Druid是一个快速的列式分布式的支持实时分析的数据存储系统,在处理PB级别数据、毫秒级查询、数据实时处理方面,比传统的OLAP系统有了显著的性能改进。



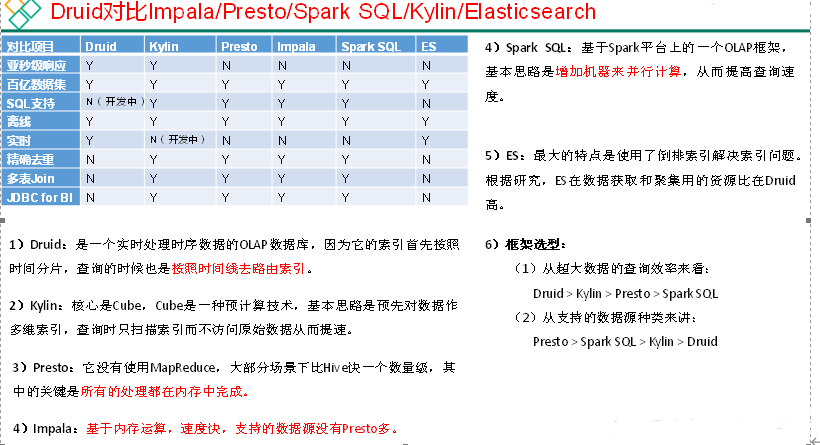
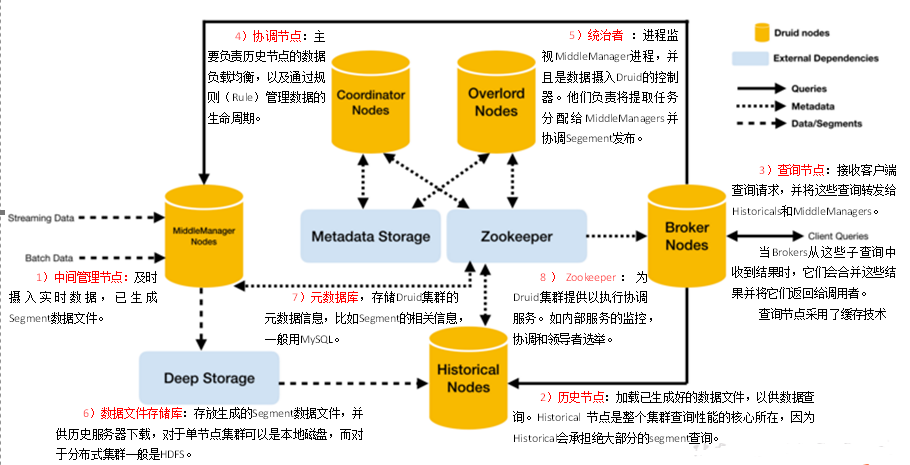
Druid数据结构
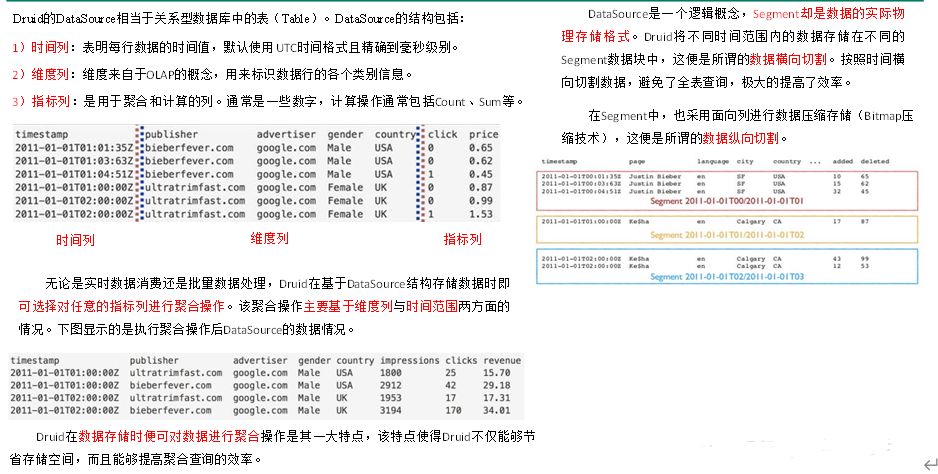
与Druid架构相辅相成的是其基于DataSource与Segment的数据结构,它们共同成就了Druid的高性能优势。
Druid安装(单机版)
从https://imply.io/get-started 下载最新版本安装包
安装部署
imply集成了Druid,提供了Druid从部署到配置到各种可视化工具的完整的解决方案,imply有点类似于我们之前学过的Cloudera Manager
1.解压
tar -zxvf imply-2.7.10.tar.gz -C /opt/module
目录说明如下:
- bin/ - run scripts for included software.
