场景:有两张表,一张用户表(user),交易表(transactions)。两张表的字段如下:

两份表数据做个左连接,查询出(商品名,地址)这种格式。
这样就是相当于交易表是左表,不管怎么样数据都要保留,然后从右边里面查出来弥补左表。
效果如下:

思路:写两个map,把两个表的数据都读进来,在reduce端进行连接,然后按照格式要求写出去。
(1)map1:读取transaction文件,封装为:
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context)
throws IOException, InterruptedException {
String lines=value.toString();
String[] args=lines.split(" ");
String productID=args[1];
String userID=args[2];
//把outPutKey加了一个2,这么做的目的是,后续在reduce端,聚合时,这个数据能够晚点到达。
outPutKey.set(userID, "2");
outPutValue.set("P", productID);
context.write(outPutKey, outPutValue);
}
(2)map2:读取user文件,封装为:
static class map2 extends Mapper<LongWritable, Text,PairOfStrings,PairOfStrings>
{
PairOfStrings outPutKey=new PairOfStrings();
PairOfStrings outPutvalue=new PairOfStrings();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[] args=line.split(" ");
String userID=args[0];
String locationID=args[1];
//把outPutKey加了一个1,这么做的目的是,后续在reduce端,聚合时,这个数据能够早于transaction文件里面的数据到达。
outPutKey.set(userID, "1");
outPutvalue.set("L", locationID);
context.write(outPutKey, outPutvalue);
}
(3)reduce:把map端的数据要根据用户ID分区,相同的用户ID写入到同一个分区,进而写入到同一个Reduce分区,然后在Reduce中根据PairOfStrings这个类的自己的排序规则对数据排序。因为前面对key做了处理(加了1,2),所以是用户的地址这些信息先到达reduce。,然后根据不同的分组,把数据写出来。
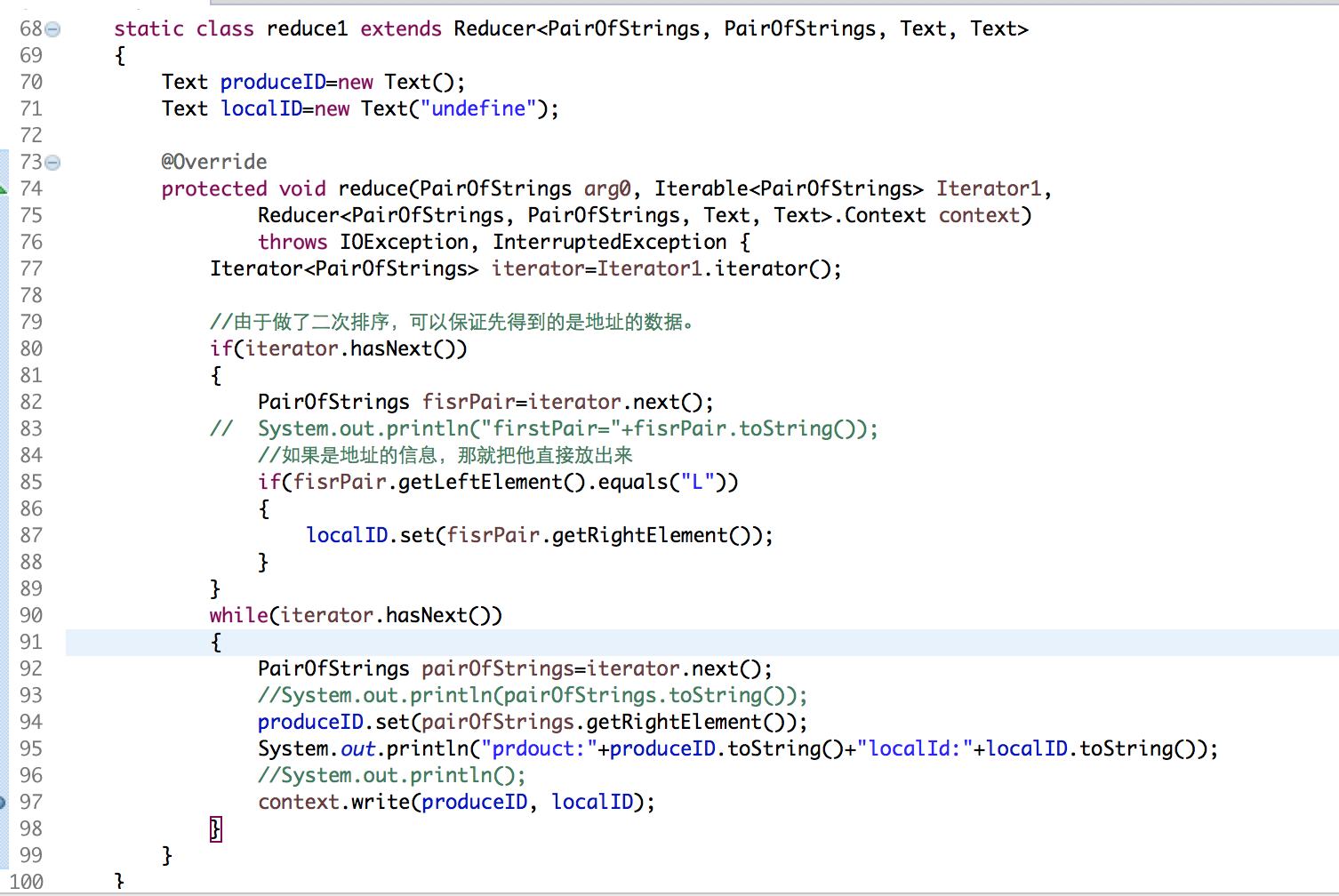
总的代码结构:

