0. 说明
Spark Streaming 介绍 && 在 IDEA 中编写 Spark Streaming 程序
1. Spark Streaming 介绍
Spark Streaming 是 Spark Core API 的扩展,针对实时数据流计算,具有可伸缩性、高吞吐量、自动容错机制的特点。
数据源可以来自于多种方式,例如 Kafka、Flume 等等。
使用类似于 RDD 的高级算子进行复杂计算,像 map 、reduce 、join 和 window 等等。
最后,处理的数据推送到数据库、文件系统或者仪表盘等。也可以对流计算应用机器学习和图计算。

在内部,Spark Streaming 接收实时数据流,然后切割成一个个批次,然后通过 Spark 引擎生成 result 的数据流。
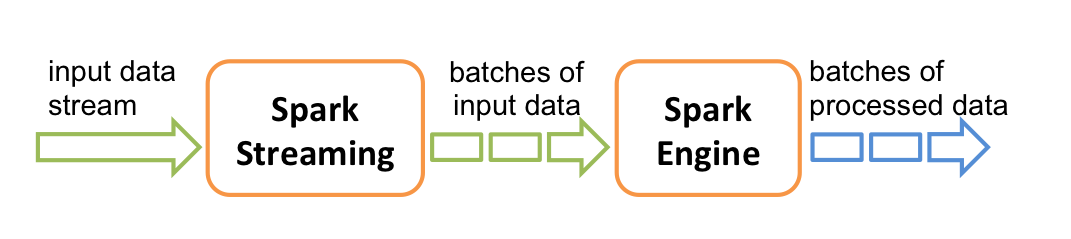
Spark Streaming 提供了称为离散流(DStream-discretized stream)的高级抽象,代表了连续的数据流。离散流通过 Kafka、 Flume 等源创建,也可以通过高级操作像 map、filter 等变换得到,类似于 RDD 的行为。内部,离散流表现为连续的 RDD。
2. 在 IDEA 中编写 Spark Streaming 程序(Scala)
【2.1 添加依赖】
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.share</groupId> <artifactId>myspark</artifactId> <version>1.0-SNAPSHOT</version> <properties> <spark.version>2.1.0</spark.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.17</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> </dependencies> </project>
【2.2 编写代码】
package com.share.sparkstreaming.scala import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} /** * Spark Streaming 的 Scala 版 Word Count 程序 */ object SparkStreamingScala1 { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName("Streaming") // 至少2 以上 conf.setMaster("local[2]") // 创建 Spark Streaming Context ,间隔 1 s val sc = new StreamingContext(conf , Seconds(1)) // 对接 socket 文本流 val lines = sc.socketTextStream("s101", 8888) val words = lines.flatMap(_.split(" ")) val pair = words.map((_,1)) val rdd = pair.reduceByKey(_+_) // 打印结果 rdd.print() // 启动上下文 sc.start() // 等待停止 sc.awaitTermination() } }
【2.3 修改 Log4j 日志输出级别】

【2.4 启动服务器 s101 的 nc】
nc -lk 8888
【2.5 运行程序并验证】
略
3. 在 IDEA 中编写 Spark Streaming 程序(Java)
package com.share.sparkstreaming.java; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; import java.util.Arrays; import java.util.Iterator; /** * Spark Streaming 的 Scala 版 Word Count 程序 */ public class WordCountStreamingJava1 { public static void main(String[] args) throws InterruptedException { SparkConf conf = new SparkConf(); conf.setAppName("Streaming"); conf.setMaster("local[*]"); // 创建 Spark Streaming Context ,间隔 2 s JavaStreamingContext sc = new JavaStreamingContext(conf, Durations.seconds(2)); // 对接 socket 文本流 JavaDStream<String> ds1 = sc.socketTextStream("s101", 8888); // 压扁 JavaDStream<String> ds2 = ds1.flatMap(new FlatMapFunction<String, String>() { public Iterator<String> call(String s) { return Arrays.asList(s.split(" ")).iterator(); } }); // 变换成对 JavaPairDStream<String, Integer> ds3 = ds2.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<String, Integer>(s, 1); } }); // 聚合 JavaPairDStream<String, Integer> ds4 = ds3.reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); // 打印结果 ds4.print(); // 启动上下文 sc.start(); // 等待停止 sc.awaitTermination(); } }