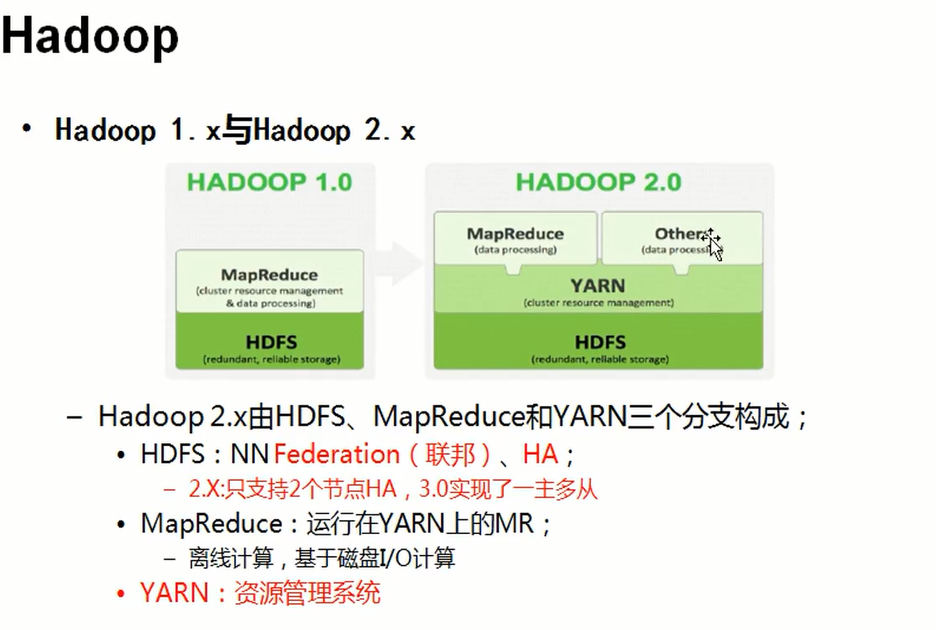
Hadoop版本
-
1、Hadoop1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题?
-
2、HDFS存在的问题
- NameNode单点故障,难于应用于在线场景 HA 【high availability 高可用】
- NameNode压力过大,且内存受限,影响扩展性 F【Federation联邦】
-
MapReduce存在的问题:响系统
- jobTracker访问压力大。影响系统扩展性
- 难于支持除MapReduce之外的计算框架,比如Spark、Storm等
2.0
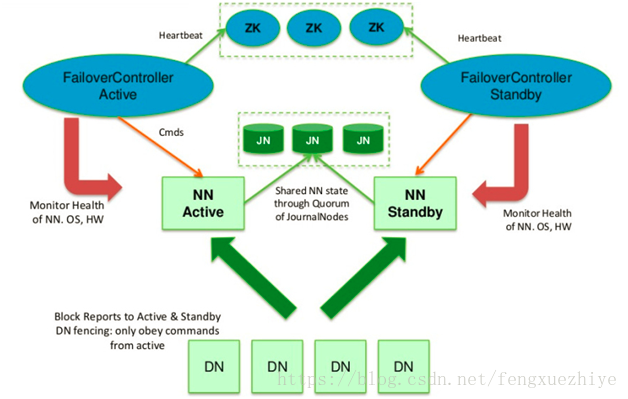
hadoop HA
hadoop HA是通过配置两个namenode来解决单点故障问题。两个namenode分别是active namenode和standby namenode,standby作为热备份,从而在主namenode发生故障是迅速进行故障转移,两个namenode只能一主一辅
通过使用journal node完成两个namenode的元数据同步,通过使用zookeeper完成namenode的故障转移(自动)
-
1.共享存储(shared edits)
active namenode处理所有的操作请求(读写),standby namenode只同步状态
datanode会同时向两个namenode发送block报告和心跳
当满足一次checkpoint时,standby namenode进行一次合并操作
active NN执行任何命名空间的修改都会持久化到一半以上的journalnodes上
而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间
一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态
一次checkpoint过程
(1)、配置好HA后,客户端所有的更新操作将会写到JournalNodes节点的共享目录中
(2)、Active Namenode和Standby NameNode从JournalNodes的edits共享目录中同步edits到自己edits目录中;
(3)、Standby NameNode中的StandbyCheckpointer类会定期的检查合并的条件是否成立,如果成立会合并fsimage和edits文件;
(4)、Standby NameNode中的StandbyCheckpointer类合并完之后,将合并之后的fsimage上传到Active NameNode相应目录中;
(5)、Active NameNode接到最新的fsimage文件之后,将旧的fsimage和edits文件清理掉;
(6)、通过上面的几步,fsimage和edits文件就完成了合并,由于HA机制,会使得Standby NameNode和Active NameNode都拥有最新的fsimage和edits文件
