字典树Trie
1. 字典树的数据结构
2. 字典树的核心思想
3. 字典树的基本性质
1. 树Tree
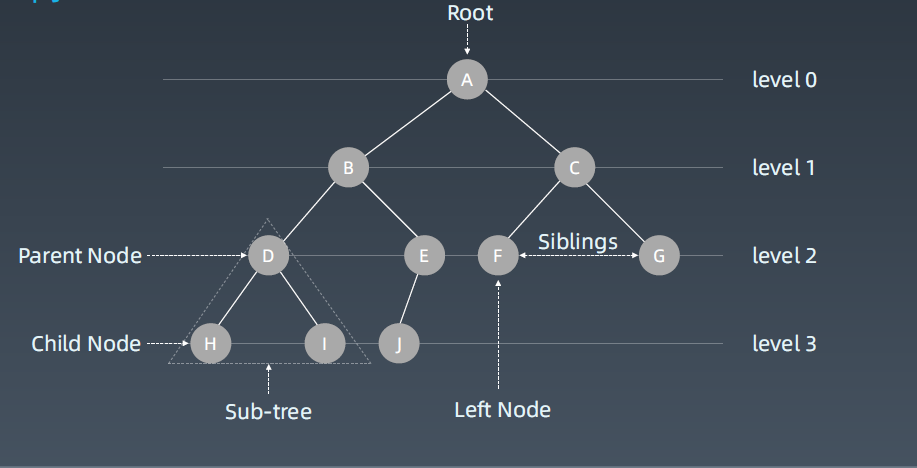
按层次打印一颗二叉树,
在树中深度优先搜索:ABDH I EJ CFG
广度优先搜索:A BC DEFG HIJ
2. 二叉搜索树

二叉搜索树是子树之间的关系,并不是儿子和父亲的关系。
任何一个节点它的左子树的所有节点都要小于这个根结点
它的右子树的所有节点都要大于根结点,且对于它的任何子树同样地以此类推,对于任何子树都满足这样的特性。
二叉搜索树是一个升序的序列,如果是中序遍历左根右: 123 5678 9 10 11 12 13 15
二叉搜索树主要解决的问题是查找的效率会更高,比如要查10,首先跟根结点比,10 > 9,左子树不用找了,一分为二,只需要找右子树即可,再比较13 > 10,左子树,11 > 10,继续左子树。
3. 字典树Trie
应用的场景: 搜索时词频的感应,由前缀来推后面的可能的词语。
字典树不再是存储一个单词本身,而是把字符串拆成单个单个的字母,每个字母存在这个节点里边
3.1 基本结构
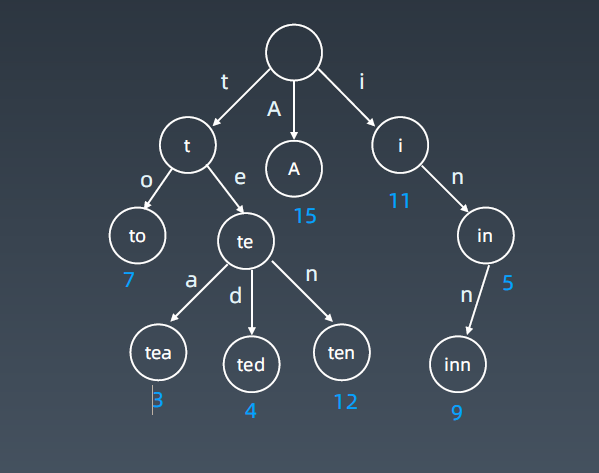
字典树,即 Trie 树,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
节点本身不存任何单词,它只存它要去到下一个路径上面,这个路径代表的字符,每个节点依次进行。
比如ten这个单词,t -> te -> ten ,常用的字符放根结点上,根据输入的不同字符,开始分叉。Trie树不是一个二叉树而是一个多叉树。
根据走到不同地方,就开始分到不同的地方即所谓的分流,比如第一个字符是i(以i开始,后边所有可能是单词都是以i开头),如果后边路径是n,还是n ..就是inn 小酒馆,但这个节点它并不存储inn这个单词,它表这个地方是根了,且这个地方有一个单词的终止符,要看它代表哪个单词要从根节点捋下来,最后捋到这个节点它所走过的路径,任何节点最后它代表的单词就是走过的这条边
