0. 说明
由于原先自己搭的博客系统出问题了,故将其中有价值的内容迁移出来,并对文章进行更新。
发现博客园的文章不能置顶,所以又把它以随笔的形式再写一份。
原文链接: 基于大数据的餐饮推荐系统总结
可视化部分总结:Spring Boot 学习笔记
博客园本文章链接:基于大数据的餐饮推荐系统总结
1. 介绍
推荐系统不单单指某一方面的技术,而是作为一个完整的系统而存在,要考虑到很多方面才能做出一个有价值的推荐系统。
在信息过载的时代,有太多的信息被产生,推荐系统的作用是让人们在海量的信息中查看到更多有效的信息。
推荐系统的价值在生活中的许多方面都有体现,浏览器、社交软件、购物软件等中都能看到其身影,为用户提供个性化推荐,在引导用户浏览商品信息的同时带动消费。大数据时代,数据就是一种资源,为了资源能有效的使用,我们需要在数据中通过一定的方式得到有价值的信息。
通过大数据技术搭建平台,基于平台进行推荐业务代码的编写,将大数据技术与推荐系统结合在一起,可以带来更高的价值。通过基于大数据的推荐系统处理海量的数据得出有价值的推荐结果。
2. 说明
最初是想学习大数据相关技术,然后从事和大数据相关的职业,所以在毕业设计选题时选择了《基于大数据的餐饮推荐系统设计》。
真正在查了很多资料才发现可能想的有点简单了,从零开始突然发现自己面对的是一个庞然大物的时候是不知所措的。
在和朋友的交流中的出一个结论:先做一个最简单的,再慢慢优化。
在一步一步的试错中前行。
3. 过程
3.1 技术选型
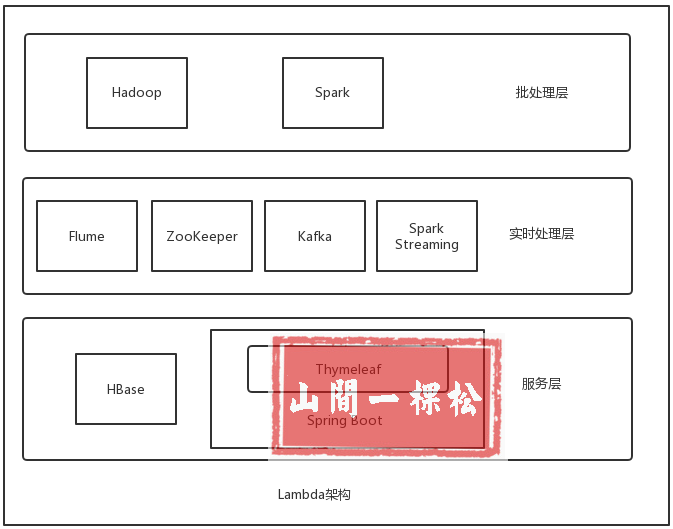
最初的设想是要实现离线推荐与实时推荐,最终选定了 Lambda 架构。
Lambda 架构的主要思想是将大数据系统构建为多个层次。
这里分为三层: 批处理层、实时处理层、服务层。
批处理层: 负责处理离线数据产生离线推荐信息
实时处理层: 负责处理实时数据产生实时推荐信息
服务层: 实现与用户的交互,将推荐数据信息可视化展示给用户
3.2 数据
不同于图书与音乐之类的数据,餐饮数据并不好量化。
以音乐为例,可以很清晰的以歌曲名称、歌手、热度、类型等来实现量化。
而餐饮数据充满着不确定性,一种食物每家饭店可能都做得不一样。
我觉得最好状态的是为每个用户创建画像,并为每种食物建立详细描述的标签,通过二者的关联度进行相关推荐。
技术无止境,但都是服务于业务,以上的想法要实现还有很长的路要走。
美团和饿了么都未提供经过脱敏的餐饮数据,也没有相关的支持。
所以数据只能自己造,使用 Python 写了一个小的餐饮评分数据生成器,通过其产生数据作为数据来源。
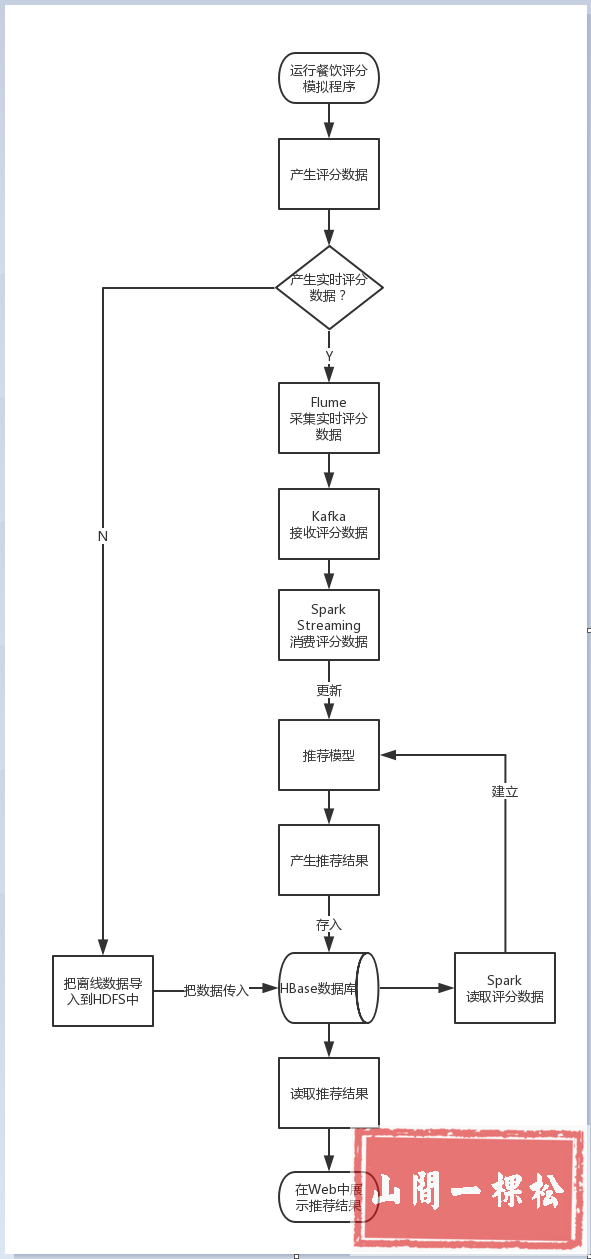
离线数据产生了10万条,实时数据是通过 Linux 的定时执行工具 crontab 定时执行 Python 脚本。
首先要将离线评分数据写入 HBase 数据库,先把本地的数据导入到 HDFS 中,在将其从 HDFS 中传输到 HBase 数据库中。
