一、主从复制
(一)主从复制介绍
MySQL支持单向、双向、链式级联、实时、异步复制。在复制过程中,一台服务器充当主服务器(Master),而一个或多个其它的服务器充当从服务器(Slave)。
复制可以是单向:M-->S,也可以是双向:M<-->M,或者多M环状同步等。
如果设置了链式级联复制,那么从slave服务器本身充当从服务器外,也会同时充当其下从服务器的主服务器。下面是几种逻辑图:
1、主从同步逻辑图
- 单向主从同步

- 一主两从或多从

- 双向主主同步(互为主从)

- 线性级联单向双主同步

- 单向环状级联同步

- 单向环状级联多主多从同步

上面这么多的结构,那么因该如何选择呢?一般情况选择单向主从同步(图1),一主两从或多从(图2),单向线性级联同步(图4)可满足大部分的工作场景。大多数应用MySQL主从同步都是异步的复制方式(不是严格的实时数据同步)。
当配置好主从复制后,所有对数据库内容的更新操作必须在主服务器上进行,以避免用户对主服务器上数据库内容的更新与对从数据库上数据库内容的更新不一致导致发生冲突。
2、主从复制应用场景
- 主从服务器互为备份
主从服务器架构的设置,可以大大加强数据库架构的健壮性。当主服务出项问题时,可以手动或者自动切换到从服务器继续提供服务。
- 主从服务器读写分离分担网站压力
主从服器器架构可以通过程序或者代理软件实现对用请求的读写分离。即通过在从服务器上仅仅处理用户的查询请求(select),降低用户查询响应时间以及读写同时在主服务器上带来的压力。对于更新的数据(insert、update、delete)仍然交给主服务器处理,确保主服务器和从服务器保持实时同步。
- 服务器根据业务拆分独立分担压力
根据公司不同的业务,使用不同的从服务器来承担不同的模块。比如,一个网站有专门为用户提供的前台页面,帮用户提供查询等服务;另外有自己的后台管理,可用于上传前台需要展示的一些内容;还有就是一个从服务器专门用来对数据进行备份。

(二)主从复制实现原理
1、如何实现主从复制
- 通过程序
通过java或者Python等语言设置多个连接实现对数据库的读写分离,即当查询(select)时,就去连接读库的连接文件,当更新(update、insert、delete)时就去连接写库的连接文件。
- 通过软件
MySQL-proxy等代理软件可以实现读写分离的功能。
2、主从复制实现过程