- conf/ - template configurations for a clustered setup.
- conf-quickstart/* - configurations for the single-machine quickstart.
- dist/ - all included software.
- quickstart/ - files related to the single-machine quickstart.
2.修改配置文件
1)修改Druid的ZK配置
[kris@hadoop101 _common]$ vim /opt/module/imply/conf/druid/_common/common.runtime.properties
druid.zk.service.host=hadoop101:2181,hadoop102:2181,hadoop103:2181
2)修改启动命令参数,使其不校验不启动内置ZK
[kris@hadoop101 supervise]$ vim /opt/module/imply/conf/supervise/quickstart.conf
:verify bin/verify-java
#:verify bin/verify-default-ports
#:verify bin/verify-version-check
:kill-timeout 10
#!p10 zk bin/run-zk conf-quickstart
3.启动
1)启动zookeeper
2)启动imply
[kris@hadoop101 imply-2.7.10]$ bin/supervise -c conf/supervise/quickstart.conf
[Fri Jan 3 13:37:51 2020] Running command[coordinator], logging to[/opt/module/imply-2.7.10/var/sv/coordinator.log]: bin/run-druid coordinator conf-quickstart
[Fri Jan 3 13:37:51 2020] Running command[broker], logging to[/opt/module/imply-2.7.10/var/sv/broker.log]: bin/run-druid broker conf-quickstart
[Fri Jan 3 13:37:51 2020] Running command[historical], logging to[/opt/module/imply-2.7.10/var/sv/historical.log]: bin/run-druid historical conf-quickstart
[Fri Jan 3 13:37:51 2020] Running command[overlord], logging to[/opt/module/imply-2.7.10/var/sv/overlord.log]: bin/run-druid overlord conf-quickstart
