项亮老师在其所著的《推荐系统实战》中写道:
-
基于用户的协同过滤算法(这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。)
-
基于物品的协同过滤算法(这种算法给用户推荐和他之前喜欢的物品相似的物品。)
协同过滤推荐基于这样的假设:为用户找到他真正感兴趣的内容的方法是,首先找与他兴趣相似的用户,然后将这些用户感兴趣的东西推荐给该用户。所以该推荐技术最大的优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影等,并能发现用户潜在的兴趣点。协同过滤推荐算法主要是利用用户对项目的评分数据,通过相似邻居查询,找出与当前用户兴趣最相似的用户群,根据这些用户的兴趣偏好为当前用户提供最可能感兴趣的项目推荐列表。为更进一步地说明协同过滤推荐算法的推荐原理,本文以用户对电影的推荐为例进行阐述。表1 是用户对电影评分数据的一个简单矩阵的例子,其中每一行代表一个用户,每一列代表一部电影,矩阵中的元素表示用户对所看电影的评分,评分值一般是从1到5 的整数,评分值越大表明用户喜欢该电影。
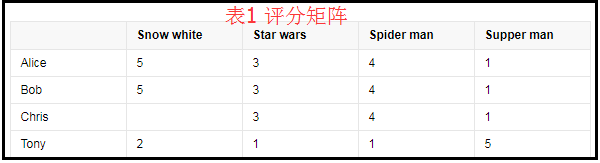
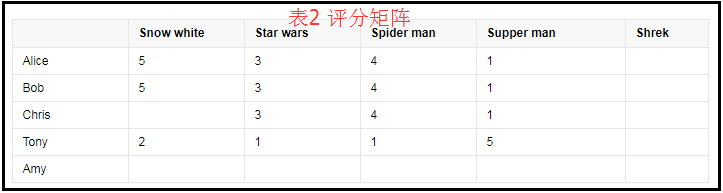
对表1 中的数据利用协同过滤推荐算法,系统查找到用户Alice、Bob 和Chris 具有相似的兴趣爱好,因为他们对后3 部电影的评分相同,那么系统会推荐电影Snow white 给Chris,因为与其兴趣偏好相似的用户Alice 和Bob 对该电影的评分值较高。在表2 中,对于新用户Amy,没有评分信息,根据协同过滤推荐算法,无法根据评分信息查找与其兴趣偏好相似的用户,所以系统无法为该用户推荐电影,同样对于新电影Shrek,因缺乏评分信息系统无法感知它的存在,所以也无法将其推荐出去。这就是协同过滤推荐算法所存在的新用户和新项目问题。
【Reference】
1. 《推荐系统实战》
推荐系统中的矩阵分解总结(https://blog.csdn.net/qq_19446965/article/details/82079367?tdsourcetag=s_pctim_aiomsg)
推荐系统:协同过滤collaborative filtering(https://blog.csdn.net/pipisorry/article/details/51788955/?tdsourcetag=s_pctim_aiomsg)