一、算法分类
(一)数据分类
不同的算法是针对不同的数据类型的,所以在了解算法之前,可以先了解以下数据的类型:
- 离散型数据
- 连续性数据
1、离散型数据
由记录不同类别个体的数目所得到的数据,又称计数数据,所有这些数据全部都是整数,而且不能再进行细分以及提高它们的精确度。
2、连续型数据
变量在某一范围内取任一数,即变量的取值可以是连续的,如长度、时间等,这类变量通常是含有小数部分。
注意的是:这两类数据的区别是离散型数据区间内不可分,连续性数据区间内可分。
(二)算法分类
算法从大的方面可分为下面两类:
- 监督学习
- 无监督学习
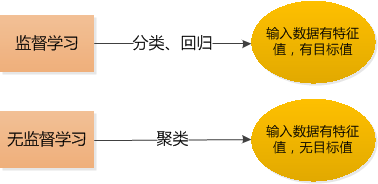
1、监督学习
监督学习(Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
在监督学习中又可分为下面几类:
(1)分类
k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
(2)回归
线性回归、岭回归
(3)标注
隐马尔可夫模型
监督学习针对的预测数据是:特征值+目标值(比如根据人体特征来预测性别)
2、无监督学习
无监督学习(Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值所组成。 在无监督学习中有聚类算法,也就是k-means。
无监督学习针对的预测数据是:只有特征值,而无具体的目标值
3、数据与算法
上面已经进行了数据分类以及算法分类,那么两者之间的关系是什么呢?
监督学习中的分类算法针对的是目标值为离散型,回归算法针对的是目标值为连续型。即:
二、机器学习开发流程
1、获取数据
可以通过爬虫或者其它方式获取所需要的数据
2、明确问题
你应该明白用这些数据究竟是解决什么问题,也就是说根据目标值得类型(离散或是连续)确定应用种类。
3、数据处理
使用一些数据处理的库,如pandas等对数据进行处理缺失值等。
4、特征工程
对数据进行标准化、特征选择、降维等进行处理。
5、算法预测
在第2步中已经根据问题,明确了应用的分类,如果目标值是离散的就去找分类算法进行处理,如果目标值是连续的就去找回归算法进行处理。
6、模型评估
上面的算法加上数据就是模型,将模型做出来后需要进行评估,看是否满足需求,如果不满足就需要更换算法、参数或者重新进行特征工程(特征选取、降维)等。
7、上线使用
以API的形式对外提供