SQL优化
原因:性能低、执行时间太长了、等待时间太长、SQL语句欠佳(连接查询)、索引失效、服务器参数设置不合理(缓冲)

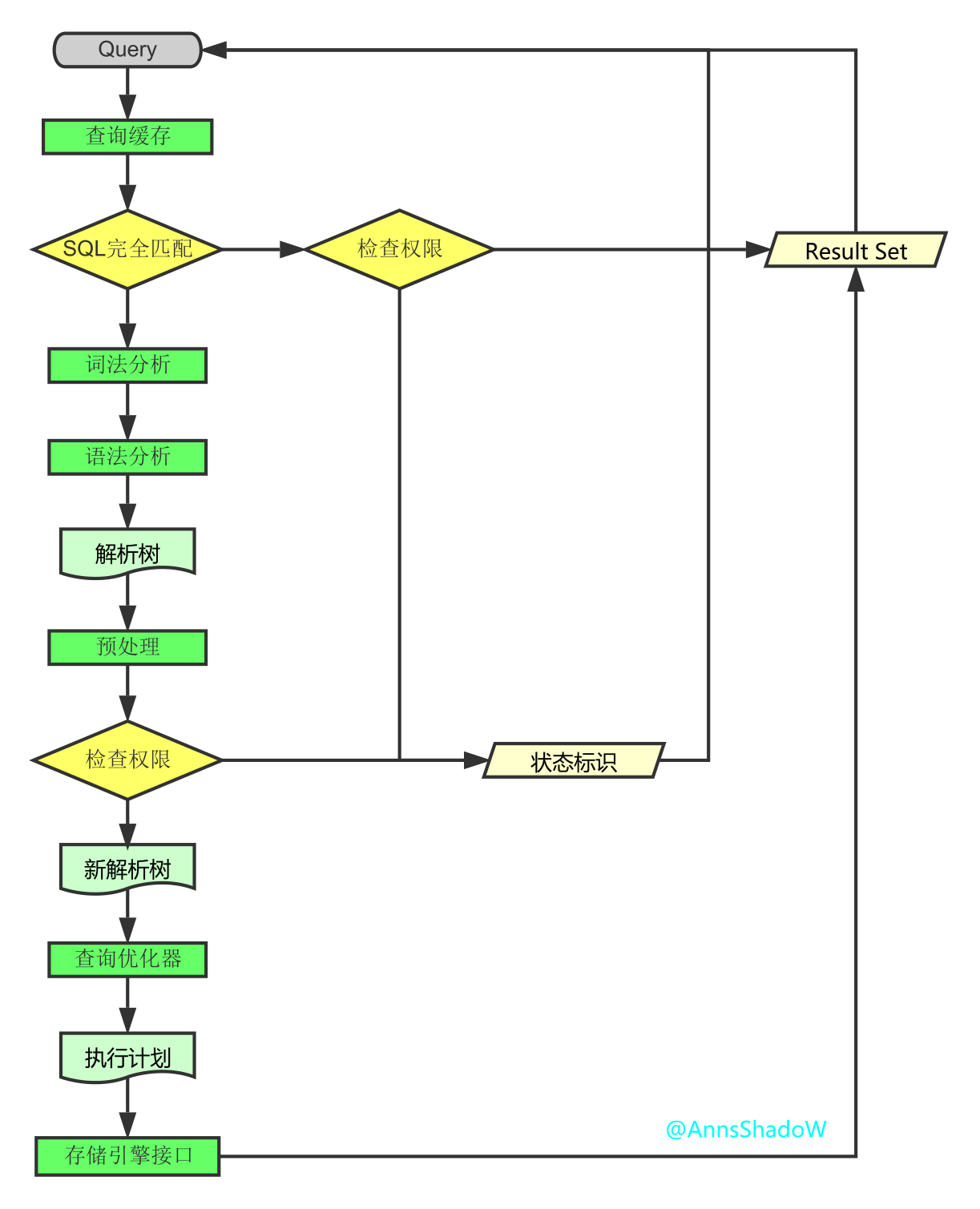
查询执行流程
下面再向前走一些,容我根据自己的认识说一下查询执行的流程是怎样的:
1.连接
1.1客户端发起一条Query请求,监听客户端的‘连接管理模块’接收请求
1.2将请求转发到‘连接进/线程模块’
1.3调用‘用户模块’来进行授权检查
1.4通过检查后,‘连接进/线程模块’从‘线程连接池’中取出空闲的被缓存的连接线程和客户端请求对接,如果失败则创建一个新的连接请求
2.处理
2.1先查询缓存,检查Query语句是否完全匹配,接着再检查是否具有权限,都成功则直接取数据返回
2.2上一步有失败则转交给‘命令解析器’,经过词法分析,语法分析后生成解析树
2.3接下来是预处理阶段,处理解析器无法解决的语义,检查权限等,生成新的解析树
2.4再转交给对应的模块处理
2.5如果是SELECT查询还会经由‘查询优化器’做大量的优化,生成执行计划
2.6模块收到请求后,通过‘访问控制模块’检查所连接的用户是否有访问目标表和目标字段的权限
2.7有则调用‘表管理模块’,先是查看table cache中是否存在,有则直接对应的表和获取锁,否则重新打开表文件
2.8根据表的meta数据,获取表的存储引擎类型等信息,通过接口调用对应的存储引擎处理
2.9上述过程中产生数据变化的时候,若打开日志功能,则会记录到相应二进制日志文件中
3.结果
3.1Query请求完成后,将结果集返回给‘连接进/线程模块’
3.2返回的也可以是相应的状态标识,如成功或失败等
3.3‘连接进/线程模块’进行后续的清理工作,并继续等待请求或断开与客户端的连接
一图小总结
SQL编写过程
SELECT DISTINCT < select_list > FROM < left_table > < join_type > JOIN < right_table > ON < join_condition > WHERE < where_condition > GROUP BY < group_by_list > HAVING < having_condition > ORDER BY < order_by_condition > LIMIT < limit_number >
SQL解析过程
FROM <left_table> ON <join_condition> <join_type> JOIN <right_table> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> SELECT DISTINCT <select_list> ORDER BY <order_by_condition> LIMIT <limit_number>
示例代码
SELECT a.uid, count(b.oid) AS total FROM table1 AS a LEFT JOIN table2 AS b ON a.uid = b.uid WHERE a. NAME = 'mike' GROUP BY a.uid HAVING count(b.oid) < 2 ORDER BY total DESC LIMIT 1;
优化重点
SQL优化的重点就是索引(index,相当于书的目录),索引是帮助MYSQL高效获取数据的数据结构。所以可以说索引是数据结构(树:B树 也是Mysql的默认使用、Hash树...)
