Codevs 1076 排序
以本题为例,复习各种排序(部分);
题目描述 Description
给出n和n个整数,希望你从小到大给他们排序
输入描述 Input Description
第一行一个正整数n
第二行n个用空格隔开的整数
输出描述 Output Description
输出仅一行,从小到大输出n个用空格隔开的整数
样例输入 Sample Input
3
3 1 2
样例输出 Sample Output
1 2 3
数据范围及提示 Data Size & Hint
1<=n<=100000
分类标签 Tags 点此展开
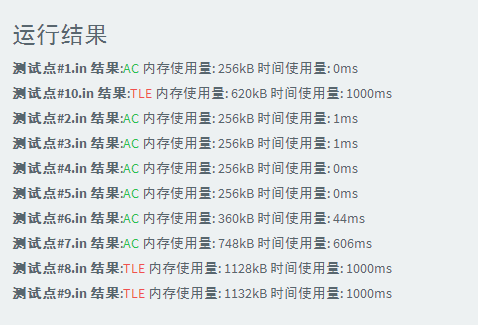
#include<cstdio> using namespace std; #define N 1010000 int a[N],n; int main(){ scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%d",a+i); } for(int i=2,x;i<=n;i++){ x=a[i];int j=i-1; while(x<a[j]&&j>0){ a[j+1]=a[j]; j--; } a[j+1]=x; } for(int i=1;i<=n;i++){ printf("%d ",a[i]); } return 0; }
2、桶排序
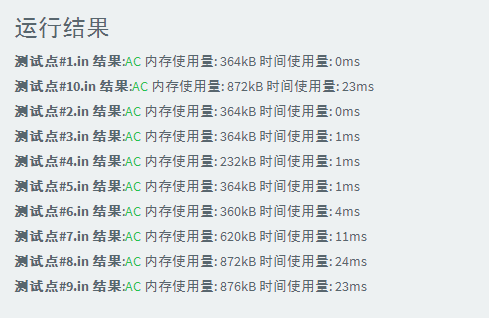
#include<cstdio> #include<iostream> using namespace std; #define N 1010000 int a[N],b,n; int main() { scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%d",&b);a[b]++; } int t=0; for(int i=0;t<n;i++) while(a[i]>0){ printf("%d ",i); a[i]--; t++; } return 0; }
3、快速排序

#include<cstdio> #include<iostream> using namespace std; #define N 1010000 int a[N],n; void quick_sort(int l,int r){ if(l>r) return; int i=l,j=r,mid=a[(l+r)/2];//这里换成mid,下面换成a[mid],就会有错误 while(i<=j){//原因:a[mid]会被更新 while(a[i]<mid) i++; while(a[j]>mid) j--; if(i<=j){ swap(a[i],a[j]); i++;j--; } } if(j>l) quick_sort(l,j); if(i<r) quick_sort(i,r); } int main() { scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%d",a+i); } quick_sort(1,n); for(int i=1;i<=n;i++){ printf("%d ",a[i]); } return 0; }
stl-sort(c++自带快排)
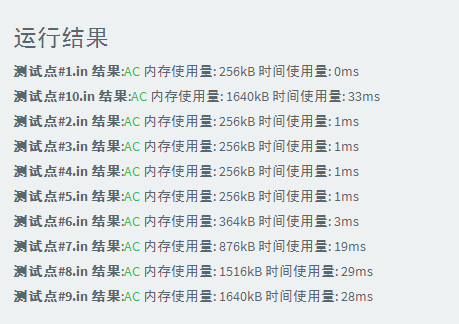
#include<cstdio> #include<algorithm> using namespace std; int a[101000],n; int main() { scanf("%d",&n); for(int i=1;i<=n;i++) scanf("%d",&a[i]); sort(a+1,a+n+1); for(int i=1;i<=n;i++) printf("%d ",a[i]); return 0; }
4、归并排序
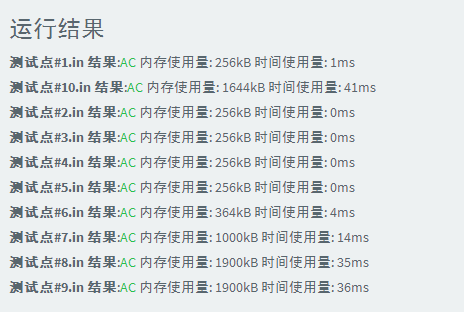
#include<cstdio> #include<iostream> using namespace std; #define N 1001000 int a[N],s[N],n; void merge_sort(int l,int r){ if(l==r) return ; int mid=(l+r>>1); merge_sort(l,mid); merge_sort(mid+1,r); int i=l,j=mid+1,k=l; while(i<=mid&&j<=r){ if(a[i]<=a[j]) s[k++]=a[i++]; else s[k++]=a[j++]; } while(i<=mid) s[k++]=a[i++]; while(j<=r) s[k++]=a[j++]; for(int i=l;i<=r;i++) a[i]=s[i]; } int main(){ scanf("%d",&n); for(int i=1;i<=n;i++) scanf("%d",a+i); merge_sort(1,n); for(int i=1;i<=n;i++) printf("%d ",a[i]); return 0; }
5、堆排序
#include<cstdio> #include<iostream> using namespace std; #define N 1010000 int heap[N],heap_size,n,ans; void put(int x){ int now,next; heap[++heap_size]=x; now=heap_size; while(now>1){ next=now/2; if(heap[next]<=heap[now]) return; swap(heap[next],heap[now]); now=next; } } int get(){ int now,next,res; res=heap[1]; heap[1]=heap[heap_size--]; now=1; while(now*2<=heap_size){ next=now*2; if(next<heap_size&&heap[next+1]<heap[next]) next++; if(heap[now]<=heap[next]) return res; swap(heap[next],heap[now]); now=next; } return res; } int main(){ scanf("%d",&n); for(int i=1,x;i<=n;i++){ scanf("%d",&x); put(x); } for(int i=1,x,y;i<=n;i++){ printf("%d ",get()); } return 0; }
6、缺少:冒泡,拓扑……--其实我的博客有例题,自己搜吧,不在此整理
7、常用排序去重方法
(1)朴素去重
#include<cstdio> #include<algorithm> using namespace std; int a[101],n,f[101]; int main(){ int p,j=1; scanf("%d",&n); for(int i=1;i<=n;i++) scanf("%d",&a[i]); sort(a+1,a+n+1); f[j]=a[1]; p=a[1]; for(int i=2;i<=n;i++) if(a[i]!=p) f[++j]=a[i],p=a[i]; printf("%d ",j);//去重后元素个数 for(int i=1;i<=j;i++) printf("%d ",f[i]);//去重后所有元素 return 0; }
(2)STL去重
#include<cstdio> #include<algorithm> using namespace std; #define N 1010 int a[N],n; int main(){ scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%d",a+i); } sort(a+1,a+n+1); int m=unique(a+1,a+n+1)-(a+1); printf("%d ",m); for(int i=1;i<=m;i++){ printf("%d ",a[i]); } return 0; }