1. Flink 批处理Api
1.1 Source
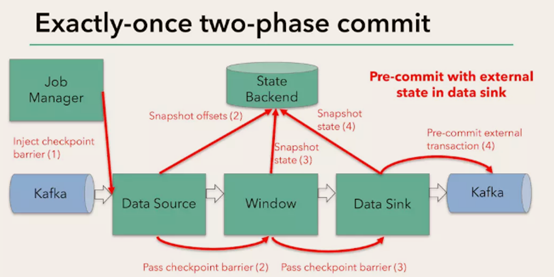
Flink+kafka是如何实现exactly-once语义的
Flink通过checkpoint来保存数据是否处理完成的状态;
有JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。
执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
如果宕机需要通过StateBackend进行恢复,只能恢复所有确认提交的操作。
Spark中要想实现有状态的,需要使用updateBykey或者借助redis;
而Fink是把它记录在State Bachend,只要是经过keyBy等处理之后结果会记录在State Bachend(已处理未提交; 如果是处理完了就是已提交状态;),
它还会记录另外一种状态值:keyState,比如keyBy累积的结果;
StateBachend如果不想存储在内存中,也可以存储在fs文件中或者HDFS中; IDEA的工具只支持memory内存式存储,一旦重启就没了;部署到linux中就支持存储在文件中了;
Kakfa的自动提交:“enable.auto.commit”,比如从kafka出来后到sparkStreaming之后,一进来consumer会帮你自动提交,如果在处理过程中,到最后有一个没有写出去(比如写到redis、ES),虽然处理失败了但kafka的偏移量已经发生改变;所以移偏移量的时机很重要;
1.2 Transform 转换算子
map

val streamMap = stream.map { x => x * 2 }
object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //dstream.print().setParallelism(1) 测试从kafka中获得数据是否打通到了flink中 //将json转换成json对象 val startupLogDStream: DataStream[StartupLog] = dstream.map { jsonString => JSON.parseObject(jsonString, classOf[StartupLog]) } //需求一 相同渠道的值进行累加 val sumDStream: DataStream[(String, Int)] = startupLogDStream.map { startuplog => (startuplog.ch, 1) }.keyBy(0)
.reduce { (startuplogCount1, startuplogCount2) => val newCount: Int = startuplogCount1._2 + startuplogCount2._2 (startuplogCount1._1, newCount) } //val sumDStream: DataStream[(String, Int)] = startupLogDStream.map{startuplog => (startuplog.ch,1)}.keyBy(0).sum(1) //sumDStream.print() env.execute() } }
flatMap
flatMap的函数签名:def flatMap[A,B](as: List[A])(f: A ⇒ List[B]): List[B] 例如: flatMap(List(1,2,3))(i ⇒ List(i,i)) 结果是List(1,1,2,2,3,3), 而List("a b", "c d").flatMap(line ⇒ line.split(" ")) 结果是List(a, b, c, d) val streamFlatMap = stream.flatMap{ x => x.split(" ") }
Filter
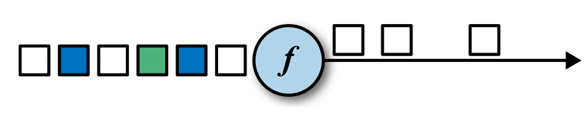
val streamFilter = stream.filter{ x => x == 1 }
KeyBy
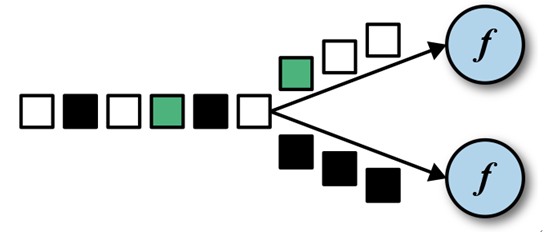
DataStream → KeyedStream:输入必须是Tuple类型,逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的。
以HashCode来进行分区,可能有些key值不相同也会分到相同区。
滚动聚合算子(Rolling Aggregation)
这些算子可以针对KeyedStream的每一个支流做聚合,必须KeyBy分组之后再sum聚合等。
sum()
min()
max()
minBy()
maxBy()
Reduce
KeyedStream → DataStream:一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
val stream2 = env.readTextFile("YOUR_PATH\sensor.txt") .map( data => { val dataArray = data.split(",") SensorReading(dataArray(0).trim, dataArray(1).trim.toLong, dataArray(2).trim.toDouble) }) .keyBy("id") .reduce( (x, y) => SensorReading(x.id, x.timestamp + 1, y.temperature) )
Split 和 Select
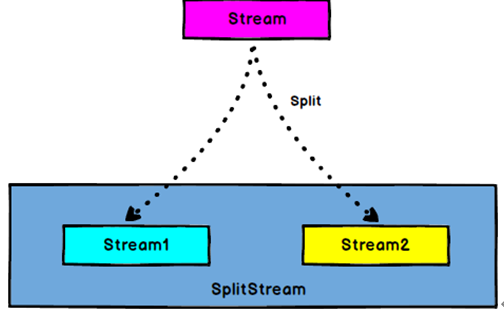
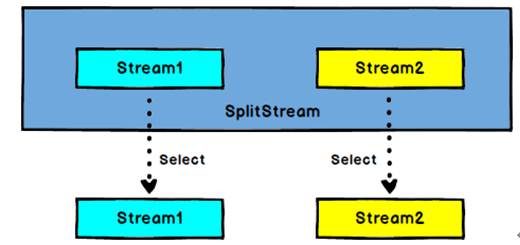
DataStream 通过split得到→ SplitStream --->通过select得到DataStream:根据某些特征把一个DataStream拆分成两个或者多个DataStream。
SplitStream→DataStream:从一个SplitStream中获取一个或者多个DataStream。
//需求二 把 appstore 和其他的渠道的数据 分成两个流 val splitableStream: SplitStream[StartupLog] = startupLogDStream.split { startuplog => var flagList: List[String] = List() if (startuplog.ch.equals("appstore")) { flagList = List("apple") } else { flagList = List("other") } flagList } val appleStream: DataStream[StartupLog] = splitableStream.select("apple") //appleStream.print("this is apple").setParallelism(1) val otherdStream: DataStream[StartupLog] = splitableStream.select("other") //otherdStream.print("this is other").setParallelism(1)
Connect和 CoMap

connecte的两条流数据类型可以不同,但一次操作只能合并2条流;
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
