转载请注明出处:https://www.cnblogs.com/shapeL/p/9188495.html
前言:上篇文章python3+requests+unittest:接口自动化测试(一):https://www.cnblogs.com/shapeL/p/9179484.html ,已经介绍了基于unittest框架的实现接口自动化,但是也存在一些问题,比如最明显的测试数据和业务没有区分开,接口用例不便于管理等,所以又对此修改完善。接下来主要是介绍该套接口自动化框架的设计到实现,参考代码的git地址:https://github.com/zhangying123456/python3_interface
1.代码框架展示
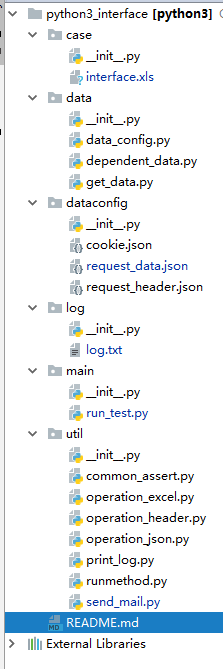
(1)case:存放测试用例数据的,比如请求类型get/post、请求url、请求header、请求数据等;
(2)data:获取excel文件中相应数据的方法封装,获取excel中对应表格内的数据,excel的行列数据等:get_data.py;判断用例之间是否存在依赖关系并获取依赖数据:dependent_data.py;初始化excel文件:data_config.py;
(3)dataconfig:存放请求中涉及到的header、data、cookies等数据;
(4)log:存放测试完成之后生成的日志文件,可以查看日志定位问题;
(5)main:脚本执行的主函数run_test.py
(6)util:通用方法的封装,各种不同断言方式common_assert.py;对excel文件的读写操作operation_excel.py;从请求返回数据中拿取数据作为下一个接口的请求header数据operation_header.py;从json文件中拿取想要的数据operation_json.py;将接口自动化过程中的相关日志输出到log.txt中print_log.py;根据请求类型的不同执行对应的get/post方法runmethod.py;将测试结果以邮件形式发送给相关人员send_mail.py。
2.代码实现说明
(1)首先看下用例数据
说明:该用例只是用来覆盖一些接口场景而测试使用的,有兴趣的可以参考源码用自己项目的真实数据来实现

先判断是否执行:如果yes,执行该条用例;如果no,直接跳过该条用例。
执行用例:获取用例的url、请求类型、请求头header、请求数据,request.get/post执行该条接口用例。
在执行用例过程中,会存在特殊情况:(1)比如test_04依赖于test_03,test_04中的请求字段supplier的参数数据来源于test_03的response中value[0].biz字段的数据,所以在执行接口过程中需要判断是否存在依赖关系;(2)比如test_06请求数据需要test_05的response中的cookies数据,所以这种类型接口也要特殊处理。
执行完成后:写入实际结果,与预期结果做对比,进行断言。
(2)看了用例excel后,对基本的流程有个大概了解,现在的问题就是如何拿取对应的数据执行接口得到运行结果
if is_run: url = self.data.get_request_url(i) method = self.data.get_request_method(i) #获取请求参数 data = self.data.get_data_value(i) # 获取excel文件中header关键字 header_key = self.data.get_request_header(i) # 获取json文件中header_key对应的头文件数据 header = self.data.get_header_value(i) expect = self.data.get_expect_data(i) depend_case = self.data.is_depend(i)
举例说明1:请求url数据是存放在excel中,我们通过操作excel文件到特定单元格拿到url数据
#获取url def get_request_url(self,row): col = int(data_config.get_url()) url = self.oper_excel.get_cell_value(row,col) return url
举例说明2:请求头header或者请求数据中有的数据为空,所以我们在拿取数据过程中要做判断
#获取请求数据 def get_request_data(self,row): col = int(data_config.get_data()) data = self.oper_excel.get_cell_value(row,col) if data == '': return None return data
首先拿取excel中表格中的关键字,再通过关键字去对应json文件拿取具体的请求数据。比如先拿取excel中请求数据中的hotwords,再根据此关键字去json文件读取hotwords的键值数据
"hotwords": { "bizName": "globalSearchClient", "sign": "8c8bc3ee9d6c4b7b8a390ae298cb6db5", "timeMills": "1524906299999" }
#通过获取请求关键字拿到data数据 def get_data_value(self,row): oper_json = OperationJson('../dataconfig/request_data.json') request_data = oper_json.get_data(self.get_request_data(row)) return request_data
#根据关键字获取数据 ''' dict['key']只能获取存在的值,如果不存在则触发KeyError dict.get(key, default=None),返回指定键的值,如果值不在字典中返回默认值None excel文件中请求数据有可能为空,所以用get方法获取 ''' def get_data(self,key): # return self.data[key] return self.data.get(key)
(3)一般的接口都是单接口,即是单独请求,没有上下依赖关系的,针对这种只要模拟请求拿到数据进行断言就可以了。但是实际项目中会存在特殊场景,比如test_03和test04
说明:test_04中,请求数据qqmusic_more中的supplier字段依赖于test_03中的返回数据value[0].biz的值
