HBaes介绍
HBase是什么?
- 数据库
- 非关系型数据库(Not-Only-SQL) NoSQL
- 强依赖于HDFS(基于HDFS)
- 按照BigTable论文思想开发而来
- 面向列来存储
- 可以用来存储:“结构化”数据,以及“非结构化”数据
- 一个另新手程序员不爽的地方:
- HBase在查询数据的时候,只能全表扫描(最少要按照某一个区间(行键范围)扫描)。
1、HBase的起源
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://hbase.apache.org
-- 2006年Google发表BigTable白皮书。
-- 2006年开始开发HBase。
-- 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目。
-- 2010年HBase成为Apache顶级项目。
-- 现在很多公司二次开发出了很多发行版本,你也开始使用了。
2、HBase的角色
2.1、HMaster
功能:
1) 监控RegionServer
2) 处理RegionServer故障转移
3) 处理元数据的变更
4) 处理region的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过Zookeeper发布自己的位置给客户端
2.2、RegionServer
功能:
1) 负责存储HBase的实际数据
2) 处理分配给它的Region
3) 刷新缓存到HDFS
4) 维护HLog
5) 执行压缩
6) 负责处理Region分片
组件:
1) Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2) HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
3) Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
4) MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
5) Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
1.3、HBase的架构
HBase一种是作为存储的分布式文件系统,另一种是作为数据处理模型的MR框架。因为日常开发人员比较熟练的是结构化的数据进行处理,但是在HDFS直接存储的文件往往不具有结构化,所以催生出了HBase在HDFS上的操作。如果需要查询数据,只需要通过键值便可以成功访问。
架构图如下图所示:
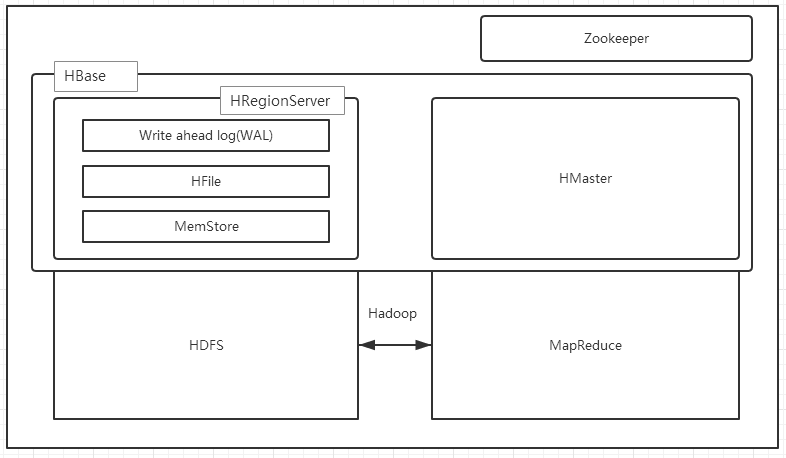
HBase内置有Zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。
一个RegionServer可以包含多个HRegion,每个RegionServer维护一个HLog,和多个HFiles以及其对应的MemStore。RegionServer运行于DataNode上,数量可以与DatNode数量一致,请参考如下架构图:

HBase部署与使用
前期准备
- 安装部署Zookeeper
- 安装部署Hadoop
- 设置时间同步
校正时间: sudo ntpdate pool.ntp.org 同步时间: sudo ntpdate linux01
安装HBase
1.解压HBase
$ tar -zxf ~/softwares/installtions/hbase-1.2.6-bin.tar.gz -C ~/modules/
2.修改配置文件
修改hbase-env.sh: export JAVA_HOME=/home/admin/modules/jdk1.8.0_131 export HBASE_MANAGES_ZK=false # export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" # export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
修改hbase-site.xml <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://linux01:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>linux01:2181,linux02:2181,linux03:2181</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/admin/modules/zookeeper-3.4.5/zkData</value> </property> </configuration>
修改regionservers: linux01 linux02 linux03
3.拷贝HBase所需依赖的Jar包
因为Hbase依赖Hadoop和zookeeper,所以hbase需要持有如上两个框架的jar包
删除HBase当前版本自带的Hadoop 的jar包和zookeeper的jar包 cd /home/admin/modules/hbase-1.2.6/lib rm -rf hadoop-* rm -rf zookeeper-3.4.6.jar 查找hadoop的jar包方法,例如将找到的jar包放到hadoop-2.7.2-hbase-jar/文件夹中 cd /home/admin/modules/hadoop-2.7.2/share/hadoop find ./ -name *.jar 导入我们目前部署的Hadoop版本的jar包,以及zookeeper的jar包 cp hadoop-2.7.2-hbase-jar/* ~/modules/hbase-1.2.6/lib/
4.将Hadoop的core-site.xml和hdfs-site.xml这两个文件软链接到hbase的conf目录下
$ ln -s ~/modules/hadoop-2.7.2/etc/hadoop/core-site.xml ~/modules/hbase-1.2.6/conf/core-site.xml $ ln -s ~/modules/hadoop-2.7.2/etc/hadoop/hdfs-site.xml ~/modules/hbase-1.2.6/conf/hdfs-site.xml
5.分发配置好的HBase安装包到其他两台机器
$ scp -r /home/admin/modules/hbase-1.2.6/ linux02:/home/admin/modules/ $ scp -r /home/admin/modules/hbase-1.2.6/ linux03:/home/admin/modules/
6.启动HBase集群
$ bin/start-hbase.sh
hbase-1.3.1,默认端口号解释
- 16000:master的默认通信地址
- 16010:master的web页面地址