ConnectedStreams → DataStream:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。
//需求三 把上面两个流合并为一个 val connStream: ConnectedStreams[StartupLog, StartupLog] = appleStream.connect(otherdStream) val allDataStream: DataStream[String] = connStream.map((startuplog1: StartupLog) => startuplog1.ch, (startuplog2: StartupLog) => startuplog2.ch) allDataStream.print("all").setParallelism(1)
CoMap,CoFlatMap
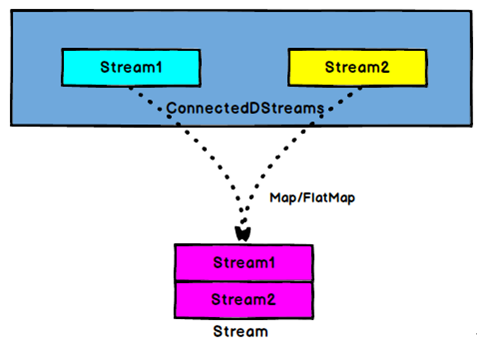
ConnectedStreams → DataStream:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。
val warning = high.map( sensorData => (sensorData.id, sensorData.temperature) ) val connected = warning.connect(low) val coMap = connected.map( warningData => (warningData._1, warningData._2, "warning"), lowData => (lowData.id, "healthy") )
Union
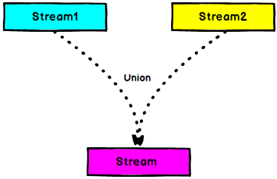
DataStream → DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream。注意:如果你将一个DataStream跟它自己做union操作,在新的DataStream中,你将看到每一个元素都出现两次。
可以合并多条流,但是数据结构必须一样;
//合并流union val unionDStream: DataStream[StartupLog] = appleStream.union(otherdStream) unionDStream.print("union").setParallelism(1)
Connect与 Union 区别:
1 、 Union之前两个流的类型必须是一样,Connect可以不一样,在之后的coMap中再去调整成为一样的。
2 Connect只能操作两个流,Union可以操作多个
1.2 Sink
Flink没有类似于spark中foreach方法,让用户进行迭代的操作。虽有对外的输出操作都要利用Sink完成。最后通过类似如下方式完成整个任务最终输出操作。
myDstream.addSink(new MySink(xxxx))
官方提供了一部分的框架的sink。除此以外,需要用户自定义实现sink。

Kafka
object MyKafkaUtil { val prop = new Properties() prop.setProperty("bootstrap.servers","hadoop101:9092") prop.setProperty("group.id","gmall") def getConsumer(topic:String ):FlinkKafkaConsumer011[String]= { val myKafkaConsumer:FlinkKafkaConsumer011[String] = new FlinkKafkaConsumer011[String](topic, new SimpleStringSchema(), prop) myKafkaConsumer } def getProducer(topic:String):FlinkKafkaProducer011[String]={ new FlinkKafkaProducer011[String]("hadoop101:9092",topic,new SimpleStringSchema()) } } //sink到kafka unionDStream.map(_.toString).addSink(MyKafkaUtil.getProducer("gmall_union")) ///opt/module/kafka/bin/kafka-console-consumer.sh --zookeeper hadoop101:2181 --topic gmall_union
从kafka到kafka 启动kafka kafka生产者:[kris@hadoop101 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop101:9092 --topic sensor kafka消费者: [kris@hadoop101 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic sinkTest --from-beginning SensorReading(sensor_1,1547718199,35.80018327300259) SensorReading(sensor_6,1547718201,15.402984393403084) SensorReading(sensor_7,1547718202,6.720945201171228) SensorReading(sensor_10,1547718205,38.101067604893444) SensorReading(sensor_1,1547718206,35.1) SensorReading(sensor_1,1547718207,35.6)
Redis
import org.apache.flink.streaming.connectors.redis.RedisSink import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper} object MyRedisUtil { private val config: FlinkJedisPoolConfig = new FlinkJedisPoolConfig.Builder().setHost("hadoop101").setPort(6379).build() def getRedisSink(): RedisSink[(String, String)] = { new RedisSink[(String, String)](config, new MyRedisMapper) } } class MyRedisMapper extends RedisMapper[(String, String)]{ //用何种命令进行保存 override def getCommandDescription: RedisCommandDescription = { new RedisCommandDescription(RedisCommand.HSET, "channel_sum") //hset类型, apple, 111 } //流中的元素哪部分是value override def getKeyFromData(channel_sum: (String, String)): String = channel_sum._2 //流中的元素哪部分是key override def getValueFromData(channel_sum: (String, String)): String = channel_sum._1 } object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //dstream.print().setParallelism(1) 测试从kafka中获得数据是否打通到了flink中 //将json转换成json对象 val startupLogDStream: DataStream[StartupLog] = dstream.map { jsonString => JSON.parseObject(jsonString, classOf[StartupLog]) } //sink到redis //把按渠道的统计值保存到redis中 hash key: channel_sum field ch value: count //按照不同渠道进行累加 val chCountDStream: DataStream[(String, Int)] = startupLogDStream.map(startuplog => (startuplog.ch, 1)).keyBy(0).sum(1) //把上述结果String, Int转换成String, String类型 val channelDStream: DataStream[(String, String)] = chCountDStream.map(chCount => (chCount._1, chCount._2.toString)) channelDStream.addSink(MyRedisUtil.getRedisSink())
ES
object MyEsUtil { val hostList: util.List[HttpHost] = new util.ArrayList[HttpHost]() hostList.add(new HttpHost("hadoop101", 9200, "http")) hostList.add(new HttpHost("hadoop102", 9200, "http")) hostList.add(new HttpHost("hadoop103", 9200, "http")) def getEsSink(indexName: String): ElasticsearchSink[String] = { //new接口---> 要实现一个方法 val esSinkFunc: ElasticsearchSinkFunction[String] = new ElasticsearchSinkFunction[String] { override def process(element: String, ctx: RuntimeContext, indexer: RequestIndexer): Unit = { val jSONObject: JSONObject = JSON.parseObject(element) val indexRequest: IndexRequest = Requests.indexRequest().index(indexName).`type`("_doc").source(jSONObject) indexer.add(indexRequest) } } val esSinkBuilder = new ElasticsearchSink.Builder[String](hostList, esSinkFunc) esSinkBuilder.setBulkFlushMaxActions(10) val esSink: ElasticsearchSink[String] = esSinkBuilder.build() esSink } } object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //sink之三 保存到ES val esSink: ElasticsearchSink[String] = MyEsUtil.getEsSink("gmall_startup") dstream.addSink(esSink) //dstream来自kafka的数据源 GET gmall_startup/_search
Mysql
class MyjdbcSink(sql: String) extends RichSinkFunction[Array[Any]] { val driver = "com.mysql.jdbc.Driver" val url = "jdbc:mysql://hadoop101:3306/gmall?useSSL=false" val username = "root" val password = "123456" val maxActive = "20" var connection: Connection = null // 创建连接 override def open(parameters: Configuration) { val properties = new Properties() properties.put("driverClassName",driver) properties.put("url",url) properties.put("username",username) properties.put("password",password) properties.put("maxActive",maxActive) val dataSource: DataSource = DruidDataSourceFactory.createDataSource(properties) connection = dataSource.getConnection() } // 把每个Array[Any] 作为数据库表的一行记录进行保存 override def invoke(values: Array[Any]): Unit = { val ps: PreparedStatement = connection.prepareStatement(sql) for (i <- 0 to values.length-1) { ps.setObject(i+1, values(i)) } ps.executeUpdate() } override def close(): Unit = { if (connection != null){ connection.close() } } } object StartupApp { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val myKafkaConsumer: FlinkKafkaConsumer011[String] = MyKafkaUtil.getConsumer("GMALL_STARTUP") val dstream: DataStream[String] = env.addSource(myKafkaConsumer) //dstream.print().setParallelism(1) 测试从kafka中获得数据是否打通到了flink中 //将json转换成json对象 val startupLogDStream: DataStream[StartupLog] = dstream.map { jsonString => JSON.parseObject(jsonString, classOf[StartupLog]) } //sink之四 保存到Mysql中 startupLogDStream.map(startuplog => Array(startuplog.mid, startuplog.uid, startuplog.ch, startuplog.area,startuplog.ts)) .addSink(new MyjdbcSink("insert into fink_startup values(?,?,?,?,?)")) env.execute() } }