0. 说明
HDFS 初始化文件系统分析 && HDFS 文件写入流程 && HDFS 文件读取流程分析
有价值的相关文章:
1. HDFS 初始化文件系统分析
- 通过两个配置文件 core-site.xml 和 core-default.xml 初始化 configuration
- 通过配置文件中的 fs.defaultFS 指定的值初始化文件系统
file:/// =====> org.apache.hadoop.hdfs.LocalFileSystem hdfs://xxxx =====> org.apache.hadoop.hdfs.DistributedFileSystem
2. HDFS 文件写入流程分析一
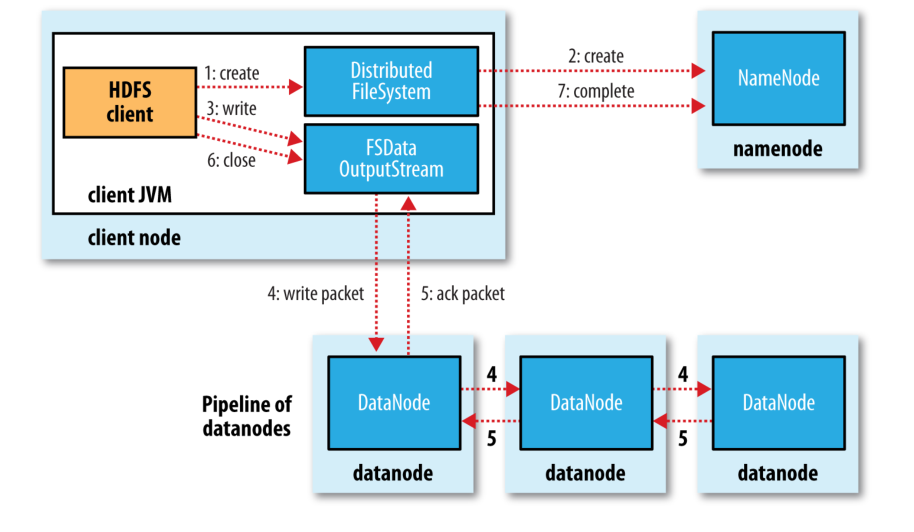
具体过程描述如下:
1. Client 调用 DistributedFileSystem 对象的 create 方法,创建一个文件输出流(FSDataOutputStream)对象
2. 通过 DistributedFileSystem 对象与 Hadoop 集群的 NameNode 进行一次 RPC 远程调用,在 HDFS 的 Namespace 中创建一个文件条目(Entry),该条目没有任何的 Block
3. 通过 FSDataOutputStream 对象,向 DataNode 写入数据,数据首先被写入 FSDataOutputStream 对象内部的 Buffer 中,然后数据被分割成一个个 Packet 数据包
4. 以 Packet 最小单位,基于 Socket 连接发送到按特定算法选择的 HDFS 集群中一组 DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组 DataNode 组成的 Pipeline 上依次传输 Packet
5. 这组 DataNode 组成的 Pipeline 反方向上,发送ack,最终由Pipeline 中第一个 DataNode 节点将 Pipeline ack 发送给 Client