3.2 基本性质
1. 结点本身不存完整单词;
2. 从根结点到某一结点,路径上经过的字符连接起来,为该结点对应的字符串;
3. 每个结点的所有子结点路径代表的字符都不相同。
3.3 节点存储额外信息
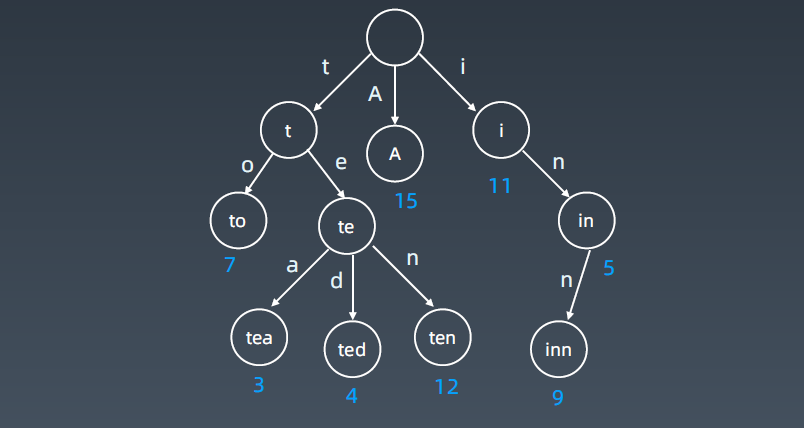
数字表示相应到这个结点所代表的单词,它统计的计数就放在这个地方,数字表这个单词出现的统计频次。按照统计的频次就可以给用户做相应的推荐。
3.4 节点的内部实现
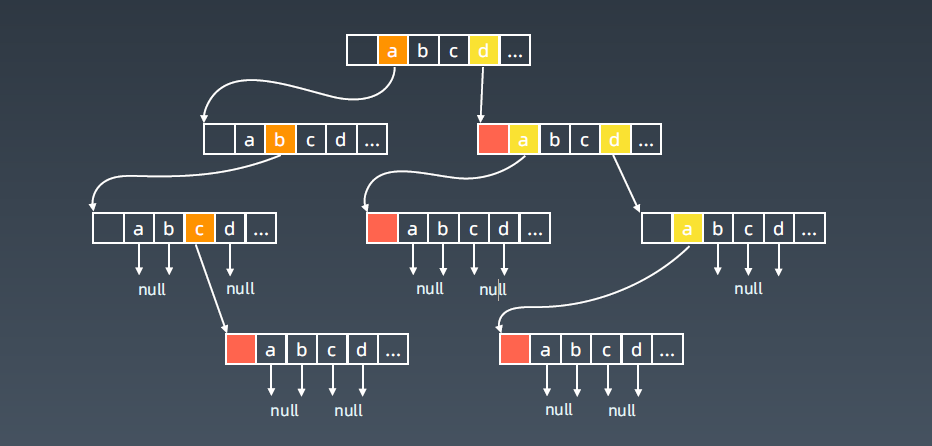
上图只是abcdefg...,同时它还有大写的ABCDEFG...
每个结点指向下一个节点的不同指针,这里它的存储不再是left和right来表示左右结点了,它直接用相应的字符来指向下一个结点,比如第一个字符是a,应该走到这个结点去,
如果是简单单词不分大小写,可以认为这里是26个分叉,从a一直分到z;如果是整个字符串它的ASCII域是255,即255分叉。上图可以看做是26分叉的一颗多叉树。
到最后如果是叶子节点,就指向空。
最大可能情况变成26叉树,它的空间相对来说是消耗比较大的,一层出去就是26.
它单词的长度即深度,它查询的次数即这个单词有多少个字符。比如单词to,它查t 和o,2次。
Trie 树的核心思想是空间换时间。
利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
4. 并查集 Disjoint Set
适用场景:
• 组团、配对问题(很快地判断这两个个体是不是在一个集合当中如你俩是不是朋友,如果是在社交网络里判断两个群体是不是一个群体以及快速地合并群组)
• Group or not ?
如实现微信上的好友和所谓朋友圈的功能,以及分析这两个人是不是好友,
假设有0-n-1个人,快速地判断a和b到底是不是朋友,以及支持一些操作如把a变成b的朋友:
用一个set,或者dic表示里边的人都是朋友,-----> 导致会建很多set,如两两是朋友,第三个不是他们的朋友,最后还要合并set...