[Fri Jan 3 13:37:51 2020] Running command[middleManager], logging to[/opt/module/imply-2.7.10/var/sv/middleManager.log]: bin/run-druid middleManager conf-quickstart
[Fri Jan 3 13:37:51 2020] Running command[imply-ui], logging to[/opt/module/imply-2.7.10/var/sv/imply-ui.log]: bin/run-imply-ui-quickstart conf-quickstart
说明:每启动一个服务均会打印出一条日志。可以通过/opt/module/imply-2.7.10/var/sv/查看服务启动时的日志信息
[kris@hadoop101 sv]$ ll
总用量 904
-rw-rw-r-- 1 kris kris 77528 1月 3 13:38 broker.log
-rw-rw-r-- 1 kris kris 588001 1月 3 14:07 coordinator.log
-rw-rw-r-- 1 kris kris 76857 1月 3 13:38 historical.log
-rw-rw-r-- 1 kris kris 11599 1月 3 14:06 imply-ui.log
-rw-rw-r-- 1 kris kris 70725 1月 3 13:38 middleManager.log
-rw-rw-r-- 1 kris kris 93658 1月 3 14:07 overlord.log
查看端口号9095的启动情况:
[kris@hadoop101 sv]$ netstat -anp | grep 9095
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 :::9095 :::* LISTEN 6118/imply-ui-linux
tcp 0 0 ::ffff:192.168.1.101:9095 ::ffff:192.168.1.1:54884 TIME_WAIT -
tcp 0 0 ::ffff:192.168.1.101:9095 ::ffff:192.168.1.1:54883 TIME_WAIT -
登录hadoop101:9095查看

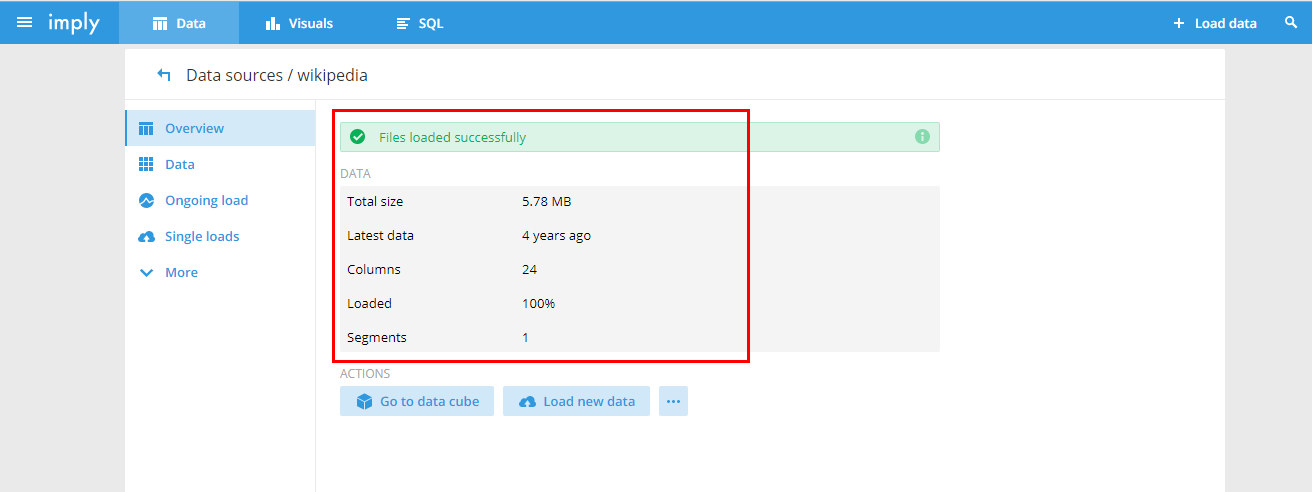
停止服务
按Ctrl + c中断监督进程,如果想中断服务后进行干净的启动,请删除/opt/module/imply-2.7.10/var/目录。
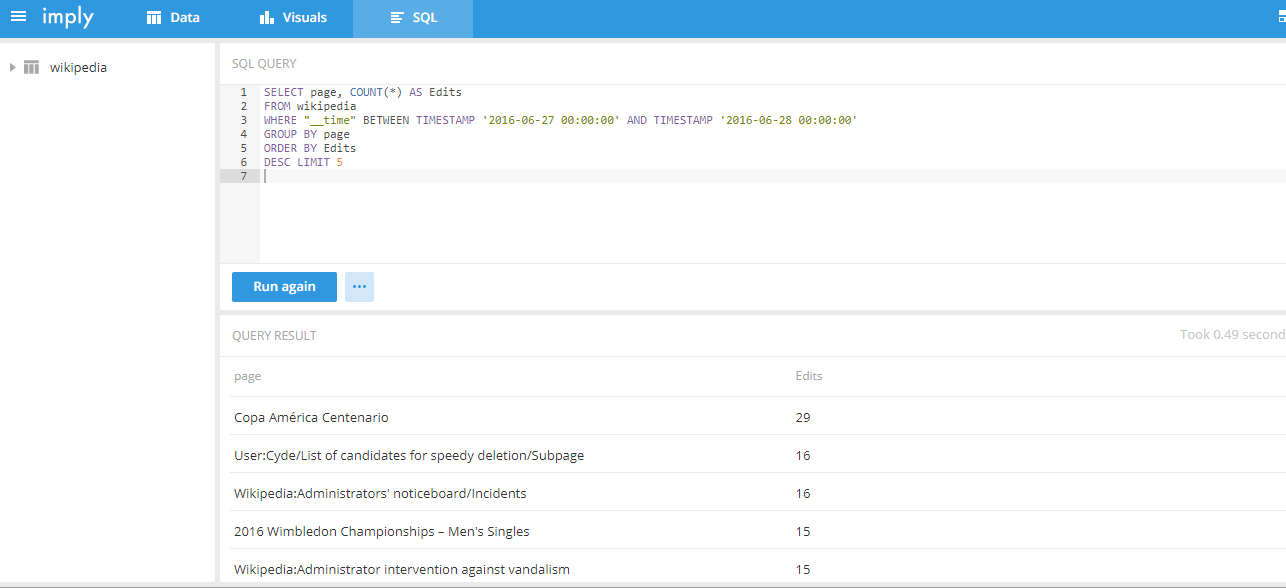
从hadoop加载数据
加载数据
批量摄取维基百科样本数据,文件位于quickstart/wikipedia-2016-06-27-sampled.json。使用quickstart/wikipedia-index-hadoop.json 摄取任务文件。
bin/post-index-task --file quickstart/wikipedia-index-hadoop.json