- 16020:regionserver默认通信地址
- 16030:regionserver的web页面地址
hbase的简单使用
启动hbase控制台操作终端(退格:Ctrl + Backspace)
$ bin/hbase shell
创建表
hbase> create '表名','列族名'
例如: create 'student','info'
存放数据
hbase> put '表名','RowKey','列族名:列名','值'
例如:put 'student', '1001', 'info:name', 'Nick'
查看数据
hbase> scan 'student'
hbase> scan 'student',{STARTROW => '1001', STOPROW => '1003'}
(上面的操作,区间为:前闭后开)
hbase> get 'student','1001'
hbase> get 'student','1001','info'
hbase> get 'student','1001','info:name'
查看表结构
hbase> describe 'student'
删除表
先卸载表:disable 'student'
再删除:drop 'student'
HBase与Hive的集成
hive
(1) 数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
(2) 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高。
(3) 基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
HBase
(1) 数据库
是一种面向列存储的非关系型数据库。
(2) 用于存储结构化和非结构话的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
(3) 基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
集成方式
兼容性问题
目前使用的HBase版本:apache hbase 1.2.6
目前使用的hive版本:apache hive 1.2.2
坑:遇到报错 Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org.apache.hadoop.hbase.HTableDescriptor.addFamily(Lorg/apache/hadoop/hbase/HColumnDescriptor;)V
由于版本不兼容的问题,必须自己编译hive-hbase-handler-1.2.2.jar包(点击下载),把原来/home/admin/modules/apache-hive-1.2.2-bin/lib下的同名文件替换掉即可,如果不会编译,请下载cdh相关版本,它就是帮你处理兼容问题的。
1.环境准备
因为我们后续可能会在操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。
$ export HBASE_HOME=/home/admin/modules/hbase-1.2.6 $ export HIVE_HOME=/home/admin/modules/apache-hive-1.2.2-bin
2.添加jar包的软链接
cd /home/admin/modules/apache-hive-1.2.2-bin/lib ln -s $HBASE_HOME/lib/hbase-common-1.2.6.jar $HIVE_HOME/lib/hbase-common-1.2.6.jar ln -s $HBASE_HOME/lib/hbase-server-1.2.6.jar $HIVE_HOME/lib/hbase-server-1.2.6.jar ln -s $HBASE_HOME/lib/hbase-client-1.2.6.jar $HIVE_HOME/lib/hbase-client-1.2.6.jar ln -s $HBASE_HOME/lib/hbase-protocol-1.2.6.jar $HIVE_HOME/lib/hbase-protocol-1.2.6.jar ln -s $HBASE_HOME/lib/hbase-it-1.2.6.jar $HIVE_HOME/lib/hbase-it-1.2.6.jar ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.2.6.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.2.6.jar ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.2.6.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.2.6.jar
3.hive-site.xml中修改zookeeper的属性
cd /home/admin/modules/apache-hive-1.2.2-bin/lib <property> <name>hive.zookeeper.quorum</name> <value>linux01,linux02,linux03</value> <description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> <description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property>
4.导入测试
目标:建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
分步实现:
(1) 在Hive中创建表同时关联HBase
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
(2) 在Hive中创建临时中间表,用于load文件中的数据
注意:不能将数据直接load进Hive所关联HBase的那张表中
CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by ' ';
(3) 向Hive中间表中load数据
hive> load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;
(4) 通过insert命令将中间表中的数据导入到Hive关联HBase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
(5) 查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
hive> select * from hive_hbase_emp_table; hbase> scan ‘hbase_emp_table’