"qqmusic_more": { "bizName": "globalSearchClient", "appLan": "zh_CN", "musicLimit": "20", "imei": "864044030085594", "keyword": "fly", "timeMills": "1527134461256", "page": "0", "sign": "17daa7e3e84bd4dfbe9a1bd9a1bd7e62", "mac": "90f05205d7b7", "sessionId": "43e605b914874cd99b47ac997e19c1a1", "network": "1", "supplier": "", "language": "zh_CN", }
先执行test_03,获取依赖的返回数据value[0].biz的值
#执行依赖测试,获取test_03返回结果 def run_dependent(self): row_num = self.oper_excel.get_row_num(self.case_id) request_data = self.data.get_data_value(row_num) header = self.data.get_request_header(row_num) method = self.data.get_request_method(row_num) url = self.data.get_request_url(row_num) res = self.method.run_main(method,url,request_data,header,params=request_data) return res #获取依赖字段的响应数据:通过执行依赖测试case来获取响应数据,响应中某个字段数据作为依赖key的value def get_value_for_key(self,row): #获取依赖的返回数据key depend_data = self.data.get_depend_key(row) print(depend_data) #depend_data打印数据:value[0].biz #执行依赖case返回结果 response_data = self.run_dependent() # print(depend_data) # print(response_data) return [match.value for match in parse(depend_data).find(response_data)][0]
再将value[0].biz值放入test_04请求数据qqmusic_more中的supplier字段中
if depend_case != None: self.depend_data = DependentData(depend_case) #获取依赖字段的响应数据 depend_response_data = self.depend_data.get_value_for_key(i) #获取请求依赖的key depend_key = self.data.get_depend_field(i) #将依赖case的响应返回中某个字段的value赋值给该接口请求中某个参数 data[depend_key] = depend_response_data
(4)拿到请求相关数据后,执行该条case,获取response;然后实际结果与预期结果进行断言
res = self.run_method.run_main(method,url,data,header,params=data) ''' get请求参数是params:request.get(url='',params={}),post请求数据是data:request.post(url='',data={}) excel文件中没有区分直接用请求数据表示,则data = self.data.get_data_value(i)拿到的数据,post请求就是data=data,get请就是params=data '''
根据get、post类型区分
class RunMethod: def post_main(self,url,data,header=None): res = None if header != None: res = requests.post(url=url,data=data,headers=header) else: res = requests.post(url=url,data=data) return res.json() def get_main(self,url,params=None,header=None): res = None if header != None: res = requests.get(url=url, params=params, headers=header) else: res = requests.get(url=url, params=params) return res.json() def run_main(self,method,url,data=None,header=None,params=None): res = None if method == 'post': res = self.post_main(url,data,header) else: res = self.get_main(url,params,header) return res
(5)执行接口case过程中,可能存在某条case异常报错,导致下面的case无法运行,所以我们既要将异常日志存放在特定文件中方便后续排查,也要保证下面的case能够不受影响继续执行完
try:... except Exception as e: # 将报错写入指定路径的日志文件里 with open(log_file,'a',encoding='utf-8') as f: f.write(" 第%s条用例报错: " % i) initLogging(log_file,e) fail_count.append(i)
抓取日志的方法可以使用python内置模块logging,具体用法可以参考:https://www.cnblogs.com/shapeL/p/9174303.html
import logging def initLogging(logFilename,e): logging.basicConfig( level = logging.INFO, format ='%(asctime)s-%(levelname)s-%(message)s', datefmt = '%y-%m-%d %H:%M', filename = logFilename, filemode = 'a') fh = logging.FileHandler(logFilename,encoding='utf-8') logging.getLogger().addHandler(fh) log = logging.exception(e) return log