(之前Hadoop 1.x的SecondaryNameNode中的fsimage和edits不是最新的) -
2.如何防止namenode脑裂(两个namenode都处于active状态)
Journal Node通过epoch数来解决脑裂的问题,称为JournalNode fencing。具体工作原理如下:
1)当Namenode变成Active状态时,被分配一个整型的epoch数,这个epoch数是独一无二的,并且比之前所有Namenode持有的epoch number都高。
2)当Namenode向Journal Node发送消息的时候,同时也带上了epoch。当Journal Node收到消息时,将收到的epoch数与存储在本地的promised epoch比较,
如果收到的epoch比自己的大,则使用收到的epoch更新自己本地的epoch数。如果收到的比本地的epoch小,则拒绝请求。
3)edit log必须写入大部分节点才算成功,也就是其epoch要比大多数节点的epoch高。 -
3.namenode如何通过zookeeper进行自动故障转移
失败检测:每个namenode都会在zookeeper中获取一个持久性session,如果namenode故障,则session过期,使用zk的事件机制通知其他namenode需要故障转移
namenode选举:如果当前active namenode挂了,standby namenode会尝试从ZK获取一个排他锁,获取这个锁就代表他称为下一个activenamenode
而在故障自动转移的处理上,引入了监控Namenode状态的ZookeeperFailController(ZKFC)。
ZKFC一般运行在Namenode的宿主机器上,与Zookeeper集群协作完成故障的自动转移
【引用 https://blog.csdn.net/fengxuezhiye/article/details/80525098 】

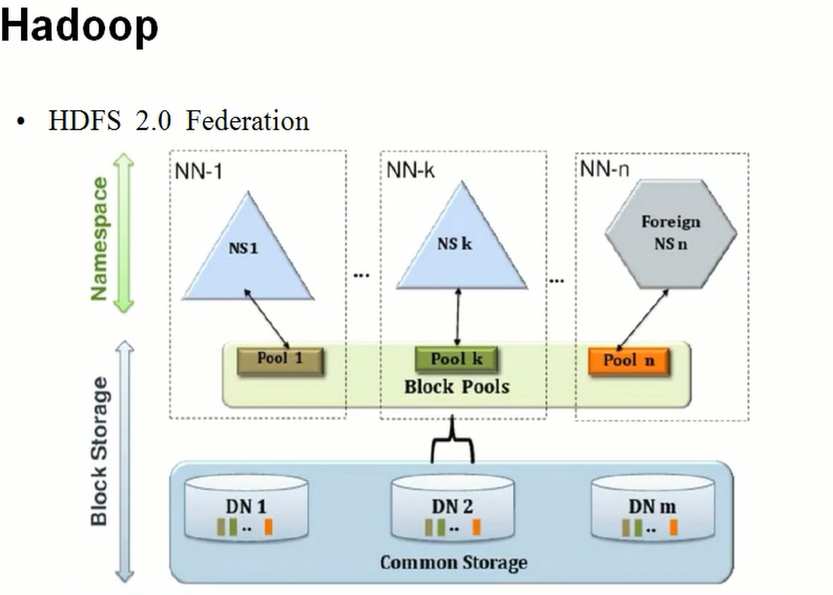
Hadoop的HDFS2.x Federation【联邦制】
-
通过多个NameNode/namespace把数据的存储和管理分散多个节点中,使到NameNodeSpace可以通过增加集群数量的方式来水平扩展。
-
把单个nameNode的负载均衡分散到多个节点上面,在HDFS数据规模过大的时候不会降低HDFS的性能,
可以通过多个NameSpace来隔离不同类型中的应用,把不同类型应用类型应用DHFS元数据的存储管理分派到不同的namenode中。
实验
| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | |
|---|---|---|---|---|---|---|
| Node1 | * | * | * | |||
| Node2 | * | * | * | * | * | |
| Node3 | * | * | * | |||
| Node4 | * | * |
ZK: zookeeper
ZKFC: failover controller【故障转移进程】