(一)什么是字符编码:
计算机中所有的数据,包括文件,图片,视频,音频等都是以二进制的方式 存储的,计算机只能识别0,1这样的机器语言。而我们想让计算机替我们工作必须能让计算机能够识别我们对它发出的指令,那么就需要一种方式把我们人类的语言翻译成计算机能听懂的语言。这个翻译的过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
(二)字符编码的发展历程:
阶段一,ASSCII码:一个bytes代表一个字符(英文字符以及键盘上其它所有的字符)1bytes=8bit,8bit可以表示2**8-1 ,一共是256种变化。
阶段二,百家争鸣:中国人为了满足汉字,制定了“GBK”,日本人制定了“shift _gis”,韩国人制定了"Euc-kr"等等。
阶段三, 天下归一:各个国家有各个国家的标准,就不可避免的会有冲突,在多语言混合的文本中,必定会出现乱码的现象。这个时候就出现了可以兼容各个 国家编码的万国码(UIcode),UIcode统一用2bytes代表一个字符,一共可以表示2**16-1=65535种变化。但是这种编码方式对于通篇是英文的文本 来说,无疑是浪费空间的,英文因为1bytes就可以表示一个字符。于是就产生了可变长度字符编码,UFT-8,这种字符编码规定英文用1bytes中文用 3bytes来表示。但是这种字符编码多了一道识别过程,速度就会比简单粗暴的UIcode要慢很多。这个时候就要在时间和空间上做一个取舍。计算机运 行程序,都需要先将数据加载到内存中来运行,这个时候为了不出现乱码的现象,规定在内存中使用UIcode,而在硬盘中因为各个国家的不同可 以使用uft-8来存储数据。
(三)字符编码使用:
以下两个场景中涉及到字符编码问题
1,一个python文件的内容是由一堆字符组成(文件未执行时)
2, python中的数据类型是有一堆字符串组成(文件执行时)
文件未执行时:普通文件存储打开的过程就是:首先文本编辑器编辑内容(这个时候是在内存中操作的)然后进行保存(保存在硬盘中)其次读取的过程是相反的,数据从硬盘加载到内存,然后文本编辑器再打印显示给我们。那么python文件呢,在没有运行之前我们所写的代码和这些普通的文档是没有任何区别的,都是一堆字符。用一个简单的图来描述这个过程。
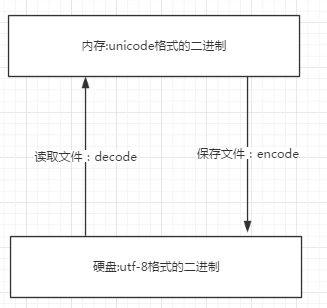
Unicode-----------》encode------------》utf-8
utf-8-------------》decode-------------》Unicode
python文件执行过程,首先启动python解释器,然后加载python文件,解释器识别文件。这里需要注意的是python2中默认的字符编码 是ASCII码,而python3中默认是uft-8。Windows终端是“gbk”。
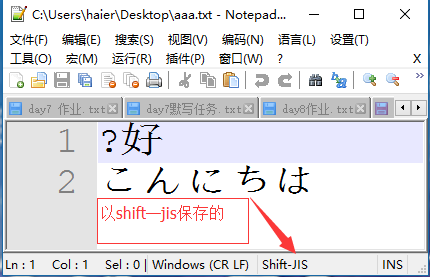
乱码现象:首先编辑文件的时候是在内存中编辑的,内存中是UIcode编码的,存储是将数据刷到硬盘中,以shift—gis保存的,所以保存的时候就已 经发生错误,所以打开的时候就会产生乱码,这种乱码是没有办法改变的,如果是文件读取的过程中产生乱码,可以通过选择正确的解码方式就ok 了,而存文件时乱码,则是对文件的一种破坏!
总结:
无论是何种编辑器,要防止文件出现乱码(一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开!对于UIcode数据类型,无论以何种方式打开,都不会出现乱码。
(四)python程序执行:
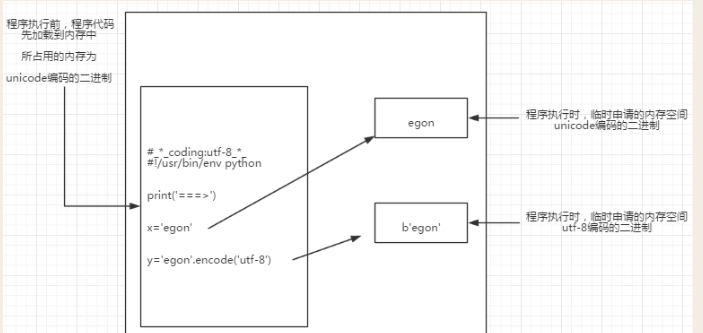
阶段一:启动python解释器
阶段二:加载python文件到内存
阶段三:读取已经加载到内存中的代码(UIcode编码的二进制)执行过程中会开辟新的内存。
注意:python会读取py文件第一行代码,来决定以什么编码来读取内存。如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
python2中默认使用ascii,python3中默认使用utf-8
(五)python2和python3之间的区别
python中的字符串有两种str=bytes,在变量值前面加“u”则定义为UIcode,这里牵扯到python2中变量值开辟内存空间存储时是以UIcode,encode后的bytes存储的而python3中直接以UIcode方式存储的。python3中的字符串也有两种,str相当于py2中加“u”的状态。bytes指的是py3中的变量值可以encode转换成bytes的方式如s1=s.encode('utf-8') s2=s.encode('gbk')。python3默认utf-8,python2 默认ASCII!
总结:1,无论什么文件,以什么方式存就以什么方式取(避免乱码)内存中固定使用UIcode,硬盘中则可根据个人喜好
2,数据最先产生于内存,是UIcode格式,想要存储或者基于网络传输,需要转换成bytes格式。
UIcode---------》encode---------》bytes
bytes-------》decode-----------》UIcode