1、背景介绍
Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案。除了此套解决方案之外,还有一种非常流行的而且完整的离线和
实时数据处理方案。这种方案就是Spark。Spark本质上是对Hadoop特别是MapReduce的补充、优化和完善,尤其是数据处理速度、易用性、迭代计算和复杂数据分析等方面。
Spark Streaming 作为Spark整体解决方案中实时数据处理部分,本质上仍然是基于Spark的弹性分布式数据集(Resilient Distributed Datasets :RDD)概念。Spark Streaming将源头
数据划分为很小的批,并以类似于离线批的方式来处理这部分微批数据。
相对于Storm这种原生的实时处理框架,Spark Streaming基于微批的的方案带来了吞吐量的提升,但是也导致了数据处理延迟的增加---基于Spark Streaming实时数据处理方案的数据
延迟通常在秒级甚至分钟级。
2、Spark生态和核心概念
2.1、Spark概览
Spark诞生于美国伯克利大学的AMPLab,它最初属于伯克利大学的研究性项目,与2010年正式开源,于2013年成为Apache基金项目,冰雨2014年成为Apache基金的顶级项目。
Spark用了不到5年的时间就成了Apache的顶级项目,目前已被国内外的众多互联网公司使用,包括Amazon、EBay、淘宝、腾讯等。
Spark的流行和它解决了Hadoop的很多不足密不可分。
传统Hadoop基于MapReduce的方案适用于大多数的离线批处理场景,但是对于实时查询、迭代计算等场景非常不适合,这是有其内在局限决定的。
1、MapReduce只提供Map和Reduce两个操作,抽象程度低,但是复杂的计算通常需要很多操作,而且操作之间有复杂的依赖关系。
2、MapReduce的中间处理结果是放在HDFS文件系统中的,每次的落地和读取都消耗大量的时间和资源。
3、当然,MapReduce也不支持高级数据处理API、DAG(有向五环图)计算、迭代计算等。
Spark则较好地解决了上述这些问题。
1、Spark通过引入弹性分布式数据集(Resilient Distributed Datasets:RDD)以及RDD丰富的动作操作API,非常好地支持了DGA的计算和迭代计算。
2、Spark通过内存计算和缓存数据非常好地支持了迭代计算和DAG计算的数据共享、减少了数据读取的IO开销、大大提高了数据处理速度。
3、Spark为批处理(Spark Core)、流式处理(Spark Streaming)、交互分析(Spark SQL)、机器学习(MLLib)和图计算(GraphX)提供了一个同一的平台和API,非常便于使用。
4、Spark非常容易使用、Spark支持java、Python和Scala的API,还支持超过80种高级算法,使得用户可以快速构建不同的应用。Spark支持交互式的Python和Scala的shell,这意味着
可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法,而不是像以前一样,需要打包、上传集群、验证等。这对于原型开发尤其重要。
5、Spark可以非常方便地与其他开源产品进行融合:比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、
HBase和Cassandra等。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛。
6、External Data Source多数据源支持:Spark可以独立运行,除了可以运行在当下的Yarn集群管理之外,它还可以读取已有的Hadoop数据。它可以运行多种数据源,比如Parquet、Hive、
HBase、HDFS等。
2.2、Spark核心概念
RDD是Spark中最为核心和重要的概念。RDD,全称为 Resilient Distributed Dataset,在Spark官方文档中被称为“一个可并行操作的有容错机制的数据集合”。实际上RDD就是
一个数据集,而且是分布式的。同时Spark还对这个分布式数据集提供了丰富的数据操作和容错性。
1、RDD创建
Spark中创建RDD最直接的方法是调用SparkContext(SparkContext是Spark集群环境的访问入口,Spark Streaming也有自己对应的对象StreamContext)的parallelize方法。
List<Integer> data = Arrays.asList(1,2,3,4,5);
HavaRDD<Integer> distData = sc.parallelize(data);
上述代码会将数据集合 (data)转换为这个分布式数据集(distData),之后就可以对此RDD执行各种转换等。比如调用distData.reduce((a,b) => a+b),将这个数组中的元素项加,
此外,还可以通过设置parallelize的第二个参数手动设置生成RDD的分区数:sc.parallelize(data,10),如果不设定的话,Spark会自动设定。
但在实际的项目中,RDD一般是从源头数据创建的。Spark支持从任何一个Hadoop支持的存储数据创建RDD,包括本地文件系统、HDFS、Cassandna、HBase和Amazon S3等。
另外,Spark也支持从文本文件,SequenceFiles和其它Hadoop InputFormat的格式文件中创建RDD。创建的方法也很简单,只需要指定源头文件并调用对应的方法即可:
JavaRDD<String> distFile = sc.textFile("data.txt");
Spark 中转换SequenceFile的SparkContext方法是sequenceFile,转换Hadoop InputFormats的SparkContext方法是HadoopRDD。
2、RDD操作
RDD操作分为转换(transformation)和行动(action),transformation是根据原有的RDD创建一个新的RDD,action则吧RDD操作后的结果返回给driver。例如map 是一个转换,
它把数据集中的每个元素经过一个方法处理的结果返回一个新的RDD,reduce是一个action,它收集RDD的所有数据经过一些方法的处理,最后把结果返回给driver。
Spark对transformation的抽象可以大大提高性能,这是因为在Spark中,所有transformation操作都是lazy模式,即Spark不会立即计算结果,而只是简单地记住所有对数据集的
