--> 博客答疑说明 链接【置顶】<--
把效果图放在前面
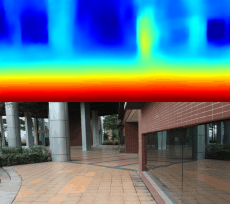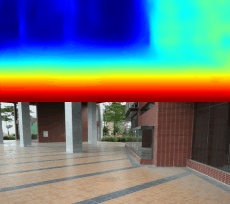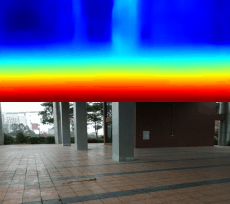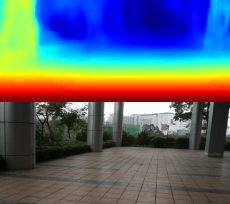
03.28
handle_motion False
architecture simple
joint_encoder False
depth_normalization True
compute_minimum_loss True
从头训练,没有任何数据增强
2019年5月18日10:23 公布了我自己写的代码,很粗糙的版本:
===============================
2019年3月22日13:20:38
论文名:
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning
from Monocular Videos
代码: https://github.com/tensorflow/models/tree/master/research/struct2depth
看论文效果,说是可以处理运动区域,甚至计算出面前的汽车的移动速度。
对tensorflow不熟,算是一边学tensorflow,一边看这个算法。
另外,jupyter notebook是个好东西,可以自己给自己写教程。。。
最后发现这个库的代码根本不完善!!!
说是可以预测移动的物体,但是:
Similar to the ego-motion model, it takes an RGB image sequence as input,
but this time complemented by pre-computed instance segmentation masks.
也就是先做了实例分割。
https://github.com/tensorflow/models/issues/6173
他们先用mask-rcnn在另一个数据集上训练了实例分割,生成了X-seg.png
用align.py对准后,生成了 X-fseg.png 图片。
这就有点死循环了,我还指望着深度估计能够提升语义分割和动态场景的处理的效果呢,结果这。。。
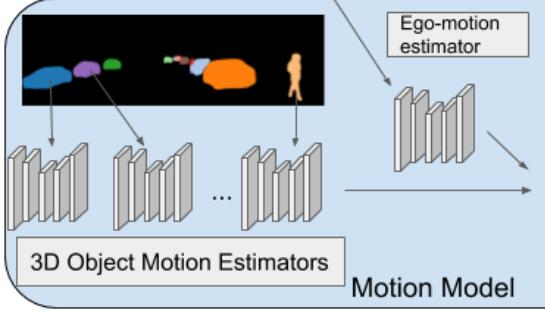
这个流程图里头,用于训练的也是实例分割图片,暗示这个网络就算处理移动物体,也是训练
过的类别才能处理。
在readme里头也不清清楚楚的写出来。。。
gen_data部分,针对 city 数据集和 kitti 数据集操作不一样。
因为要用align.py比对并产生fseg图片,city数据集有标注好的实例分割图片,
kitti没有,然而我没下city数据集。。。然后我就跳过handle_motion部分的代码了。
不过这个库本身已经包含了DDVO的深度正则化的步骤在里头了。
2019年3月26日19:13:56
不处理移动物体的版本终于用pytorch重写完了,重点重写了建立loss的部分,loss之前的部分
沿用sfmlearner的代码。还得再花几天仔细消化。
因为原始的代码里头是处理移动物体的,所以连 explainability_mask 都省掉了,只有一个
warp mask来帮助计算误差,其实sfmlearner里头也需要一个warp mask。
还感觉到应该专门弄一个 seq_length x scale_num 的矩阵,代码看着太啰嗦了。
2019年3月28日10:43:11
1600张图片跑了94个epoch,效果图就是文章最上面的gif
这样的数据量,这样的训练次数,弄出这个效果我很满意,哈哈哈!
而且没上finetune,后面再把finetune部分改写成pytorch。
碰到一个 tensorflow 挂起的问题,还不报错,tf 真是难以调试,真难用。
2019年3月29日17:31:12
文章里的 finetune 看起来就像在相邻的几帧上做过拟合。。。
2019年3月30日11:07:04
想了想,数据集很小并不能保证可以 过拟合出想要的效果,反而会因为解空间的约束太少,
搞出一个不好的效果。
本来是想预测出一个深度图,给弱监督语义分割用的,再结合三维重建,重建出特定种类
目标物的三维点云出来供后续使用的,看来还是要加强深度估计的效果和泛化能力。
2019年4月2日19:19:49
看了点语义分割的东西,了解了下CRFs,deeplab系列的分割算法。
刚开始还在想用CRFs让预测出来的深度图更sharp一点,然而deeplab V3后都把CRFs去掉了。
不如直接把deeplab V3前面的结构拿过来生成视差图?搞不好还可以很好的和语义分割结合起来。
然后我看到了几篇CRFs做深度估计的文章。。。比如 CRFasRNN 。。。
2019年4月4日09:09:01
找到一个dilated resnet的语义分割库,看到一个多任务学习 multi task learning 的概念。
深度估计 和 语义分割 肯定是耦合在一起的。
2019年4月9日09:56:18
找了一些depth fusion,三维重建的东西。
https://github.com/andyzeng/tsdf-fusion-python
想起了以前做 ptychography 成像的时候,有一个大的图像要恢复,但是算法只能
一次优化一小块区域,这个时候就要利用好overlap部分,但是前提是知道position。
准备先用slam的方式算出pose,舍弃掉sfmlearner中姿态估计的部分,深度估计还是
用这些网络来算。充分利用两张深度图之间的重叠部分,加速收敛。
2019年5月23日09:19:48
https://zhuanlan.zhihu.com/p/66281890 MixMatch
看到这篇文章想到了一个很鸡肋的loss ...
同一张图片加不同的HSV抖动,或者其他增强手段,在同一个像素位置处预测出来的深度应该
是不变的。虽然之前有数据增强,但是没有显式的把这一loss表达出来。
这个loss如此好表达,以致于可以轻松的在训练完后再加一个这样的loss去训练模型,不知道效果如何。
2020年09月11日09:09:11
去年以来一直在玩激光slam,有些看法已经改变了,以前坚定的站vslam,认为激光成本很高不能落地。
在自己玩过机械激光雷达和大疆的激光雷达后,对视觉slam不是那么坚定了,两种slam还是可以互相补充的。
借用激光slam中的概念,既可以用scan-to-scan的方式计算loss,也可以用scan-to-map的方式计算loss。
甚至把回环检测融入到训练过程中。
应该已经有了类似的论文和算法,这段时间没空去追踪较新的论文。