6. 完成向文件写入数据,Client 在文件输出流(FSDataOutputStream)对象上调用 close 方法,关闭流
7. 调用 DistributedFileSystem 对象的 complete 方法,通知 NameNode 文件写入成功
3. HDFS 文件写入流程另一种描述
客户端要向 HDFS 写数据,首先要跟 NameNode 通信以确认可以写文件并获得接收文件 block 的 DataNode,然后,客户端按顺序将文件逐个 block 传递给相应 DataNode ,并由接收到 block 的 DataNode 负责向其他 DataNode 复制 block 的副本
如图:
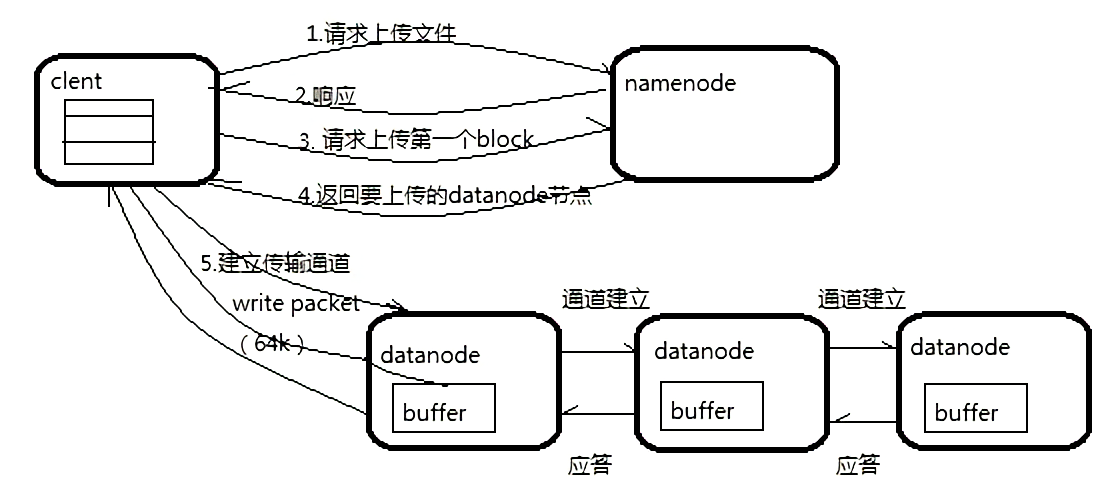
写详细步骤:
1. Client 与 NameNode 通信请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在
2. NameNode 返回是否可以上传
3. Client 会先对文件进行切分,比如一个 block 块 128m,文件有 300m 就会被切分成3个块,一个 128M、一个 128M、一个 44M 请求第一个 block 该传输到哪些 DataNode 服务器上
4. NameNode返回 DataNode 的服务器
5. Client 请求一台 DataNode 上传数据(本质上是一个 RPC 调用,建立 Pipeline),第一个 DataNode 收到请求会继续调用第二个 DataNode,然后第二个调用第三个 DataNode,将整个 Pipeline建立完成,逐级返回客户端
