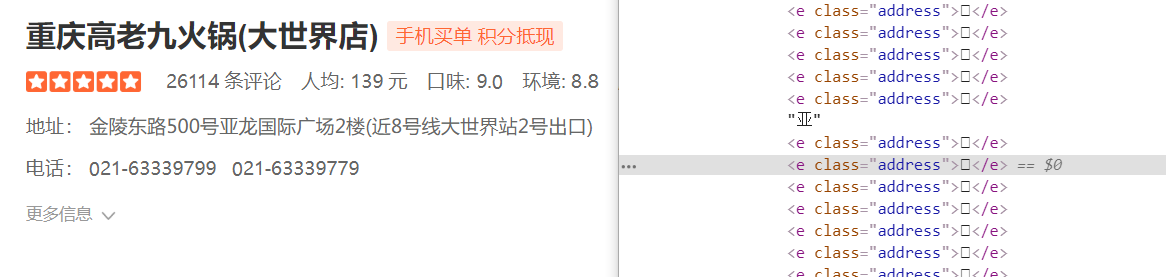
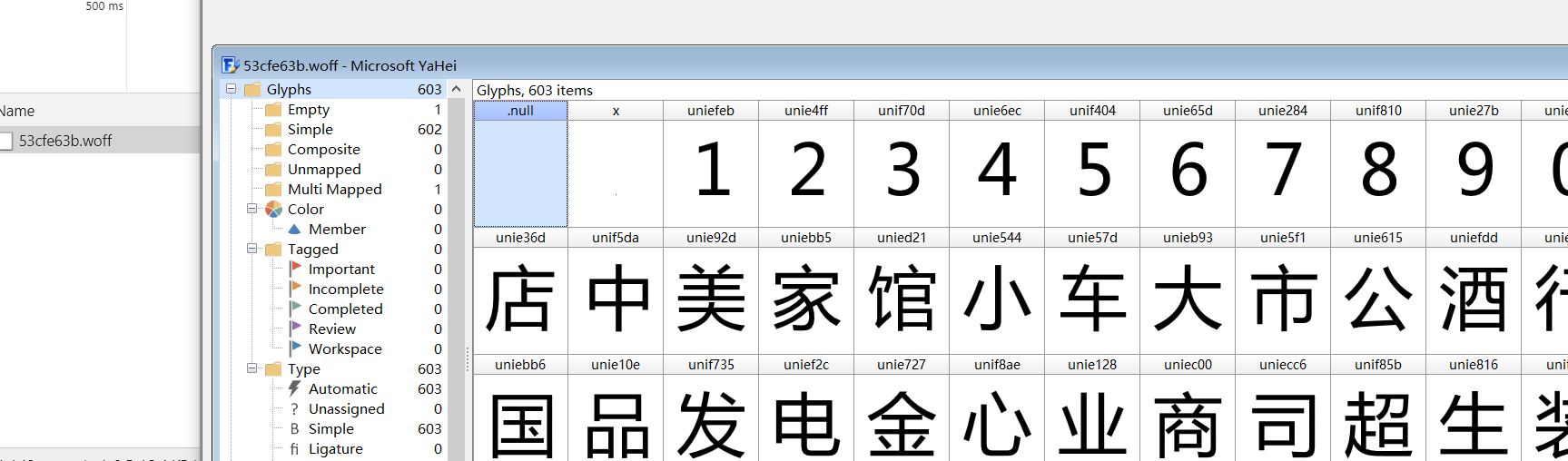
地址:http://www.dianping.com/shop/9964442
好多字没了,替代的是<x class="xxx"></x>这种css标签
定位到位置

