排查了三四个小时,终于解决了这个GC问题,记录解决过程于此,希望对大家有所帮助。本文假定读者已具备基本的GC常识和JVM调优知识,关于JVM调优工具使用可以查看我在同一分类下的另一篇文章:
http://my.oschina.net/feichexia/blog/196575
背景说明
发生问题的系统部署在Unix上,发生问题前已经跑了两周多了。
其中我用到了Hadoop源码中的CountingBloomFilter,并将其修改成了线程安全的实现(详情见:AdjustedCountingBloomFilter),主要利用了AtomicLong的CAS乐观锁,将long[]替换成了AtomicLong[]。这样导致系统中有5个巨大的AtomicLong数组(每个数组大概占50MB),每个数组包含大量AtomicLong对象(所有AtomicLong对象占据大概1.2G内存)。而且这些AtomicLong数组的存活时间都至少为一天。
服务端已先于手机客户端上线,客户端本来计划本周四上线(写这篇文章时是周一),所以我还打算在接下来的几天继续观察下系统的运行状况,开启的仍然是Debug级别日志。
部分JVM参数摘抄如下(JVM参数配置在项目部署的tomcat服务器的根目录下的bin目录下的setenv.sh中,可以通过ps -ef | grep xxx | grep -v grep查看到):
|
1
|
-XX:PermSize=256M -XX:MaxPermSize=256M -Xms6000M -Xmx6000M -Xmn1500M -Xss256k -XX:ParallelGCThreads=8 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+DisableExplicitGC -XX:+CMSParallelRemarkEnabled -XX:+CMSClassUnloadingEnabled -XX:+CMSPermGenSweepingEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection -XX:+CMSScavengeBeforeRemark -XX:+HeapDumpOnOutOfMemoryError -Xloggc:/usr/local/webserver/point/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime |
可以看到持久代被设置为256M,堆内存被设置为6000M(-Xms和--Xmx设为相等避免了“堆震荡”,能在一定程度减少GC次数,但会增加平均每次GC消耗的时间),年轻代被设置为1500M。
-XX:+UseConcMarkSweepGC设置老年代使用CMS(Concurrent Mark-Sweep)收集器。 -XX:+UseParNewGC设置新生代使用并行收集器,-XX:ParallelGCThreads参数指定并行收集器工作线程数,在CPU核数小于等于8时一般推荐与CPU数目一致,但当CPU核数大于8时推荐设置为:3 + [(5*CPU_COUNT) / 8]。其他参数略去不提。
问题发现与解决过程
早上测试找到我说线上系统突然挂了,报访问超时异常。
首先我第一反应是系统内存溢出或者进程被操作系统杀死了。用ps -ef | grep xxx | grep -v grep命令查看进程还在。然后看tomcat的catlalina.out日志和系统gc日志,也未发现有内存溢出。
接下来用jstat -gcutil pid 1000看了下堆中各代的占用情况和GC情况,发现了一个挺恐怖的现象:Eden区占用77%多,S0占用100%,Old和Perm区都有很大空间剩余。
怀疑是新生代空间不足,但没有确凿证据,只好用jstack获取线程Dump信息,不看不知道,一看就发现了一个问题(没有发现线程死锁,这里应该是“活锁”问题):

从上面第一段可看到有一个Low Memory Detector系统内部线程(JVM启动的监测和报告低内存的守护线程)一直占着锁0x00....00,而下面的C2 CompilerThread1、C2 CompilerThread0、Signal Dispatcher和Surrogate Locker线程都在等待这个锁,导致整个JVM进程都hang住了。
在网上搜索一圈,发现大部分都建议调大堆内存,于是根据建议打算调大整个堆内存大小、调大新生代大小(-Xmn参数)、调大新生代中Survivor区占的比例(-XX:SurvivorRatio参数)。并且由于存在AtomicLong数组大对象,所以设置-XX:PretenureThreshold=10000000,即如果某个对象超过10M(单位为字节,所以换算后为10M)则直接进入老年代,注意这个参数只在Serial收集器和ParNew收集器中有效。另外希望大量的长生命周期AtomicLong小对象能够尽快进入老年代,避免老年代的AtomicLong数组对象大量引用新生代的AtomicLong对象,我调小了-XX:MaxTenuringThreshold(这个参数的默认值为15),即现在年轻代中的对象至多能在年轻代中存活8代,如果超过8代还活着,即使那时年轻代内存足够也会被Promote到老年代。有修改或增加的JVM GC参数如下:
|
1
|
-Xms9000M -Xmx9000M -Xmn1500M -XX:SurvivorRatio=6 -XX:MaxTenuringThreshold=8 -XX:PretenureSizeThreshold=10000000 |
重启系统后用jstat -gcutil pid 1000命令发现一个更恐怖的现象,如下图:Eden区内存持续快速增长,Survivor占用依然很高,大概每两分钟就Young GC一次,并且每次Young GC后年老代内存占用都会增加不少,这样导致可以预测每三四个小时就会发生一次Full GC,这是很不合理的。
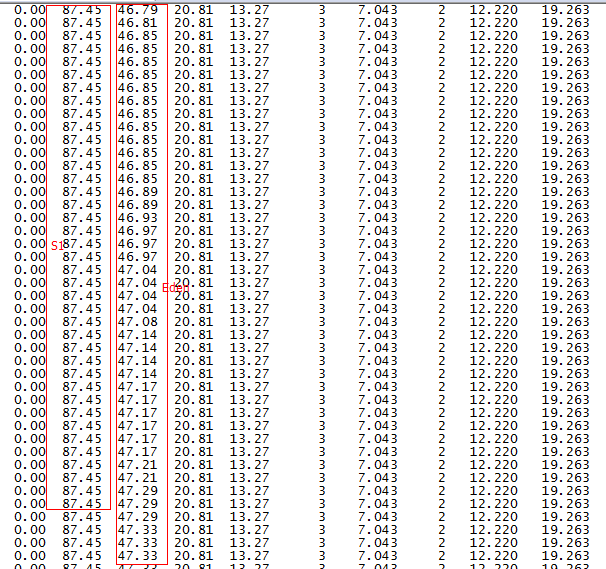