6. Client 开始往A上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(一个 packet 为64kb),当然在写入的时候 DataNode 会进行数据校验,它并不是通过一个 packet 进行一次校验而是以 chunk 为单位进行校验(512byte),第一台 DataNode 收到一个 packet 就会传给第二台,第二台传给第三台;第一台每传一个 packet 会放入一个应答队列等待应答
7. 当一个 block 传输完成之后,Client 再次请求 NameNode 上传第二个 block 的服务器。
4. HDFS 文件写入流程详情图
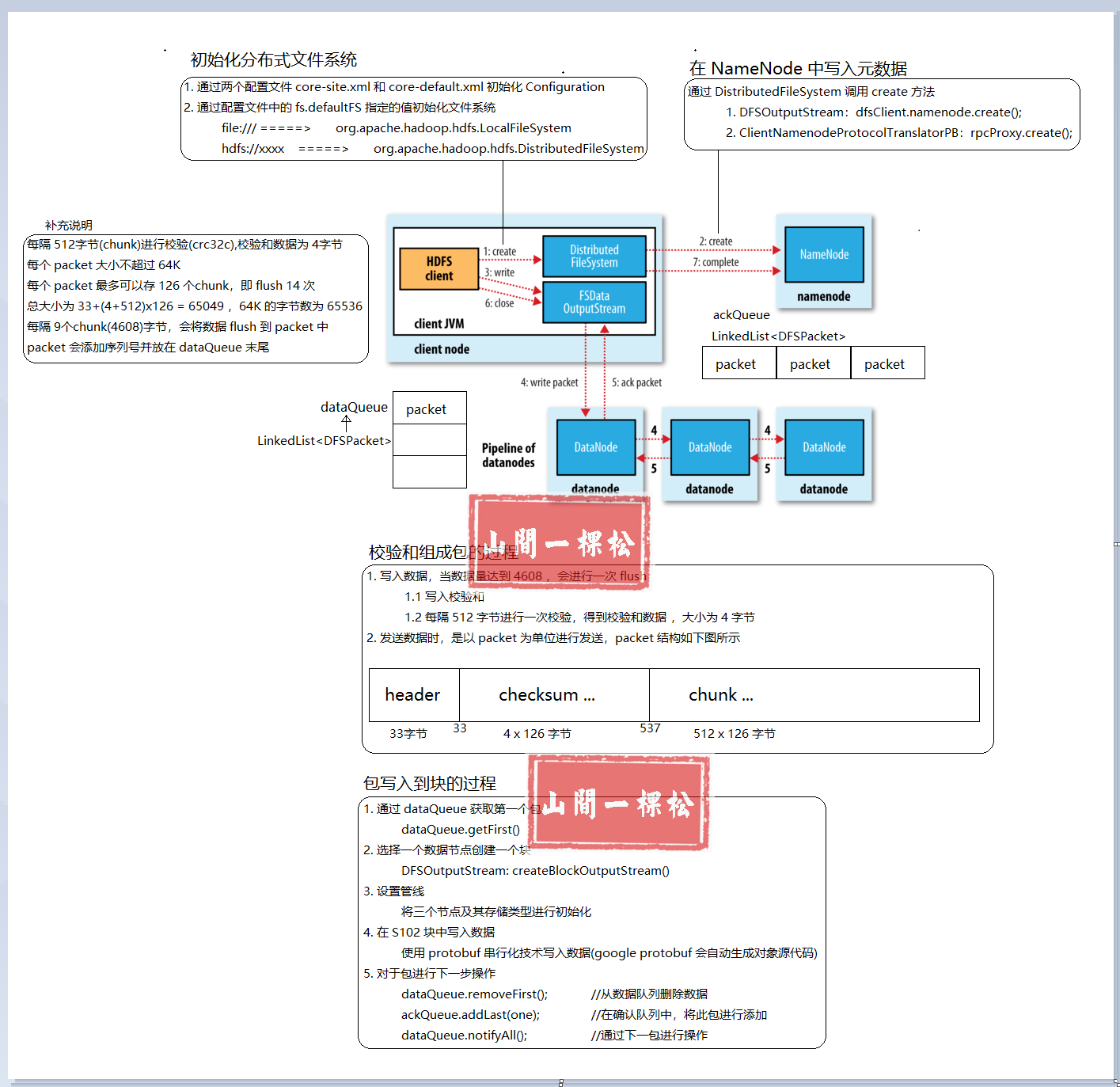
【相关概念】
1. chunk
小块
2. packet
基础数据会分割成很多个 packet 通过数据队列进行数据发送
包 = (小块+校验和)x126
3. HDFS 中 packet 的结构如下

4. checksum
默认校验和是 CRC32C 算法
每隔512字节进行校验,同时产生4字节的校验和
5. HDFS 文件读取流程分析
客户端将要读取的文件路径发送给 NameNode , NameNode 获取文件的元信息(主要是 block 的存放位置信息)返回给客户端,客户端根据返回的信息找到相应 DataNode逐个获取文件的 block 并在客户端本地进行数据追加合并从而获得整个文件
如图:
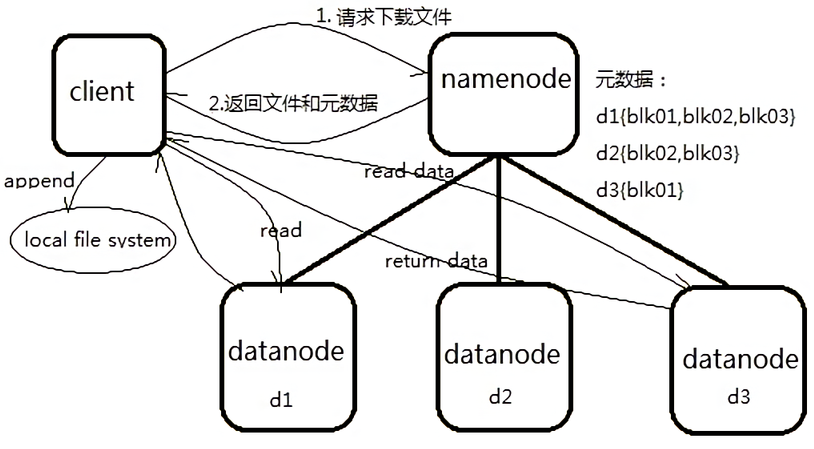
读详细步骤:
1. Client 与 NameNode 通信查询元数据( block 所在的 DataNode 节点),找到文件块所在的 DataNode 服务器
2. 挑选一台 DataNode (就近原则,然后随机)服务器,请求建立socket流
3. DataNode 开始发送数据(从磁盘里面读取数据放入流,以 packet 为单位来做校验)
4. 客户端以 packet 为单位接收,先在本地缓存,然后写入目标文件,后面的 block 块就相当于是 append 到前面的 block 块最后合成最终需要的文件。