Hive基础
看了好多文章,还是觉得这个up写的我个人好理解点
Hive 简介
什么是Hive
1、Hive 由 Facebook 实现并开源
2、是基于 Hadoop 的一个数据仓库工具
3、可以将结构化的数据映射为一张数据库表
4、并提供 HQL(Hive SQL)查询功能
5、底层数据是存储在 HDFS 上
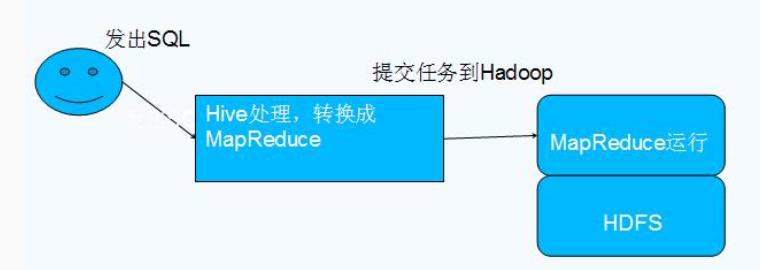
6、Hive的本质是将 SQL 语句转换为 MapReduce 任务运行
7、使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
数据仓库之父比尔·恩门(Bill Inmon)在 1991 年出版的“Building the Data Warehouse”(《建 立数据仓库》)一书中所提出的定义被广泛接受——数据仓库(Data Warehouse)是一个面 向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史 变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行,所以说 Hive 是基于 Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理
为什么使用 Hive
直接使用 MapReduce 所面临的问题:
1、人员学习成本太高
2、项目周期要求太短
3、MapReduce实现复杂查询逻辑开发难度太大
为什么要使用 Hive:
1、更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
2、更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
3、更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
Hive 特点
优点:
1、可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模 纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
2、延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
缺点:
1、Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
2、Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中。
3、Hive 不支持事务(因为不没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
Hive 和 RDBMS 的对比
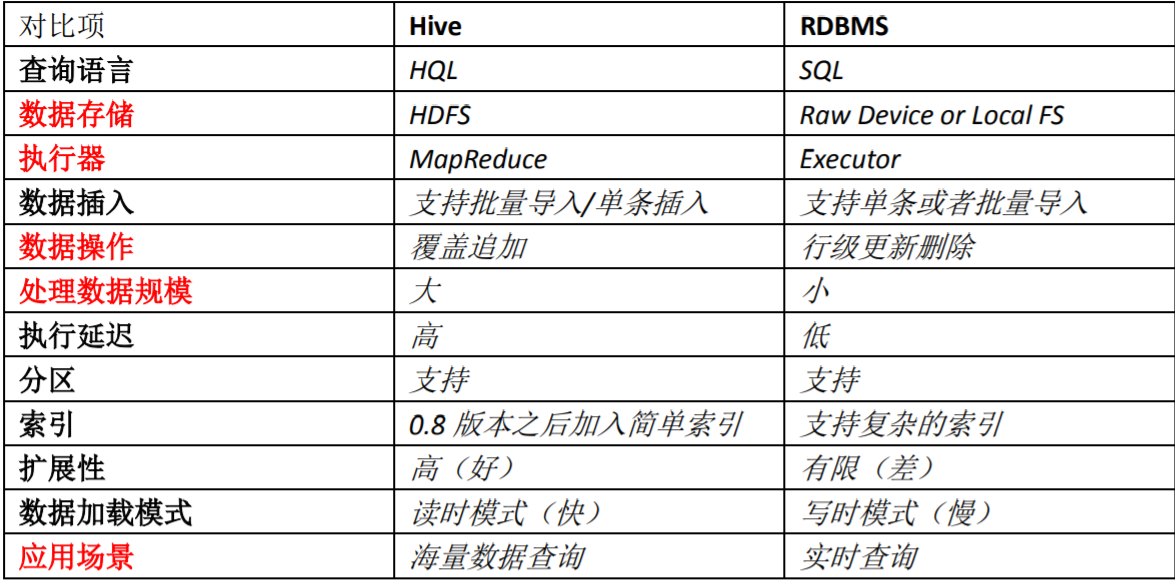
总结:
Hive 具有 SQL 数据库的外表,但应用场景完全不同,Hive 只适合用来做海量离线数 据统计分析,也就是数据仓库。
Hive的架构
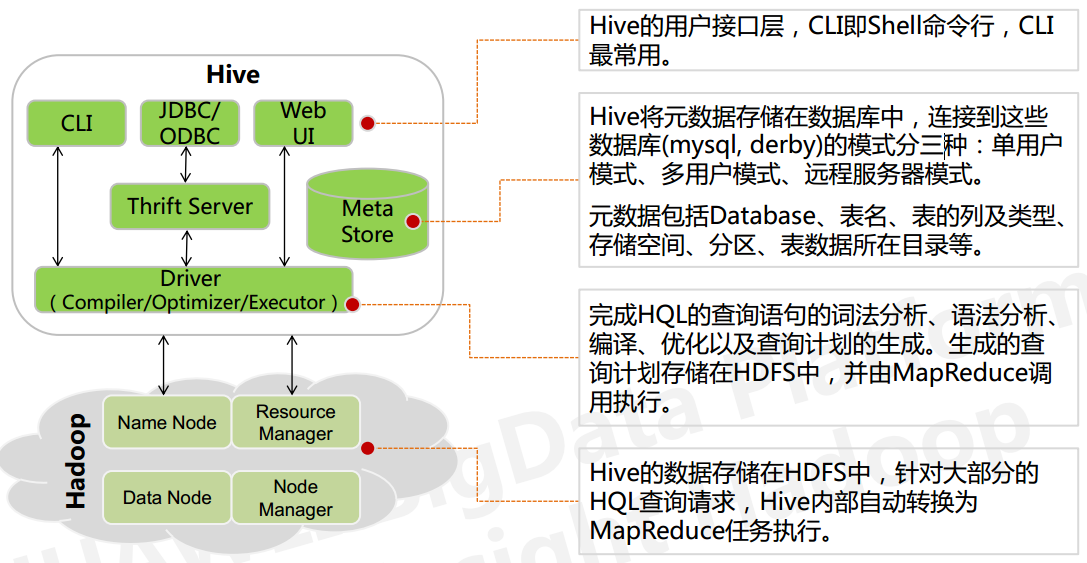
从上图看出hive的内部架构由四部分组成:
1、用户接口: shell/CLI, jdbc/odbc, webui Command Line Interface
CLI,Shell 终端命令行(Command Line Interface),采用交互形式使用 Hive 命令行与 Hive 进行交互,最常用(学习,调试,生产)
JDBC/ODBC,是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过 这连接至 Hive server 服务
Web UI,通过浏览器访问 Hive
2、跨语言服务 : thrift server 提供了一种能力,让用户可以使用多种不同的语言来操纵hive
Thrift 是 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务的开发, Hive 集成了该服务,能让不同的编程语言调用 Hive 的接口
3、底层的Driver: 驱动器Driver,编译器Compiler,优化器Optimizer,执行器Executor
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行 计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
(1) 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
(2) 编译器:编译器是将语法树编译为逻辑执行计划
(3) 优化器:优化器是对逻辑执行计划进行优化
(4) 执行器:执行器是调用底层的运行框架执行逻辑执行计划
4、元数据存储系统 : RDBMS MySQL