• makeSet(s):建立一个新的并查集,其中包含 s 个单元素集合。
• unionSet(x, y):把元素 x 和元素 y 所在的集合合并,要求 x 和 y 所在的集合不相交,如果相交则不合并。
• find(x):找到元素 x 所在的集合的代表,该操作也可以用于判断两个元素是否位于同一个集合,只要将它们各自的代表比较一下就可以了。

一开始每个元素拥有一个parent数组指向自己,表示它自己就是自己的集合
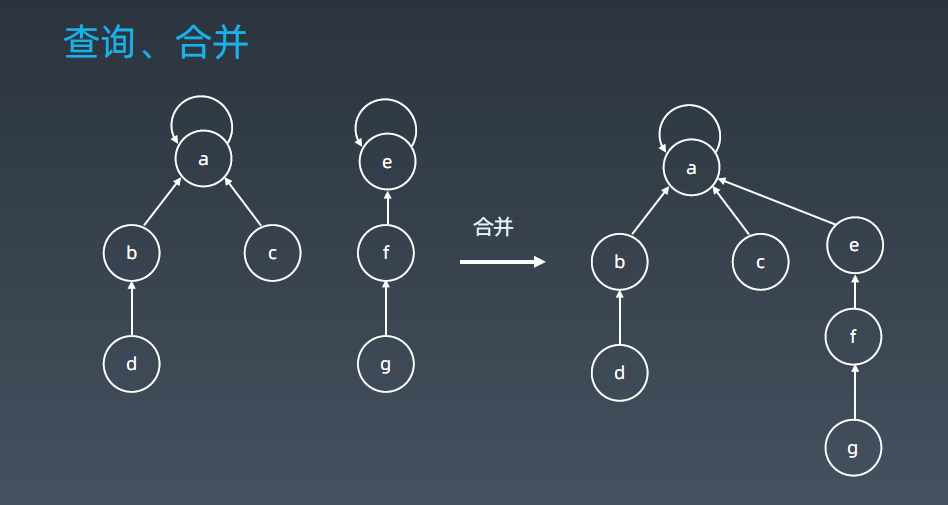
查询,对任何一个元素,看它的parent,再看它的parent,一直往上,直到它的parent等于它自己的时候,说明找到了它的领头元素 即它的集合的代表元素,就表示这个集合是谁。
合并,找到这两个集合的领头元素,这里是a 和e,然后将parent[e] 指向a 或者将parent[a] 指向e, 要么把e的parent指向a 或者把a的parent指向e都行。 最后即把这两个合并。
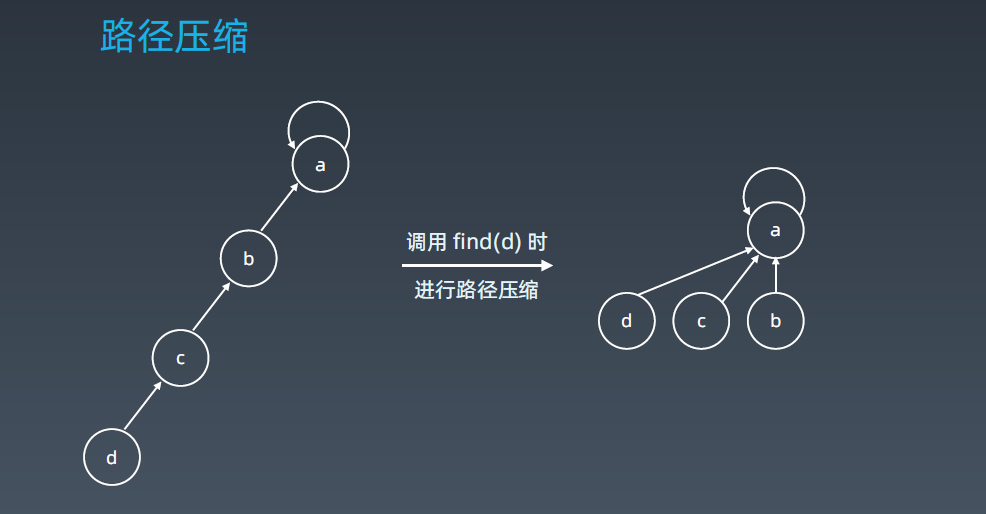
d的parent是c,c的parent是b,b的parent是a,那么我们可以直接把这条路上的所有元素它的parent都指向a,这样的操作还是和原来的表是一样的,但是它的查询时间会快很多。 原来要查询集合a的领头元素是谁,要往上走一步走两步走三步,压缩后只需要一步即可。
class UnionFind {
private int count = 0; private int[] parent; public UnionFind(int n) { count = n; parent = new int[n]; for (int i = 0; i < n; i++) { parent[i] = i; //初始化,所有并查集开始初始化; 一个指向指针的关系,和数组有异曲同工之妙 } } /* 给定任何一个p,如何找它的集合是谁; 即怎么找它集合和它集合的领头元素; 不断的往上去找,知道parent[i] = i时说明找到了它所在集合的领头元素 */ public int find(int p) { while (p != parent[p]) { parent[p] = parent[parent[p]]; p = parent[p]; } return p; } /* 如何进行合并,调find找到它的p的集合所在的领头元素, */ public void union(int p, int q) { int rootP = find(p); int rootQ = find(q); if (rootP == rootQ) return; parent[rootP] = rootQ; count--; }
}