代码:
import numpy as np
import cv2
from sklearn import datasets
from sklearn import model_selection
from sklearn import metrics
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
import cv2
from sklearn import datasets
from sklearn import model_selection
from sklearn import metrics
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
iris = datasets.load_iris()
print(dir(iris))
print(iris.data.shape)
print(iris.feature_names)
print(iris.target.shape)
print(np.unique(iris.target))
print(dir(iris))
print(iris.data.shape)
print(iris.feature_names)
print(iris.target.shape)
print(np.unique(iris.target))
idx = iris.target!=2
print(idx)
data = iris.data[idx].astype(np.float32)
target = iris.target[idx].astype(np.float)
print(data)
print(target)
print(idx)
data = iris.data[idx].astype(np.float32)
target = iris.target[idx].astype(np.float)
print(data)
print(target)
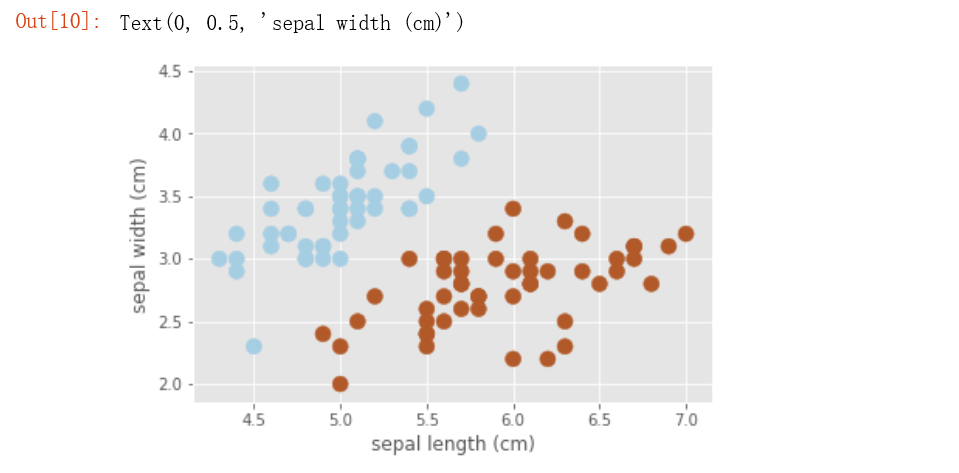
plt.scatter(data[:,0],data[:,1],c=target,cmap=plt.cm.Paired,s=100)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
x_train,x_test,y_train,y_test = model_selection.train_test_split(data,target,test_size=0.1,random_state=42)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
ir = cv2.ml.LogisticRegression_create()
ir.setTrainMethod(cv2.ml.LogisticRegression_MINI_BATCH)
ir.setMiniBatchSize(1)
ir.setIterations(100)
print(ir.get_learnt_thetas())
ir.train(np.float32(x_train),cv2.ml.ROW_SAMPLE,np.float32(y_train))
ir.get_learnt_thetas()
ir.setTrainMethod(cv2.ml.LogisticRegression_MINI_BATCH)
ir.setMiniBatchSize(1)
ir.setIterations(100)
print(ir.get_learnt_thetas())
ir.train(np.float32(x_train),cv2.ml.ROW_SAMPLE,np.float32(y_train))
ir.get_learnt_thetas()
ret,y_pred = ir.predict(x_train)
print(metrics.accuracy_score(y_train,y_pred))
ret,y_pred = lr.predict(x_test)
metrics.accuracy_score(y_test,y_pred)
print(metrics.accuracy_score(y_train,y_pred))
ret,y_pred = lr.predict(x_test)
metrics.accuracy_score(y_test,y_pred)