3.3 大数据平台的搭建
完成大数据平台的搭建。
3.4 推荐代码的编写
通过业务代码实现对餐饮的推荐,最终选用了 Spark MLlib 中的 ALS 算法。
考虑过基于用户或基于商品的算法进行相关推荐,自己生成的餐饮数据的数量与特征与以上不是很匹配,就选了个基于评分数据的协同过滤算法。
相对来说这是比较简单的一种方式。
如何在搭建好并经过连通性测试的大数据平台上进行业务代码的编写,也就是整合 ALS。22基于Spark机器学习跟实时流计算的智能推荐系统 给了我很大的启发。首先是在思想上的,这篇文章让我对 ALS 的原理与整个推荐系统的流程有了初步的认识。其次是将他的核心业务代码移植到我的毕业设计中去,虽然有些代码的细节具体用法不是很懂,但是大致上的意思能理解个大概。
计划在学习了 Scala 之后把注释写完整,思路再理一遍。
作者的可视化界面使用 ASP.NET 编写的,出于节省内存的目的我这里采用的 Spring Boot框架整合 Thymeleaf模板。
与作者相比,我在搭建大数据平台的时候用到了更多的大数据组件,但是作者在三年前就已经完成了业务代码的编写,在网上搜相关问题都能看到他的提问。
4. 系统流程图
5. 项目地址
6. 优化思路
6.1 增加数据真实性与维度
经过实际测试,没有真实的数据来源得到的推荐结果并没有实际价值,也无法得出合适的参数优化模型。
所以可以提高数据的真实性或直接采用真实数据进行测试。
数据过于单一,需要增加维度。
6.2 添加冷启动
由于一切都是基于用户对餐饮数据的评分而产生的推荐结果,新的用户并未产生评分数据。
缺乏评分也就无法实现推荐,像我们现在注册账户刚登进去就会给我们很多选项,让我们选择自己感兴趣的。
这些都是实现了冷启动,通过这些确定了我们的爱好偏向,保证了在缺乏足够的数据之前进行相关推荐。
综上所述,添加冷启动还是很有必要的。
6.3 采用多种推荐算法
不同于传统推荐系统,现阶段的推荐系统是一个综合性质的应用,已经不再满足使用单一推荐算法完成推荐,融合众多推荐算法发挥他们的优势完成推荐才能使推荐系统更好地为人们服务。
本设计采用的是机器学习库中的ALS算法,在之后的研究与学习中还应该融合其他优秀的推荐算法,基于实际需求充分发挥每个推荐算法的优势,搭建出更优秀的推荐系统。
6.4 提高硬件配置
受限于电脑内存、电脑性能和机器数量,要同时兼顾平台的搭建、大数据各组件的运行和代码的开发运行,在大数据推荐平台的搭建上选择伪分布式安装并未用到集群,不能完整地发挥大数据的优势。
在代码编写完成后的运行速度与效率也受到限制,规模与真正的应用存在差距。在以后的工作中希望可以在这些方面得到更好的锻炼。
7. 总结
最终虽然完成了推荐系统的设计,但是也发现了许多问题与不足。
整体过程中遇到了很多坑,一直在踩坑与爬坑。
挺感谢这段经历的,在这个过程中收获了很多。
下一阶段的目标是把基础打牢,然后跟着官网更深入地学习大数据。