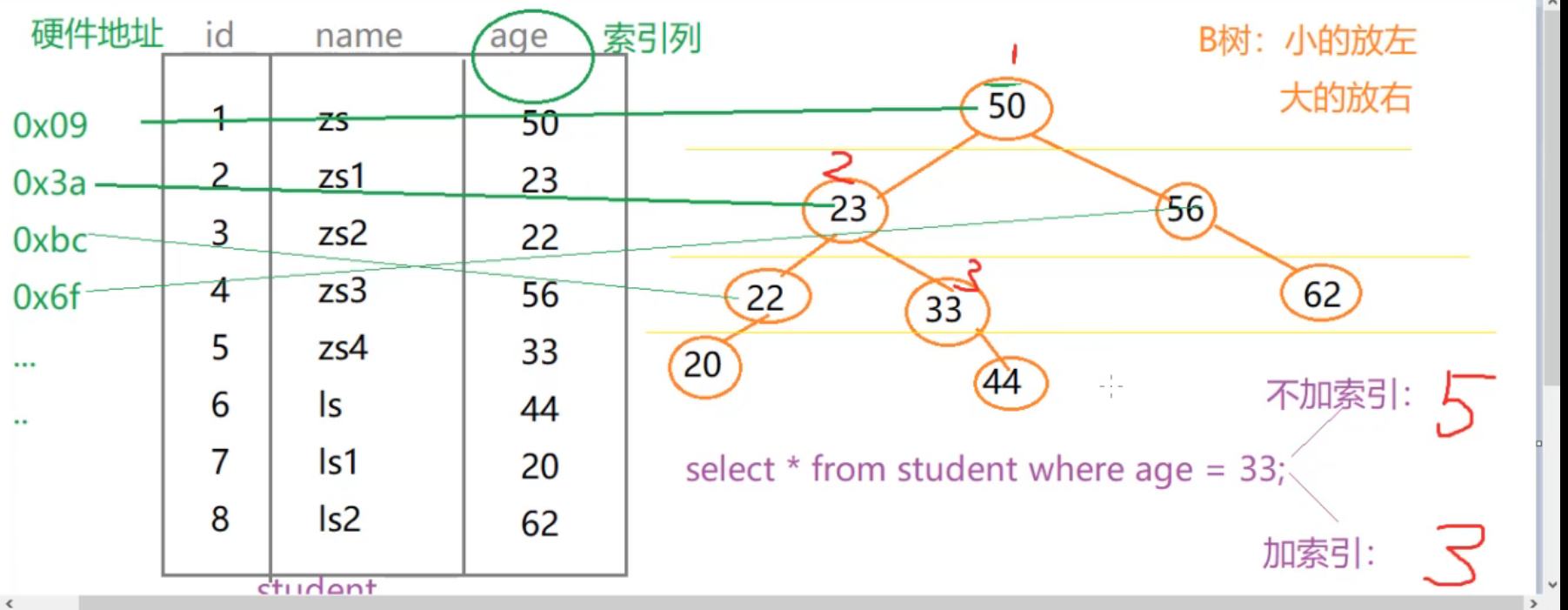
B树索引(一般指B+树)
B+树中查询任意的数据次数:n次,n为B+树的高度,B+树的数据一般全都放在叶子节点

实际示例(该实例是二叉树演示 )
索引弊端
- 索引本身很大,可以存放在内存/硬盘(通常是硬盘)
- 索引不是所有情况都需要用:少量数据、频繁更新的字段、很少用的字段
- 索引确实可以提高查询效率,但是降低了增删改的效率
索引优势
- 提高查询效率,降低I/O使用率
- 降低CPU使用率,例如索引本身就是排好序的树,所以排序的时候不需要再次计算,可以直接查询
索引分类
- 单值索引:单列索引;一个表可以有多个单值索引
- 唯一索引:不能重复,一般用ID
- 复合索引:多个列构成的索引,例如有name和age两列,建复合索引(name,age),那么就先匹配name,然后从name集合中找age,如果找name就一条就直接结束了