超详细创建流程及思路
一. 新建项目
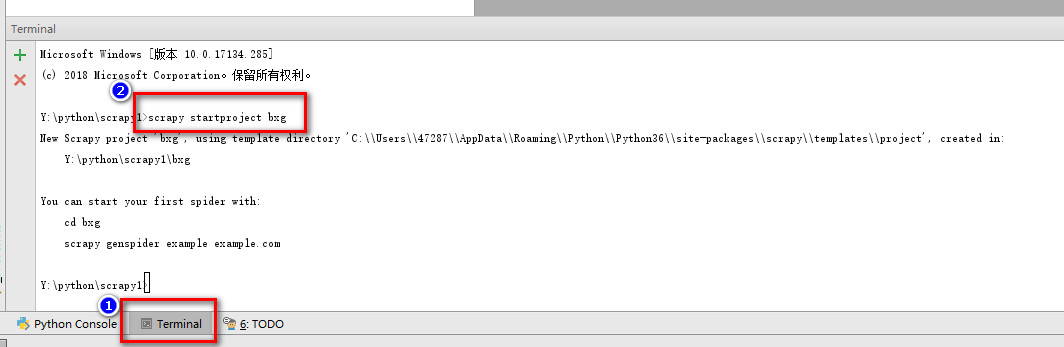
1.创建文件夹,然后在对应文件夹创建一个新的python项目
2.点击Terminal命令行窗口,运行下面的命令创建scrapy项目
scrapy startproject bxg
二、明确目标
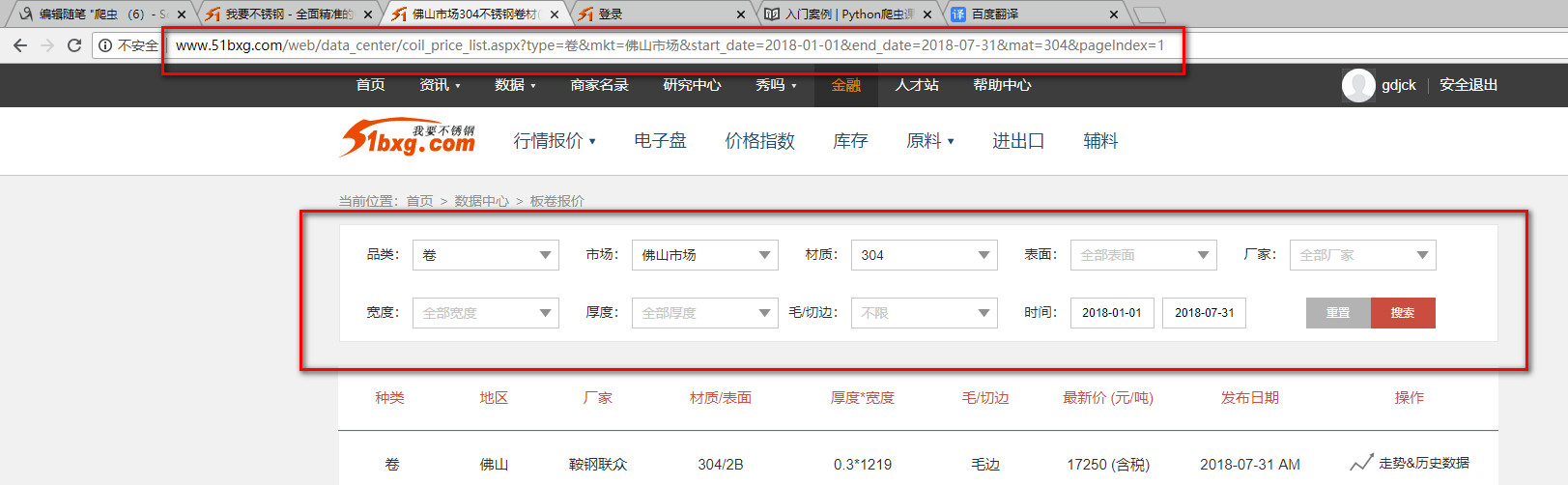
1.我们打算抓取2018年1月到8月,佛山市场各个公司关于304钢卷的价格、规格等数据;
(1)打开mySpider目录下的items.py
配置将我们需要爬取的信息
import scrapy
class BxgItem(scrapy.Item):
vender = scrapy.Field() # 厂家
texture = scrapy.Field() # 材质
thickness = scrapy.Field() # 厚度
cutting = scrapy.Field() # 切边
price = scrapy.Field() # 价格
date = scrapy.Field() # 日期
三、制作爬虫
1. 爬数据
(1)在bxg/bxg/spiders目录下输入命令,将在bxg/bxg/spiders目录下创建一个名为bxg1的爬虫,并指定爬取域的范围,注意,爬虫名字不能根项目名字一样。
scrapy genspider bxg1 "51bxg.com"
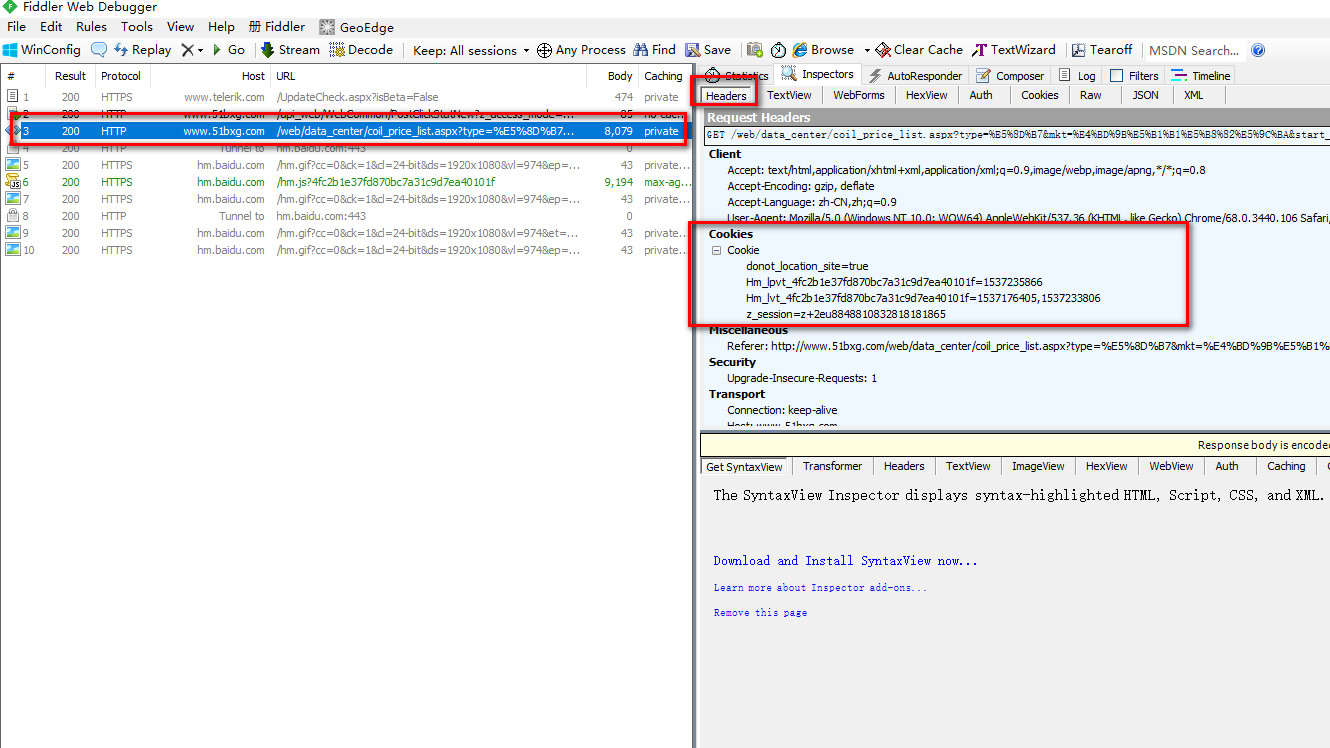
难点一,这是一个需要付费会员登陆后才能访问的搜索钢卷页面。
我们需要模拟登陆后的状态,所以我们用fidder工具获取到登陆后的cookies先。
难点二,用Xpath语法过滤获取到我们需要的数据 Xpath语法文档
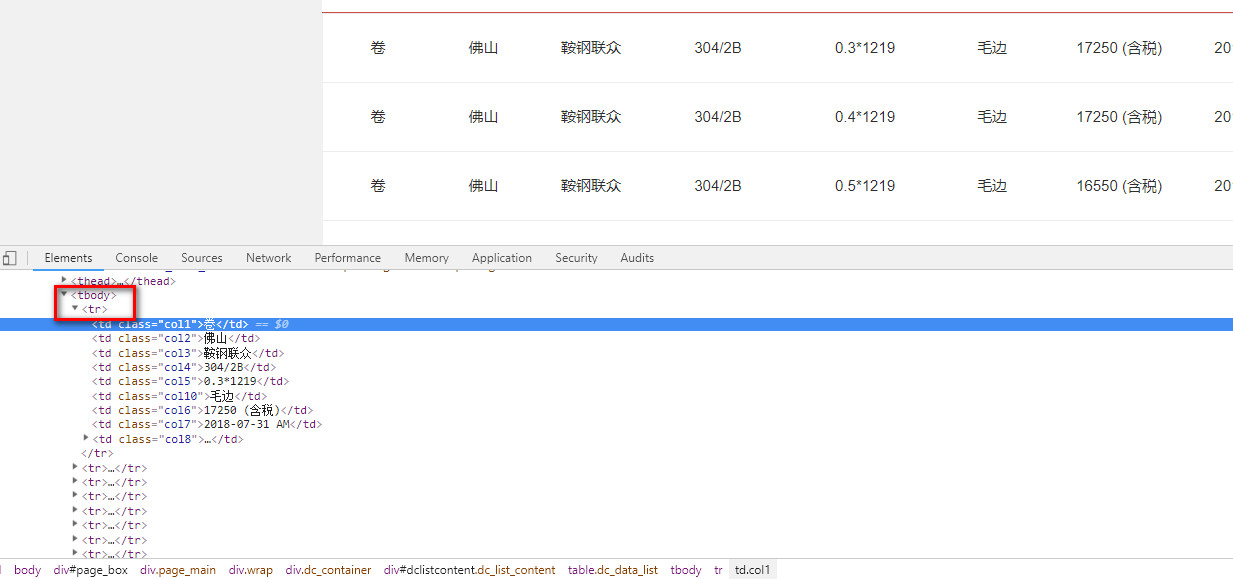
xpath("//tbody/tr")
(2)打开bxg/bxg/spiders目录里的 bxg1.py,替换成下面的代码
# -*- coding: utf-8 -*-
import scrapy
