人的理想志向往往和他的能力成正比。
其实整个需求呢,就是题目。2018-08-16
需求的结构图:
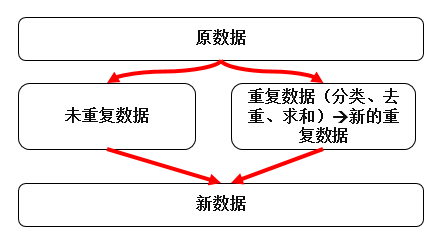
涉及的包有:pandas、numpy
1、导入包:


import pandas as pd
import numpy as np
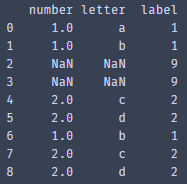
2、构造DataFrame,里面包含三种数据类型:int、null、str
data = {"number":[1,1,np.nan,np.nan,2,2,1,2,2],
"letter":['a','b',np.nan,np.nan,'c','d','b','c','d'],
"label":[1,1,9,9,2,2,1,2,2]}
dataset1 = pd.DataFrame(data) #初始化DataFrame 得到数据集dataset1
print(dataset1)
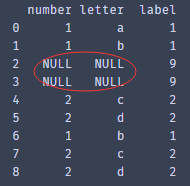
3、空值填充
由于数据集里含有空值,为了能够对后面重复数据进行求和,则需要对空值进行填充
dataset = dataset1.fillna("NULL") print(dataset)
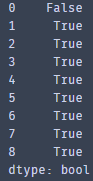
4、利用duplicated()函数和drop_duplicates()函数对数据去重
首先,利用duplicated()函数按列名'letter'和' number '取重复行,其返回的是bool类型,若为重复行则true,反之为false
duplicate_row = dataset.duplicated(subset=['letter',' number '],keep=False) print(duplicate_row)
然后通过bool值取出重复行的数据
duplicate_data = dataset.loc[duplicate_row,:] print(duplicate_data)
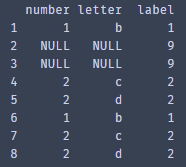
再然后根据'letter',' number '对重复数据进行分类,在该前提下并对重复数据的’label’进行求和,且重置索引(对后文中的赋值操作有帮助)
duplicate_data_sum = duplicate_data.groupby(by=['letter',' number ']).agg({' label ':sum}).reset_index(drop=True) Print(duplicate_data_sum)

取出重复数据中的一个,例如:1,1,2,2——>1,2
对drop_duplicates指定列:subset=['letter',' number '],保留第一条重复的数据:keep="first"
duplicate_data _one= duplicate_data.drop_duplicates(subset=['letter',' number '] ,keep="first").reset_index(drop=True) Print(duplicate_data)
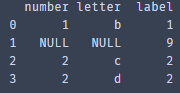
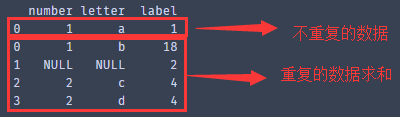
获取不重复的数据,指定列subset=['letter',' number ',' label '],不保留重复数据:keep=False
no_duplicate = dataset.drop_duplicates(subset=['letter',' number ',' label '] ,keep=False) Print(no_duplicate)
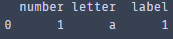
将对重复值的’label’求和,并赋值给“重复值中的一个”,得到新的”新重复值中的一个
duplicate_data _one ["label"] = duplicate_data_sum ['label'] #前面需要重置索引 print(duplicate_data_one)
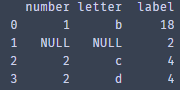
最后,拼接”新重复值中的一个”和不重复的数据
Result = pd.concat([no_duplicate,duplicate_data _one])
Print(result)
5、全体代码:
1 import pandas as pd 2 import numpy as np 3 4 #构造DataFrame 5 data = {"number":[1,1,np.nan,np.nan,2,2,1,2,2], 6 "letter":['a','b',np.nan,np.nan,'c','d','b','c','d'], 7 "label":[1,1,9,9,2,2,1,2,2]} 8 dataset1 = pd.DataFrame(data) 9 10 #空值填充 11 dataset = dataset1.fillna("NULL") 12 #得到重复行的索引 13 duplicate_row = dataset.duplicated(subset=['letter','number'],keep=False) 14 #得到重复行的数据 15 duplicate_data = dataset.loc[duplicate_row,:] 16 #重复行按''label''求和 17 duplicate_data_sum = duplicate_data.groupby(by=['letter','number']).agg({'label':sum}).reset_index(drop=True) 18 19 #得到唯一的重复数据 20 duplicate_data_one= duplicate_data.drop_duplicates(subset=[ 21 'letter','number'],keep="first").reset_index(drop=True) 22 #获得不重复的数据 23 no_duplicate = dataset.drop_duplicates(subset=['letter','number','label'] 24 ,keep=False) 25 #把重复行按"label"列求和的"label"列赋值给唯一的重复数据的"label"列 26 duplicate_data_one ["label"] = duplicate_data_sum ['label'] 27 Result = pd.concat([no_duplicate,duplicate_data_one]
主要用到几个关键的函数:
Pandas.concat()
DataFrame.duplicated()
DataFrame.drop_duplicates().reset_index(drop=True)
DataFrame.groupby().agg({})
本人处于学习中,如有写的不够专业或者错误的地方,诚心希望各位读者多多指出!!