问题:
工作过程中,不管是什么项目,伴随着项目不断升级版本,对应的项目数据库业务版本也不断升级,数据库出现新增表、修改表、删除表、新增字段、修改字段、删除字段等变化,如果人工检查,数据库表和字段比较多的话,工作量就非常大。
解决方案:
这里博主为大家分享一个在工作过程中编写的自动检查数据库表结构版本差异的通用脚本,只需要把新旧数据库名称批量替换成实际的名称就可以,支持通过链接服务器跨服务器检查不同服务器的两个数据库表结构差异。
脚本:
/*
使用说明:Old数据库为DB_V1,New数据库为[localhost].DB_V2。根据实际需要批量替换数据库名称
脚本来源:https://www.cnblogs.com/zhang502219048/p/11028767.html
*/
-- sysobjects插入临时表
select s.name + '.' + t.name as TableName, t.* into #tempTA
from DB_V1.sys.tables t
inner join DB_V1.sys.schemas s on s.schema_id = t.schema_id
select s.name + '.' + t.name as TableName, t.* into #tempTB
from [localhost].DB_V2.sys.tables t
inner join [localhost].DB_V2.sys.schemas s on s.schema_id = t.schema_id
-- syscolumns插入临时表
select * into #tempCA from DB_V1.dbo.syscolumns
select * into #tempCB from [localhost].DB_V2.dbo.syscolumns
-- 第一个数据库表和字段
select b.TableName as 表名, a.name as 字段名, a.length as 长度, c.name as 类型
into #tempA
from #tempCA a
inner join #tempTA b on b.object_id = a.id
inner join systypes c on c.xusertype = a.xusertype
order by b.name
-- 第二个数据库表和字段
select b.TableName as 表名, a.name as 字段名, a.length as 长度, c.name as 类型
into #tempB
from #tempCB a
inner join #tempTB b on b.object_id = a.id
inner join systypes c on c.xusertype = a.xusertype
order by b.name
--删掉的字段
select * from
(
select * from #tempA
except
select * from #tempB
) a;
--增加的字段
select * from
(
select * from #tempB
except
select * from #tempA
) a;
--select * from #tempA
--select * from #tempB
drop table #tempTA, #tempTB, #tempCA, #tempCB, #tempA, #tempB
示例旧数据库DB_V1: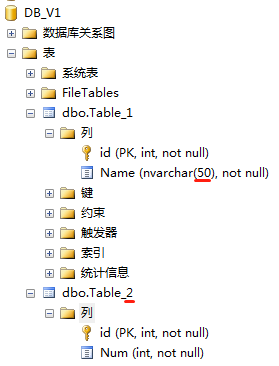
示例新数据库DB_V2: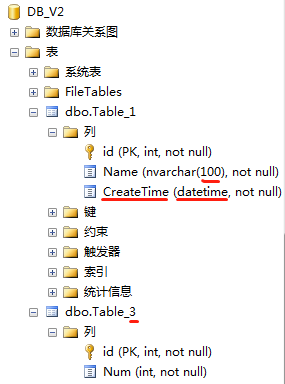
脚本运行结果:
结论:
从上面几个图可以看到,表和字段的差异部分就被自动检测到了。