from bxg.items import BxgItem
# 实在没办法了,可以用这种方法模拟登录,麻烦一点,成功率100%
class Bxg1Spider(scrapy.Spider):
name = "bxg1"
allowed_domains = ["51bxg.com"]
url = 'http://www.51bxg.com/web/data_center/coil_price_list.aspx?type=卷&mkt=佛山市场&start_date=2018-01-01&end_date=2018-07-31&mat=J1&pageIndex='
offset = 1
start_urls = [url + str(offset)]
# 从fidder中获取到的cookies数据
cookies = {
'z_session' : 'z+2eu8848810832818181865',
'donot_location_site' : 'true',
'Hm_lvt_4fc2b1e37fd870bc7a31c9d7ea40101f' : '1533546617,1533607332',
'Hm_lpvt_4fc2b1e37fd870bc7a31c9d7ea40101f' : '1533621991'
}
def start_requests(self):
# 具体循环次数需要看搜索到的页数,这里方便测试只导出10页
while (self.offset < 10):
self.start_urls.append(self.url + str(self.offset))
self.offset += 1
for url in self.start_urls:
print(url)
yield scrapy.FormRequest(url, cookies = self.cookies, callback = self.parse_page)
def parse_page(self, response):
items = []
# 循环页面中所有对应Xpath语法过滤到的列
for each in response.xpath("//tbody/tr"):