此命令将启动Druid Hadoop摄取任务。 摄取任务完成后,数据将由历史节点加载,并可在一两分钟内进行查询。
[kris@hadoop101 imply]$ bin/post-index-task --file quickstart/wikipedia-index-hadoop.json
Beginning indexing data for wikipedia
Task started: index_hadoop_wikipedia_2020-02-08T09:25:37.204Z
Task log: http://localhost:8090/druid/indexer/v1/task/index_hadoop_wikipedia_2020-02-08T09:25:37.204Z/log
Task status: http://localhost:8090/druid/indexer/v1/task/index_hadoop_wikipedia_2020-02-08T09:25:37.204Z/status
Task index_hadoop_wikipedia_2020-02-08T09:25:37.204Z still running...
Task index_hadoop_wikipedia_2020-02-08T09:25:37.204Z still running...
Task index_hadoop_wikipedia_2020-02-08T09:25:37.204Z still running...
Task index_hadoop_wikipedia_2020-02-08T09:25:37.204Z still running...
Task finished with status: SUCCESS
Completed indexing data for wikipedia. Now loading indexed data onto the cluster...
wikipedia loading complete! You may now query your data
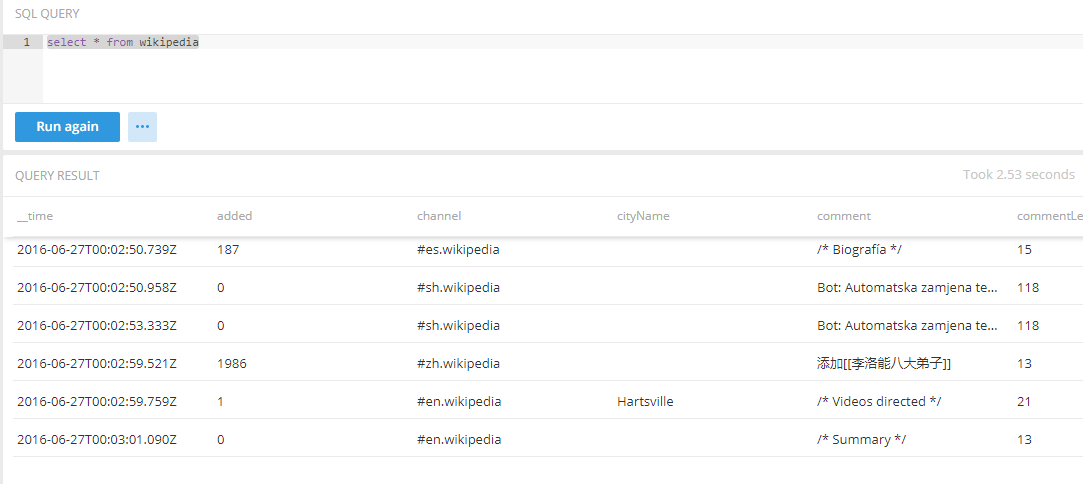
SQL查询
select * from wikipedia

[kris@hadoop101 imply]$ curl -XPOST -H'Content-Type: application/json' -d @quickstart/wikipedia-kafka-supervisor.json http://hadoop101:8090/druid/indexer/v1/supervisor
{"id":"wikipedia-kafka"}
加载实时数据:
[kris@hadoop101 imply]$ curl -O https://static.imply.io/quickstart/wikiticker-0.4.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 30.0M 100 30.0M 0 0 535k 0 0:00:57 0:00:57 --:--:-- 623k