主从复制实现的过程:
(1)Slave服务器上执行 start slave,开启主从复制开关。
(2)此时,Slave服务器上的IO线程会通过在Master授权的复制用户权限请求连接Master服务器,并且请求从指定binlog日志文件的指定位置(日志文件名和位置是在配置主从复制服务时执行change master命令时指定)后发送binlog日志内容。
(3)Master服务器接收来自Slave服务器的IO线程请求后,Master服务器上负责复制的IO线程根据Slave服务器的IO线程请求的信息读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回信息中除了binlog日志内容外,还有本次返回日志内容后的Master服务端新的binlog文件名称以及binlog中的下一个指定更新位置。
(4)当Slave服务器的IO线程获取来自Master服务器上IO线程发送的日志内容及日志文件和位置点后,将binlog日志内容依次写入到Slave端的Relay Log(中继日志)文件的最末端,并将新的binlog日志文件名和位置记录到master-info文件中,以便下一次读取Master端新的binlog日志能够告诉Master服务器需要从新的binlog日志的那个文件那个位置开始请求新的binlog日志内容。
(5)Slave服务端的SQL线程会实时检测本地的Relay Log中新增加的日志内容,然后及时的把Log文件中的内容解析成在Master端能够执行的SQL语句内容,并且在Slave服务器上按语句顺序执行应用这些SQL语句,应用完毕后清理应用过的日志。
(6)经过上述过程,就可以确保Mster端和Slave端执行了相同的SQL语句。当复制状态正常时,Master端和Slave端的数据是完全一样的。
二、主从复制实战
(一)复制准备
1、定义服务器角色
- 主库(Master)
ip:192.168.0.111
port:3306
- 从库(Slave)
ip:192.168.0.111
port:3307
注意:一般主从复制,主从在不同的服务器上,并且监听的端口均为3306。
2、数据库环境准备
数据库环境可有下面两种选择:
- 单机单数据库多实例
- 两个机器,每个机器都有自己的数据库环境
3、关闭正在运行的MySQL
root@hadoop-slave1 ~]# killall mysqld
(二)主从库配置
1、主库配置
修改/data/3306/my.cnf文件:
# vim /data/3306/my.cnf [mysqld] ... server-id = 1 log-bin = /data/3306/mysql-bin ...
(1)上面两个参数放到my.cnf文件的[mysqld]模块中
(2)server-id值是避免不同机器或者实例id重复
(3)主库中打开binlog日志功能
(4)修改完my.cnf文件后需要重启数据库
2、启动主库
# 启动 [root@hadoop-slave1 /]# /data/3306/mysql start Starting MySQL... # 查看端口 [root@hadoop-slave1 /]# netstat -tunlp|grep 3306 tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 42078/mysqld # 查看是否有mysql-bin文件 root@hadoop-slave1 /]# ll /data/3306/ total 28 drwxr-xr-x. 5 mysql mysql 129 Sep 6 17:33 data -rw-r--r--. 1 mysql mysql 1900 Aug 9 18:13 my.cnf -rwx------. 1 root root 1314 Aug 9 23:08 mysql -rw-r-----. 1 mysql root 5978 Sep 6 17:33 mysql_3306.err -rw-rw----. 1 mysql mysql 107 Sep 6 17:33 mysql-bin.000003 -rw-rw----. 1 mysql mysql 28 Sep 6 17:33 mysql-bin.index -rw-rw----. 1 mysql mysql 6 Sep 6 17:33 mysqld.pid srwxrwxrwx. 1 mysql mysql 0 Sep 6 17:33 mysql.sock # 查看logbin开关 [root@hadoop-slave1 /]# mysql -uroot -p123456 -S /data/3306/mysql.sock -e "show variables like 'log_bin';" +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_bin | ON | +---------------+-------+
3、从库配置
修改/data/3307/my.cnf文件:
# vim /data/3307/my.cnf [mysqld] ... #log-bin = /data/3307/mysql-bin #如果不启用备份可注释掉 relay-log = /data/3307/relay-bin #必须开启 server-id = 3 ...
4、启动从库
[root@hadoop-slave1 /]# /data/3307/mysql start Starting MySQL... [root@hadoop-slave1 /]# netstat -tunlp | grep 3307 tcp 0 0 0.0.0.0:3307 0.0.0.0:* LISTEN 43495/mysqld
如果出现MySQL is running...将3307目录下的pid和sock文件删除,再重新启动即可。
5、创建用于同步的账号
登录主库3306实例数据库:
# 登录3306 [root@hadoop-slave1 /]# mysql -uroot -p123456 -S /data/3306/mysql.sock Welcome to the MySQL monitor. Commands end with ; or g. ... # 创建用于从库复制的账号rep mysql> grant replication slave on *.* to 'rep'@'192.168.0.%' identified by '123456'; Query OK, 0 rows affected (0.01 sec) # 刷新权限 mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
- replication slave为mysql同步的必须权限,此处不要设置为all。