item = BxgItem()
vender = each.xpath("td[@class='col3']/text()").extract()
texture = each.xpath("td[@class='col4']/text()").extract()
thickness = each.xpath("td[@class='col5']/text()").extract()
cutting = each.xpath("td[@class='col10']/text()").extract()
price = each.xpath("td[@class='col6']/text()").extract()
date = each.xpath("td[@class='col7']/text()").extract()
# xpath返回的是包含一个元素的列表
item['vender'] = vender[0]
item['texture'] = texture[0]
item['thickness'] = thickness[0]
item['cutting'] = cutting[0]
item['price'] = price[0]
item['date'] = date[0]
items.append(item)
# 运行脚本:scrapy crawl bxg1 -o data.csv
# 直接返回最后数据 iconv -f utf-8 -t gbk data.csv > a.csv
return items
2.取数据
(1)在bxg/bxg/spiders目录下输入命令,运行bxg1爬虫,将爬取的数据导出到data.csv文件中
scrapy crawl bxg1 -o data.csv
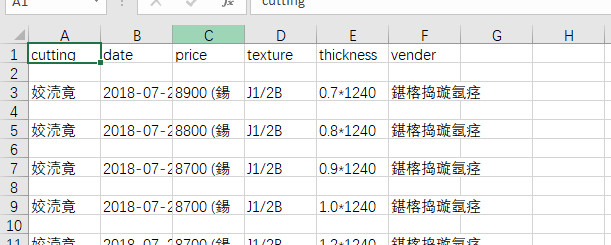
(2)发现获取的数据编码格式有点问题,出现乱码,需要对文件处理
iconv -f utf-8 -t gbk data.csv > a.csv
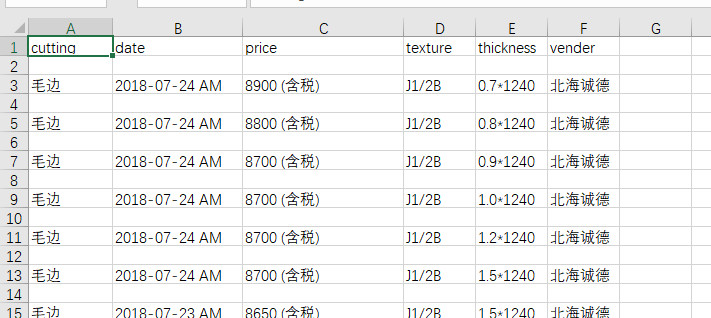
最后得到我们需要爬取的数据。