找到文字

SVG

svg可以写字,xy是相对svg标签的坐标,单位px

textPath
用xlink:href标记文字路径,就是文字排列方向,文字按方向对齐
<path id="my_path" d="M 20,20 C 40,40 80,40 100,20" fill="transparent" /> <text> <textPath xlink:href="#my_path">This text follows a curve.</textPath> </text>
d内的参数:
M = moveto
L = lineto
H = horizontal lineto
V = vertical lineto
C = curveto
S = smooth curveto
Q = quadratic Bézier curve
T = smooth quadratic Bézier curveto
A = elliptical Arc
Z = closepath
用了M和H,M是xy坐标,H是水平线表示文字方向水平方向。
参考:https://cloud.tencent.com/developer/section/1423872
1.找css
2.找svg
3.得到css的坐标,在svg里找到字
4.用字替换标签
代码:
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}
r=requests.get("http://www.dianping.com/shop/9964442",headers=headers)
css_url="http:"+re.findall('href="(//s3plus.meituan.net.*?svgtextcss.*?.css)',r.text)[0]
css_cont=requests.get(css_url,headers=headers)
得到css
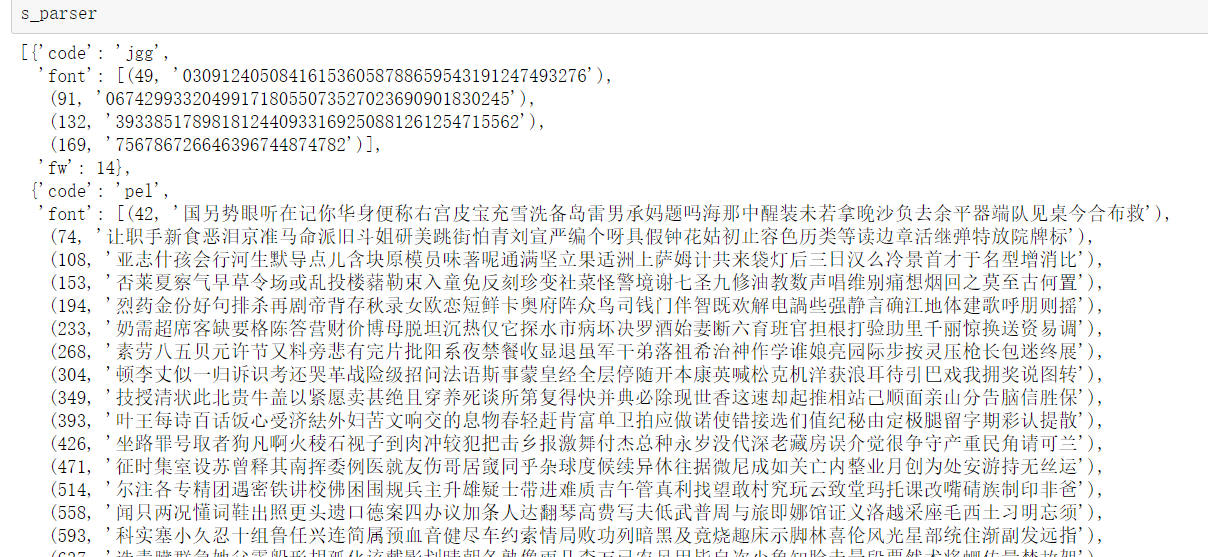
svg_url=re.findall('class^="(w+)".*?(//s3plus.*?.svg)',css_cont.text) s_parser=[] for c,u in svg_url: f,w=svg_parser("http:"+u) s_parser.append({"code":c,"font":f,"fw":w})
得到svg
解析svg结果
def svg_parser(url): r=requests.get(url,headers=headers) font=re.findall('" y="(d+)">(w+)</text>',r.text,re.M) if not font: font=[] z=re.findall('" textLength.*?(w+)</textPath>',r.text,re.M) y=re.findall('id="d+" d="w+s(d+)sw+"',r.text,re.M) for a,b in zip(y,z): font.append((a,b)) width=re.findall("font-size:(d+)px",r.text)[0] new_font=[] for i in font: new_font.append((int(i[0]),i[1])) return new_font,int(width)
结果里有些字没解析出来,发现有两种文字形式
一种带路径的textPath,行数y在d=“xx”的M里
另一种text,行数在text标签里y的值,需要分别处理
返回一个元组包含y的参考值和字体内容,fw是字体宽度
css_list = re.findall('(w+){background:.*?(d+).*?px.*?(d+).*?px;', ' '.join(css_cont.text.split('}'))) css_list = [(i[0],int(i[1]),int(i[2])) for i in css_list]
从css找到所有坐标
def font_parser(ft): for i in s_parser: if i["code"] in ft[0]: font=sorted(i["font"]) if ft[2] < int(font[0][0]): x=int(ft[1]/i["fw"]) return font[0][1][x] for j in range(len(font)): if (j+1) in range(len(font)): if(ft[2]>=int(font[j][0]) and ft[2]< int(font[j+1][0])): x=int(ft[1]/i["fw"]) return font[j+1][1][x]
根据class坐标在svg找到具体文字
y是文字所在行数,x字体宽度
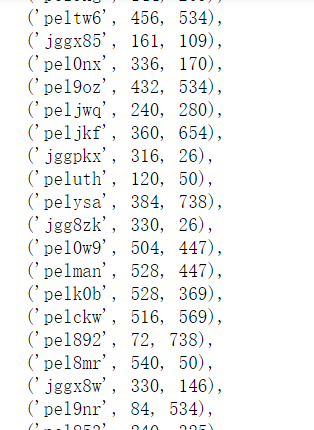
replace_dic=[] for i in css_list: replace_dic.append({"code":i[0],"word":font_parser(i)})
根据坐标,找到映射关系