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。
Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表的数据所在目录
Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存 储目录不固定。数据库跟着 Hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程)
Hive 和 MySQL 之间通过 MetaStore 服务交互
Hive的架构
–(1)用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
–(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
–(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
–(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
执行流程
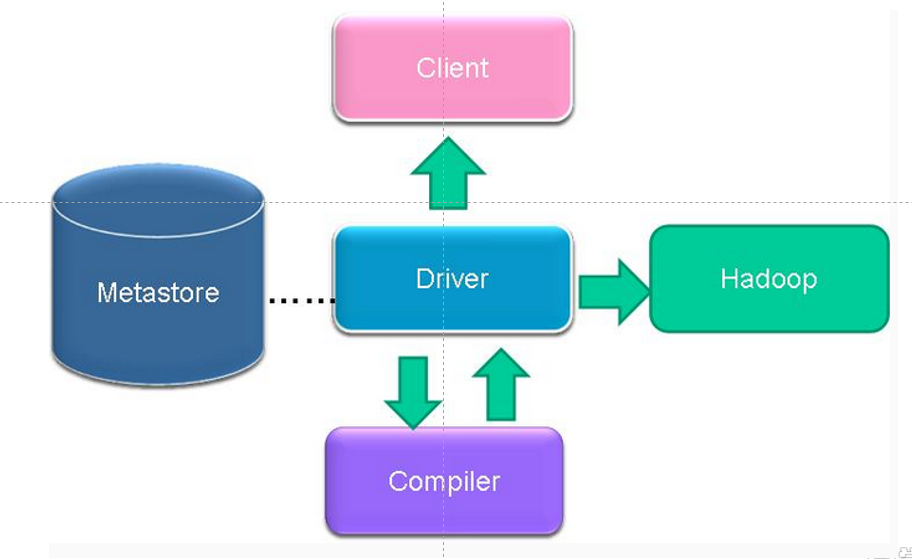
HiveQL 通过命令行或者客户端提交,经过 Compiler 编译器,运用 MetaStore 中的元数 据进行类型检测和语法分析,生成一个逻辑方案(Logical Plan),然后通过的优化处理,产生 一个 MapReduce 任务。
Hive的数据组织
1、Hive 的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对 应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。
2、Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 Hive 是读模式 (Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义格式等
3、 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
Hive 的默认列分隔符:控制符 Ctrl + A,x01 Hive 的
Hive 的默认行分隔符:换行符
4、Hive 中包含以下数据模型:
database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在 HDFS 中表现所属 database 目录下一个文件夹
external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
partition:在 HDFS 中表现为 table 目录下的子目录
bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散 列之后的多个文件
view:与传统数据库类似,只读,基于基本表创建
5、Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情 况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的 测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
6、Hive 中的表分为内部表、外部表、分区表和 Bucket 表
内部表和外部表的区别:
删除内部表,删除表元数据和数据
删除外部表,删除元数据,不删除数据
内部表和外部表的使用选择:
大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于 选择内部表,但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中
使用外部表的场景是针对一个数据集有多个不同的 Schema
通过外部表和内部表的区别和使用选择的对比可以看出来,hive 其实仅仅只是对存储在 HDFS 上的数据提供了一种新的抽象。而不是管理存储在 HDFS 上的数据。所以不管创建内部 表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。
分区表和分桶表的区别:
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同 时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的 HashPartitioner 的原理类似。
分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所 以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列 形成的多个文件,所以数据的准确性也高很多