了线程的等待时间,提高了性能。子问题中应该避免使用synchronized关键词或其他方式方式的同步。也不应该是一阻塞IO或过多的访问共享变量。在理想情况下,每个子问题的实现中都应该只进行CPU相关的计算,并且只适用每个问题的内部对象。唯一的同步应该只发生在子问题和创建它的父问题之间。

2. Fork/Join框架的主要类
一个fork/join框架之下的任务由ForkJoinTask类表示。ForkJoinTask实现了Future接口,可以按照Future接口的方式来使用。在ForkJoinTask类中之重要的两个方法fork和join。fork方法用以一部方式启动任务的执行,join方法则等待任务完成并返回指向结果。在创建自己的任务是,最好不要直接继承自ForkJoinTask类,而要继承自ForkJoinTask类的子类RecurisiveTask或RecurisiveAction类。两种的区别在于RecurisiveTask类表示的任务可以返回结果,而RecurisiveAction类不行。
简单总结:
ForkJoin主要提供了两个主要的执行任务的接口。RecurisiveAction与RecurisiveTask 。
- RecurisiveAction :没有返回值的接口。
- RecurisiveTask :带有返回值的接口。
fork/join框架任务的执行由ForkJoinTask类的对象之外,还可以使用一般的Callable和Runnable接口来表示任务。
ForkJoin要利用线程池ForkJoinPool。每个线程池都有一个WorkQueue实例。ForkJoinPool推荐查看JDK8的源码,比JDK7更利于理解。
在ForkJoinPool类的对象中执行的任务大支可以分为两类,一类通过execute、invoke或submit提交的任务;另一类是ForkJoinTask类的对象在执行过程中产生的子任务,并通过fork方法来运行。一般的做法是表示整个问题的ForkJoinTask类的对象用第一类型是提交,而在执行过程中产生的子任务并不需要进行处理,ForkJoinPool类对象会负责子任务的执行。

ForkJoinPool是ExecutorService的实现类,因此是一种特殊的线程池。使用方法与Executor框架类似。ForkJoinPool提供如下两个常用的构造器:
ForkJoinPool(int parallelism) 创建一个包含parallelism个并行线程的ForkJoinPool。
ForkJoinPool() 以Runtime.availableProcessors()方法的返回值作为parallelism参数来创建ForkJoinPool。
ForkJoinPool有如下三个方法启动线程:
使用ForkJoinPool的submit(ForkJoinTask task) 或 invoke(ForkJoinTask task) 方法来执行指定任务。其中ForkJoinTask代表一个可以并行、合并的任务。
| 客户端非fork/join调用 | 内部调用fork/join | |
| 异步执行 | execute(ForkJoinTask) | ForkJoinTask.fork |
| 等待获取结果 | invoke(ForkJoinTask) | ForkJoinTask.invoke |
| 执行,获取Future |
submit(ForkJoinTask) |
ForkJoinTask.fork(ForkJoinTask are Futures) |
ForkJoinTask是分支合并的执行任何,分支合并的业务逻辑使用者可以再继承了这个抽先类之后,在抽象方法exec()中实现。其中exec()的返回结果和ForkJoinPool的执行调用方(execute(...),invoke(...),submit(...)),共同决定着线程是否阻塞,具体请看下面的测试用例。
ForkJoinTask 是一个抽象类,它还有两个抽象子类:RecurisiveTask和RecurisiveAction。
RecurisiveTask代表有返回值的任务。RecursiveTask<T>是泛型类。T是返回值的类型。
RecurisiveAction代表没有返回值的任务。
3. 异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally()) { System.out.println(task.getException()); }
getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
4. ForkJoinPool
ForkJoinPool是Java 1.7之后新添加的一个ExecutorService实现,在java.util.concurrent中。和其他的ExecutorService一样,ForkJoinPool在提供自身特殊优势的同时也可以作为一个普通的Executor框架来使用,通过submit等方法来提交Runnable任务。
ForkJoinPool最大的特殊之处就在于其实现了工作密取(work-stealing)。
工作窃取 (work-stealing)
所谓工作窃取,即当前线程的Task已经全被执行完毕,则自动取到其他线程的Task池中取出Task继续执行。
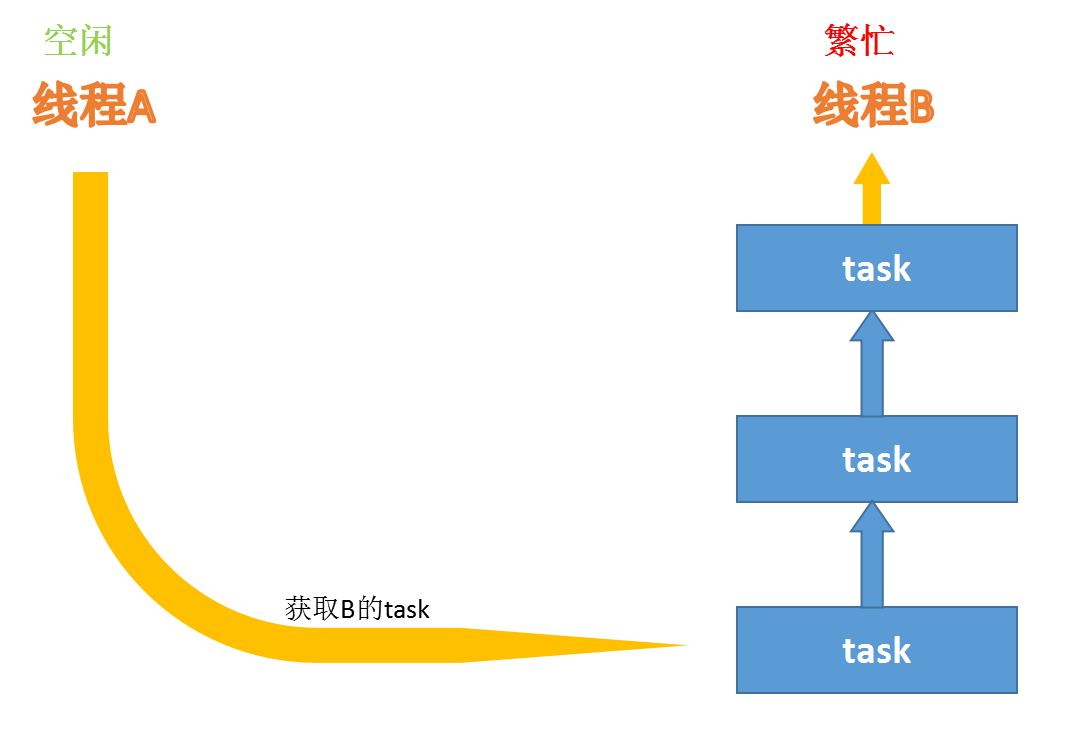
ForkJoinPool中维护着多个线程(一般为CPU核数)在不断地执行Task,每个线程除了执行自己职务内的Task之外,还会根据自己工作线程的闲置情况去获取其他繁忙的工作线程的Task,如此一来就能能够减少线程阻塞或是闲置的时间,提高CPU利用率。
实现原理
ForkJoinPool的具体实现可参考Doug Lea的论文:A Java Fork/Join Framework

