我的目的:
示例:
2012,01,01,35
2011,12,23,-4
2012,01,01,43
2012,01,01,23
2011,12,23,5
2011,4,1,2
2011,4,1,56
结果:
201112 -4,5
20114 2,56
201201 23,35,43
正式实现:
代码结构:

分为以下的步骤:
(1)编写封装类,把上述的字段分装进去。
package com.book.test; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; public class DataTemperaturePair implements Writable,WritableComparable<DataTemperaturePair> { //年-月 private Text yearMoth=new Text(); //温度 private IntWritable temperature=new IntWritable(); //日期 private Text day=new Text(); public DataTemperaturePair() { } public Text getYearMoth() { return yearMoth; } public Text getDay() { return day; } public void setDay(Text day) { this.day = day; } public void setYearMoth(Text yearMoth) { this.yearMoth = yearMoth; } public IntWritable getTemperature() { return temperature; } public void setTemperature(IntWritable temperature) { this.temperature = temperature; }
//这俩个函数是必须要写的,不然在reduce端,这个分装类拿不到 public void readFields(DataInput input) throws IOException { String readuf=input.readUTF(); int readuf3=input.readInt(); String readuf2=input.readUTF(); this.yearMoth=new Text(readuf); this.temperature=new IntWritable(readuf3); this.day=new Text(readuf2); }
//这俩个函数是必须要写的,不然在reduce端,这个分装类拿不到
public void write(DataOutput output) throws IOException
{ output.writeUTF(yearMoth.toString()); output.writeInt(temperature.get()); output.writeUTF(day.toString()); }
public int compareTo(DataTemperaturePair that) {
int compareValue=this.yearMoth.compareTo(that.yearMoth);
if(compareValue==0) {
compareValue=temperature.compareTo(that.temperature);
}
//升序
return compareValue;
}
(2)编写分区器
为什么要自定义这个分区器呢?
因为我们的key是自己写的一个对象,我们想按照这个对象里面的Yearmoth来分到一个区。
package com.book.test; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * 自定义的分区器 * @author Sxq * */ public class DataTemperaturePartition extends Partitioner<DataTemperaturePair, NullWritable> { @Override public int getPartition(DataTemperaturePair pair, NullWritable text, int numberOfPartotions) { return Math.abs(pair.getYearMoth().hashCode()%numberOfPartotions); } }
(3)编写比较器
决定数据分入到哪个分组
package com.book.test; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class DataTemperatureGroupingComparator extends WritableComparator { public DataTemperatureGroupingComparator() { super(DataTemperaturePair.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { DataTemperaturePair v1=(DataTemperaturePair)a; DataTemperaturePair v2=(DataTemperaturePair)b; return v1.getYearMoth().compareTo(v2.getYearMoth()); } }
(4)写驱动类
package com.book.test; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.guigu.shen.flowsun.FlowCountSort;
public class Cmain { static class mapper1 extends Mapper<LongWritable,Text, DataTemperaturePair, IntWritable> { DataTemperaturePair dataTemperaturePair=new DataTemperaturePair(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, DataTemperaturePair, IntWritable>.Context context) throws IOException, InterruptedException { String valuestring=value.toString(); String[] lines=valuestring.split(","); String yymm=lines[0]+lines[1]; dataTemperaturePair.setYearMoth(new Text(yymm)); IntWritable temparature=new IntWritable(Integer.valueOf(lines[3])); dataTemperaturePair.setTemperature(temparature); dataTemperaturePair.setDay(new Text(lines[2])); context.write(dataTemperaturePair, temparature); } } static class reduce1 extends Reducer<DataTemperaturePair, IntWritable, Text, Text> { @Override protected void reduce(DataTemperaturePair KEY, Iterable<IntWritable> VALUE, Context context) throws IOException, InterruptedException { StringBuffer sortedTemperaturelist=new StringBuffer(); Iterator<IntWritable> iterator=VALUE.iterator(); while(iterator.hasNext()) { sortedTemperaturelist.append(iterator.next()); sortedTemperaturelist.append(","); } context.write(KEY.getYearMoth(), new Text(sortedTemperaturelist.toString())); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setJarByClass(Cmain.class); job.setMapperClass(mapper1.class); job.setReducerClass(reduce1.class); job.setMapOutputKeyClass(DataTemperaturePair.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setGroupingComparatorClass(DataTemperatureGroupingComparator.class); job.setPartitionerClass(DataTemperaturePartition.class); //指定输入的数据的目录 FileInputFormat.setInputPaths(job, new Path("/Users/mac/Desktop/temperature.txt")); FileOutputFormat.setOutputPath(job, new Path("/Users/mac/Desktop/flowresort")); boolean result=job.waitForCompletion(true); System.exit(result?0:1); } }
结果:
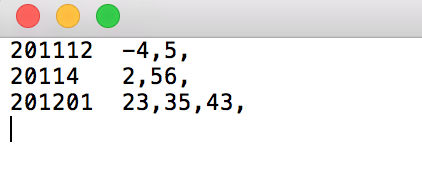
成功了