日志文件log.txt结果:直接定位问题出在哪儿
第5条用例报错: 18-06-19 10:27-ERROR-string indices must be integers Traceback (most recent call last): File "C:/Users/xxx/Documents/GitHub/python3_interface/main/run_test.py", line 70, in go_on_run op_header.write_cookie() File "C:UsersxxxDocumentsGitHubpython3_interfaceutiloperation_header.py", line 30, in write_cookie cookie = requests.utils.dict_from_cookiejar(self.get_cookie()) File "C:Userszhangying1DocumentsGitHubpython3_interfaceutiloperation_header.py", line 25, in get_cookie url = self.get_response_url()+"&callback=jQuery21008240514814031887_1508666806688&_=1508666806689" File "C:UsersxxxDocumentsGitHubpython3_interfaceutiloperation_header.py", line 18, in get_response_url url = self.response['data']['url'][0] TypeError: string indices must be integers
(6)接口自动化测试执行完成后,需要将测试结果发送给项目组相关人员,邮件发送实现方法参考:https://www.cnblogs.com/shapeL/p/9115887.html
self.send_mail.send_main(pass_count,fail_count,no_run_count)
#coding:utf-8 import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart import datetime class SendEmail: global send_user global email_host global password password = "lunkbrgwqxhfjgxx" email_host = "smtp.qq.com" send_user = "xxx@qq.com" def send_mail(self,user_list,sub,content): user = "shape" + "<" + send_user + ">" # 创建一个带附件的实例 message = MIMEMultipart() message['Subject'] = sub message['From'] = user message['To'] = ";".join(user_list) # 邮件正文内容 message.attach(MIMEText(content, 'plain', 'utf-8')) # 构造附件(附件为txt格式的文本) filename = '../log/log.txt' time = datetime.date.today() att = MIMEText(open(filename, 'rb').read(), 'base64', 'utf-8') att["Content-Type"] = 'application/octet-stream' att["Content-Disposition"] = 'attachment; filename="%s_Log.txt"'% time message.attach(att) server = smtplib.SMTP_SSL() server.connect(email_host,465)# 启用SSL发信, 端口一般是465 # server.set_debuglevel(1)# 打印出和SMTP服务器交互的所有信息 server.login(send_user,password) server.sendmail(user,user_list,message.as_string()) server.close() def send_main(self,pass_list,fail_list,no_run_list): pass_num = len(pass_list) fail_num = len(fail_list) #未执行的用例 no_run_num = len(no_run_list) count_num = pass_num + fail_num + no_run_num #成功率、失败率 ''' 用%对字符串进行格式化 %d 格式化整数 %f 格式化小数;想保留两位小数,需要在f前面加上条件:%.2f;用%%来表示一个% 如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串 ''' pass_result = "%.2f%%" % (pass_num/count_num*100) fail_result = "%.2f%%" % (fail_num/count_num*100) no_run_result = "%.2f%%" % (no_run_num/count_num*100) user_list = ['xxx@qq.com'] sub = "接口自动化测试报告" content = "接口自动化测试结果: 通过个数%s个,失败个数%s个,未执行个数%s个:通过率为%s,失败率为%s,未执行率为%s 日志见附件" % (pass_num,fail_num,no_run_num,pass_result,fail_result,no_run_result) self.send_mail(user_list,sub,content)
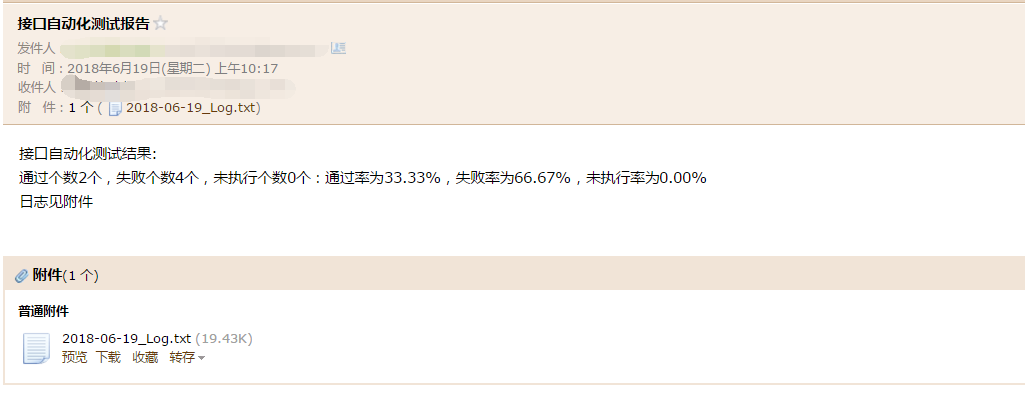
到此,就基本完成。
说明:
1.只是大概整理了接口自动化实现的设计流程,需要源码参考的可查看:https://github.com/zhangying123456/python3_interface
2.这套接口框架中还有很多需要完善的地方,比如断言方法不够丰富,比如测试报告展示需要完善,等等。各位有兴趣的可以不断完善改进