LeftCmain:
package com.guigu.left; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.MultipleInputs; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import edu.umd.cloud9.io.pair.PairOfStrings; public class LeftCmain { //读取transaction文件 static class map1 extends Mapper<LongWritable, Text, PairOfStrings,PairOfStrings> { PairOfStrings outPutKey=new PairOfStrings(); PairOfStrings outPutValue=new PairOfStrings(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context) throws IOException, InterruptedException { String lines=value.toString(); String[] args=lines.split(" "); String productID=args[1]; String userID=args[2]; outPutKey.set(userID, "2"); outPutValue.set("P", productID); context.write(outPutKey, outPutValue); } } //读取user文件 static class map2 extends Mapper<LongWritable, Text,PairOfStrings,PairOfStrings> { PairOfStrings outPutKey=new PairOfStrings(); PairOfStrings outPutvalue=new PairOfStrings(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, PairOfStrings, PairOfStrings>.Context context) throws IOException, InterruptedException { String line=value.toString(); String[] args=line.split(" "); String userID=args[0]; String locationID=args[1]; outPutKey.set(userID, "1"); outPutvalue.set("L", locationID); context.write(outPutKey, outPutvalue); } } /** * 这个的关键点在于,取出的数据:要求先取出地址的数据。 * @author Sxq * */ static class reduce1 extends Reducer<PairOfStrings, PairOfStrings, Text, Text> { Text produceID=new Text(); Text localID=new Text("undefine"); @Override protected void reduce(PairOfStrings arg0, Iterable<PairOfStrings> Iterator1, Reducer<PairOfStrings, PairOfStrings, Text, Text>.Context context) throws IOException, InterruptedException { Iterator<PairOfStrings> iterator=Iterator1.iterator(); //由于做了二次排序,可以保证先得到的是地址的数据。 if(iterator.hasNext()) { PairOfStrings fisrPair=iterator.next(); // System.out.println("firstPair="+fisrPair.toString()); //如果是地址的信息,那就把他直接放出来 if(fisrPair.getLeftElement().equals("L")) { localID.set(fisrPair.getRightElement()); } } while(iterator.hasNext()) { PairOfStrings pairOfStrings=iterator.next(); //System.out.println(pairOfStrings.toString()); produceID.set(pairOfStrings.getRightElement()); System.out.println("prdouct:"+produceID.toString()+"localId:"+localID.toString()); //System.out.println(); context.write(produceID, localID); } } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(LeftCmain.class); job.setMapperClass(map1.class); job.setReducerClass(reduce1.class); job.setMapOutputKeyClass(PairOfStrings.class); job.setMapOutputValueClass(PairOfStrings.class); job.setOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setSortComparatorClass(PairOfStrings.Comparator.class); // 在Reduce端设置分组,使得同一个用户在同一个组,然后做拼接。 job.setGroupingComparatorClass(SecondarySortGroupComparator.class); // 设置分区 job.setPartitionerClass(SecondarySortParitioner.class); // job.setOutputFormatClass(SequenceFileOutputFormat.class); Path transactions=new Path("/Users/mac/Desktop/transactions.txt"); MultipleInputs.addInputPath(job,transactions,TextInputFormat.class,map1.class); MultipleInputs.addInputPath(job,new Path("/Users/mac/Desktop/user.txt"), TextInputFormat.class,map2.class); FileOutputFormat.setOutputPath(job, new Path("/Users/mac/Desktop/flowresort")); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
SecondarySortGroupComparator:
package com.guigu.left; import org.apache.hadoop.io.DataInputBuffer; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; import com.book.test1.CompositeKey; import edu.umd.cloud9.io.pair.PairOfStrings; /** * 不同分区的组聚合时,可以按照我们要的顺序来排列 * @author Sxq *WritableComparator */ public class SecondarySortGroupComparator extends WritableComparator { public SecondarySortGroupComparator() { super(PairOfStrings.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { PairOfStrings v1=(PairOfStrings)a; PairOfStrings v2=(PairOfStrings)b; return v1.getLeftElement().compareTo(v2.getLeftElement()); } }
SecondarySortParitioner:
package com.guigu.left; import org.apache.hadoop.mapreduce.Partitioner; import edu.umd.cloud9.io.pair.PairOfStrings; /** * * @author Sxq * */ public class SecondarySortParitioner extends Partitioner<PairOfStrings, Object>{ @Override public int getPartition(PairOfStrings key, Object value, int numPartitions) { return (key.getLeftElement().hashCode()&Integer.MAX_VALUE)%numPartitions; } }
运行结果:
