1. MapReduce整体流程

1、 每个map,reduce都作为1个独立进程process启动(多进程并发方式,spark是多线程并发)
2、 由于进程空间独享,因此方便控制每个map, reduce任务的资源和调配,但进程的启动慢
3、 多线程运行的更快,因此spark有更高的时效性,缺点在于多线程带来的稳定性低(相比map, reduce)
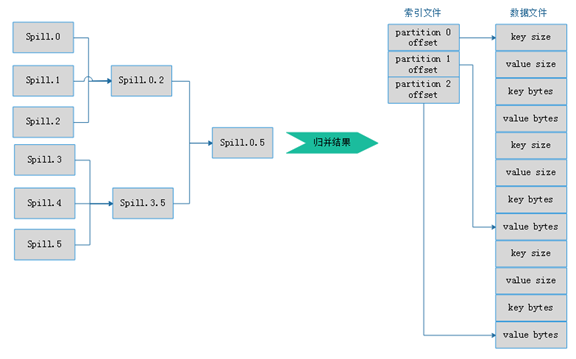
2. Map: split->RR->map->partition tag->spill(sort)->merge
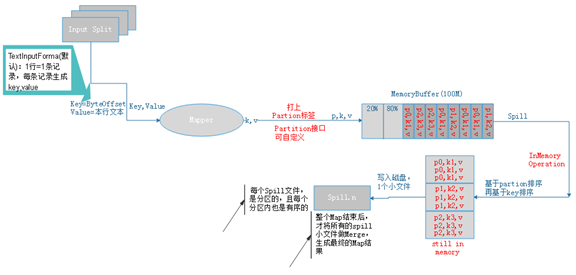
Inputformat如何保证Record记录完整性?
Inputformat包含Data Split、Record Reader两部分功能。 Inputformat根据block进行Split, 当有一个记录横跨在两个block上时,会将这条记录归属于前一个split (该split的大小就大于1个block大小),从而保证记录不会被切散
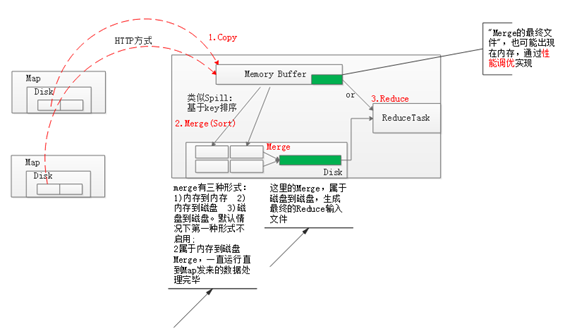
3. Reduce: copy- sort(merge) - reduce
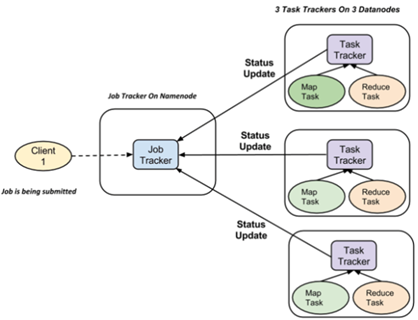
4. MapReduce的Job管理
|
|
所在位置 |
数量 |
作用 |
|
Job Tracker |
可以和HDFS Namenode同机器部署,但大型集群会和namenode分开 |
1个集群只有1个JobTracker进程 |
1.处理来自JobClient的作业请求 2.处理TaskTracker每3秒发来的心跳,根据心跳进行作业调度(及“重新”调度),任务进度监控等 Note:通过“线程池” 来同时处理心跳和JobClient请求 |
|
Task Tracker |
HDFS Datanode上 |
1个节点1个TaskTracker进程 |
1、每3秒汇报一次:1)正在运行的任务详情 2)可用的map, reduce任务数 2、map, reduce任务的执行 |
FAQ、在哪些节点上启动Map程序
Split计算后会知道每个split的大小以及位置,Map遵循就近原则,尽量在数据所在的datanode上启动map进程