rep=r.text for i in range(len(replace_dic)): if replace_dic[i]["code"] in rep: a=re.findall(f'<w+sclass="{replace_dic[i]["code"]}"></w+>',rep)[0] rep=rep.replace(a,replace_dic[i]["word"])
<x class="xxx"></x>标签全局替换
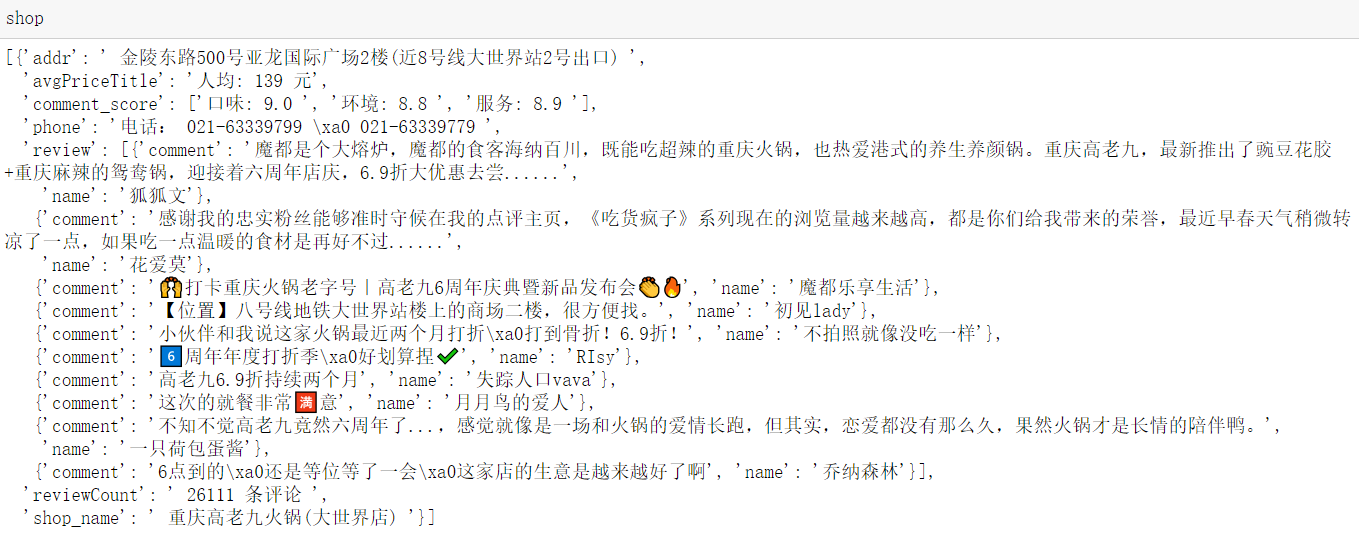
shop=[] shop_name=tree.xpath('//h1[@class="shop-name"]//text()')[0] reviewCount=tree.xpath('//span[@id="reviewCount"]//text()')[0] avgPriceTitle=tree.xpath('//span[@id="avgPriceTitle"]//text()')[0] comment_score=tree.xpath('//span[@id="comment_score"]//text()') comment_score=[i for i in comment_score if i!=" "] addr=tree.xpath('//span[@itemprop="street-address"]/text()')[0] phone=tree.xpath('//p[@class="expand-info tel"]//text()') phone=phone[1]+phone[2] review=[] for li in lis: name=li.xpath('.//a[@class="name"]/text()')[0] comment=li.xpath('.//p[@class="desc"]/text()')[0] review.append({"name":name,"comment":comment}) shop.append({ "shop_name":shop_name, "reviewCount":reviewCount, "avgPriceTitle":avgPriceTitle,"addr":addr, "phone":phone, "review":review })
替换后店名评论数评论评分电话地址等结果
用的库

后来发现不只使用一种反爬,还有自定义字体