ForkJoinPool中的工作线程是由ForkJoinWorkerThread类实现的,其通过维护一个双端队列(ForkJoinPool.WorkQueue)来存放Task的,这里的Task一般是ForkJoinTask的子类。每一个工作线程简单的通过以下两条原则进行活动:
- 若队列非空,则代表自己线程的Task还没执行完毕,取出Task并执行。
- 若队列为空,则随机选取一个其他的工作线程的Task并执行。
那么为了减少在对Task双端队列进行操作时的Race Condition,这里的双端队列通过维护一个top变量和一个base变量来解决这个问题。top变量类似于栈帧,当ForkJoinTask fork出新的Task或者Client从外部提交一个新的Task的ForkJoinPool时,工作线程将Task以LIFO的方式push到双端队列的队头,top维护队头的位置,可以简单理解为双端队列push的部分为一个栈。而base维护队列的队尾,当别的线程需要从本工作线程密取任务时,是从双端队列的队尾出取出任务。工作队列基于以下几个保证对队列进行操作:
- push和pop操作只会被owner线程调用。
- 只有非owner线程会调用take操作。
- pop和take操作只有在队列将要变成空(当前只有一个元素)时才会需要处理同步问题。
也就是说这个实现的双端队列将整体的同步问题转换为了一个two-party的同步问题,对于take而言我们只要提供一个简单的entry lock来保证所以其他线程的take的一致性,而对于自己owner线程的pop和push几乎不需要同步。
由于ForkJoinPool的这些特性,因此它除了适合用来实现分而治之的计算框架以外,还非常适合用来作为基于event的异步消息处理执行框架,而Akka正是将ForkJoinPool作为默认的底层ExcutorService。事实证明,ForkJoinPool在Akka这种基于消息传递的异步执行环境下能够展现出非常高的性能优势,前提是尽量减少在处理过程中的线程阻塞(如IO等待等等)。
为了防止无良网站的爬虫抓取文章,特此标识,转载请注明文章出处。LaplaceDemon/ShiJia
http://www.cnblogs.com/shijiaqi1066/p/4631466.html