第二列是S1,占用高达87.45%,第三列是Eden区内存占用变化情况,可以看到增长非常快。
于是我用jmap -histo:live(注意jmap命令会触发Full GC,并发访问量较大的线上环境慎用)查看了下活对象,发现有一些Integer数组和一些Character数组占用内存在持续增长,并且占了大概好几百M的内存,然后经过Young GC又下降,然后再次快速增长,再Young GC下降,周而复始。
至此,我推测可能是大量的Integer数组对象和Character数组对象基本占满了Survivor,导致在Eden满了之后,新产生的Integer数组对象和Character数组对象不足以放入Survivor,然后对象被直接被Promote到了年老代,这种推测部分正确,它解释了S1占用那么高的原因,但不能解释上面的Eden区内存占用持续上升。
于是继续查看了下接口调用日志,不看不知道,一看吓一跳:日志刷新非常之快(99%是DEBUG日志)。原来运营和测试在未通知我们服务端的情况下已经于昨天在某个渠道发布了一个Android线上版本(难怪今天就暴露问题了),再看了下使用该系统的用户已经有6400多个了,彻彻底底被他们坑了一把。这就能解释为什么上面有一个Integer数组和Character数组占用内存持续增长了,原因就在于大量的系统接口调用触发了大量DEBUG日志刷新,写日志对于线上系统是一个重量级操作,无论是对CPU占用还是对内存占用,所以高并发线上系统一定要记得调高日志级别为INFO甚至ERROR。
于是修改log4j.properties中的日志级别为INFO,然后用jmap -histo:live pid命令查看活对象,发现Integer数组对象和Character[]数组对象明显下降,并且占用内存也由前面的几百M降到几M。
之后再用jstat -gcutil pid 1000查看了下GC情况,如下:

很明显Survivor占用没这么高了,最重要的Young GC后年老代内存占用不会增加了,此处Eden区增长貌似还是挺快,因为此时用户数比前面多了很多。至此出现的问题基本搞定,但还有待后续观察。
总结
总的来说本系统中存在一个违背GC假设的东西,那就是在JVM堆中存在着海量生命周期较长的小对象(AtomicLong对象)。这无疑会给系统埋坑。
GC分代基本假设是:
|
1
|
JVM堆中存在的大部分对象都是短生命周期小对象。 |
这也是为什么Hotspot JVM的年轻代采用复制算法的原因。
其他推荐一些非常不错的GC方面的参考文章(前两篇都来自《深入理解Java虚拟机》一书,参考链接大部分是我今天查阅的资料,大家选择性看就好):
JVM内存管理:深入Java内存区域与OOM http://www.iteye.com/topic/802573
JVM内存管理:深入垃圾收集器与内存分配策略 http://www.iteye.com/topic/802638
Oracle GC Tuning http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html
Java 6 JVM参数选项大全 http://kenwublog.com/docs/java6-jvm-options-chinese-edition.htm
Java HotSpot VM Options http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html
CMS GC实践总结 http://www.iteye.com/topic/473874
JVM内存的分配及回收 http://blog.csdn.net/eric_sunah/article/details/7893310
一步一步优化JVM系列 http://blog.csdn.net/zhoutao198712/article/category/1194642
Java线程Dump分析 http://www.linuxidc.com/Linux/2009-01/18171.htm http://jameswxx.iteye.com/blog/1041173
利用Java Dump进行JVM故障诊断 http://www.ibm.com/developerworks/cn/websphere/library/techarticles/0903_suipf_javadump/
Detecting Low Memory in Java https://techblug.wordpress.com/2011/07/16/detecting-low-memory-in-java/
Detecting Low Memory in Java Part 2 http://techblug.wordpress.com/2011/07/21/detecting-low-memory-in-java-part-2/
http://blog.sina.com.cn/s/blog_56d8ea9001014de3.html
http://stackoverflow.com/questions/2101518/difference-between-xxuseparallelgc-and-xxuseparnewgc
http://stackoverflow.com/questions/220388/java-concurrent-and-parallel-gc
http://j2eedebug.blogspot.com/2008/12/what-to-look-for-in-java-thread-dumps.html
https://devcenter.heroku.com/articles/java-memory-issues
http://blog.csdn.net/sun7545526/article/category/1193563
http://java.dzone.com/articles/how-tame-java-gc-pauses
引用来自“木木三”的评论我想问一个最后一张图,第6列YGC=4,第8列FGC=9,FGC比YGC次数多,这种现象正常么 |