- *.*表示所有库的所有表,也可以指定具体的库和表(db.table)。
- 'rep'@'192.168.0.%'为同步账号。
6、主库备份
将主库的内容进行备份,在此期间锁库、锁表,只允许读,不允许写。
- 锁表
# 锁表 mysql> flush table with read lock; Query OK, 0 rows affected (0.00 sec) # 查看master状态 mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000003 | 333 | | | +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) # 查看日志 mysql> show master logs; +------------------+-----------+ | Log_name | File_size | +------------------+-----------+ | mysql-bin.000003 | 333 | +------------------+-----------+ 1 row in set (0.00 sec)
- 主库备份
上面锁表的窗口不要关闭,另起一个新的窗口:
[root@hadoop-slave1 /]# mysqldump -uroot -p123456 -S /data/3306/mysql.sock -A -B --events --master-data=2 > /temp/rep.sql
上面的--master-data=2会在备份文件中记录binlog的位置:
# vim rep.sql ... -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=333; ...
- 解锁
此时备份文件已经在另一个窗口完成,需要将之前的锁释放掉,在之前加锁的窗口中解锁:
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec)
7、从库全备
在进行主从同步之前必须保证主从数据库中的数据是一致的,所以需要先将主库的数据进行全备,将上述主库的备份文件全部导入到从库。
[root@hadoop-slave1 /]# mysql -uroot -p -S /data/3307/mysql.sock < /temp/rep.sql Enter password:
此时,可以这样理解:
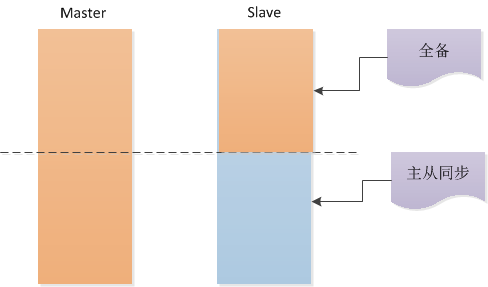
目前已经将全备数据导入到从数据库中,剩下的数据通过主从复制来完成即可。
8、登录从库配置同步参数
# 登录从数据库 [root@hadoop-slave1 /]# mysql -uroot -p -S /data/3307/mysql.sock Enter password: Welcome to the MySQL monitor. Commands end with ; or g. ... # 输入配置参数 mysql> CHANGE MASTER TO -> MASTER_HOST='192.168.0.111', #主库ip -> MASTER_PORT=3306, #主库端口 -> MASTER_USER='rep', #主库上建立的用于复制的用户rep -> MASTER_PASSWORD='123456', #rep密码 -> MASTER_LOG_FILE='mysql-bin.000003', #show master status的二进制文件名称 -> MASTER_LOG_POS=333; #show master status的二进制文件的偏移量 Query OK, 0 rows affected (0.02 sec)
注意的是MASTER_LOG_FILE和MASTER_LOG_POS,当我们使用全备是的备份文件中也有文件名和位置。上面的操作原理是将用户密码等信息写入到从库的master.info文件中:
[root@hadoop-slave1 ~]# cat /data/3307/data/master.info 18 mysql-bin.000003 333 192.168.0.111 rep 123456 3306 60 0 0 1800.000 0
如果在全备时使用--master-data=1,就不需要在同步参数中指定MASTER_LOG_FILE和MASTER_LOG_POS参数。
9、启动从库同步开关
# 启动主从同步 [root@hadoop-slave1 ~]# mysql -uroot -p -S /data/3307/mysql.sock -e 'start slave'; Enter password: # 查看状态 [root@hadoop-slave1 ~]# mysql -uroot -p -S /data/3307/mysql.sock -e 'show slave statusG'; Enter password: *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.0.111 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000003 Read_Master_Log_Pos: 333 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 253 Relay_Master_Log_File: mysql-bin.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: mysql Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 333 Relay_Log_Space: 403 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1
判断是否启动成功,就看IO和SQL两个线程是否为yes状态即可。
(三)测试
# 主数据库创建数据库 [root@hadoop-slave1 ~]# mysql -uroot -p123456 -S /data/3306/mysql.sock -e 'CREATE DATABASE test'; # 查看从数据库 [root@hadoop-slave1 ~]# mysql -uroot -p -S /data/3307/mysql.sock -e "SHOW DATABASEs LIKE 'rep%'"; Enter password: +-----------------+ | Database (rep%) | +-----------------+ | reptest | +-----------------+
可以看到已经成功了!