转换操作逻。这些转换只有遇到action操作的时候才会开始计算。这样的设计使得Spark更加高效,例如可以通过map创建一个新数据集在reduce中使用,并仅仅返回reduce的
结果给driver,而不是整个大大的map过的数据集。
3、RDD持久化
Spark最重要的一个功能是它可以通过各种操作持久化(或缓存)一个集合到内存中。当持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,
并且这些数据可以被这个集合(以及这个集合衍生的其他集合)的动作重复利用。这个能力使后续的动作速度更快(通常快10倍以上)。对应迭代算法和快速的交互应用来说,
缓存是一个关键的工具。
可以通过 persist()或者cache()方法持久化一个RDD。先在action中计算得到RDD,然后将其保存在每个节点的内存中。Spark的缓存是一个容错的技术,也就是说,如果RDD的
任何一个分区丢失,它可以通过原有的转换操作自动重复计算并且创建出这个分区。
此外,还可以利用不同的存储级别存储每一个被持久化的RDD,。例如,它允许持久化集合到磁盘上、将集合作为序列化的Java对象持久化到内存中、在节点间复制集合或存储集合
到Tachyon中。可以通过传递一个StorageLevel对象给persist()方式设置这些存储级别。cache()使用了默认的存储级别-----StorageLevel.MEMORY_ONLY。
4、Spark生态圈
Spark建立在统一抽象的RDD之上,使得它可以以基本一致的方式应对不同的大数据处理场景,包括批处理,流处理、SQL、Machine Learning以及GraphX等。这就是Spark设计的“
通用的编程抽象”( Unified Programming Abstraction),也正是Spark独特的地方。
Spark生态圈包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,其中Spark Core提供内存计算框架、SparkStreaming提供实时处理应用、Spark SQL提供
即席查询,再加上MLlib的机器学习和GraphX的图处理,它们能无缝集成并提供Spark一站式的大数据解决平台和生态圈。
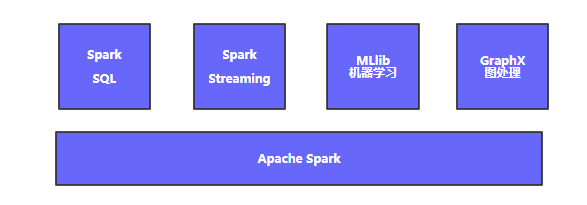
Spark Core:Spark Core实现了Spark的基本功能,包括任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core还包括了RDD的API定义,并提供了创建和操作RDD的
丰富API。Spark Core是Spark其它组件的基础和根本。
Spark Streaming:他是Spark提供的对实时数据进行流计算的组件,提供了用来操作数据流的API,并且与Spark Core中的RDD API高度对应。Spark Streaming支持与Spark Core
同级别的容错性、吞吐量和伸缩性。
Spark SQL:它是Spark用来操作结构化数据的程序包,通过Spark SQL,可以使用SQL或类SQL语言来查询数据;同时Spark SQL支持多种数据源,比如Hive表、Parquet以及
JSON等,除了为Spark提供一个SQL接口,Spark SQL还支持开发者将SQL和传统的RDD编程的数据操作方式向结合,不论是使用Python、Java还是Scala,开发者都可以在
单个应用中同时使用SQL和复杂的数据分析。
MLLib:Spark提供了常见的机器学习功能的程序库,叫做MLlib,MLlib提供了多种机器学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的
支持功能。此外,MLLib还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化算法,所有这些方法都被设计为可以在集群上轻松伸缩的架构。
GraphX:GraphX是用来操作图(如社交网络的朋友圈)的程序库,可以进行并行的图计算。与Spark Streaming和Spark SQL类似,GraphX也扩展了Spark的RDD API,
能用来创建一个顶点和边都包含任意属性的有向图。GraphX还支持针对图的各种操作(如进行图分割的subgraph和操作所有顶点的mapVertices),以及一些常用的图算法
(如PageRank和三角计算)。
3、Spark生态的流计算技术:Spark Streaming
Spark Streaming作为Spark的核心组件之一,通Storm一样,主要对数据进行实时的流处理,但是不同于Apache Storm(这里指的是原生Storm,非Trident),在Spark Streaming
中数据处理的单位是是一批而不是一条,Spark会等采集的源头数据累积到设置的间隔条件后,对数据进行统一的微批处理。这个间隔是Spark Streaming中的核心概念和关键参数,
直接决定了Spark Streaming作业的数据处理延迟,当然也决定着数据处理的吞吐量和性能。
相对于Storm的毫秒级延迟来说,Spark Streaming的延迟最多只能到几百毫秒,一般是秒级甚至分钟级,因此对于实时数据处理延迟要非常高的场合,Spark Streaming并不合适。
另外,Spark Streaming底层依赖于Spark Core 的RDD实现,即它和Spark框架整体是绑定在一起的,这是优点也是缺点。
对于已经采用Spark 作为大数据处理框架,同时对数据延迟性要求不是很高的场合,Spark Streaming非常适合作为事实流处理的工具和方案,原因如下:
1、Spark Streaming内部的实现和调度方式高度依赖于Spark的DAG调度器和RDD,Spark Streaming的离散流(DStream)本质上是RDD在流式数据上的抽象,因此熟悉Spark和
和RDD概念的用户非常容易理解Spark Streaming已经其DSream。
2、Spark上各个组件编程模型都是类似的,所以如果熟悉Spark的API,那么对Spark Streaming的API也非常容易上手和掌握。
但是,如果已经采用了其他诸如Hadoop和Storm的数据处理方案,那么如果使用Spark Streaming,则面临着Spark以及Spark Streaming的概念及原理的学习成本。
总体来说,Spark Streaming作为Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、和可以容错性等特点。
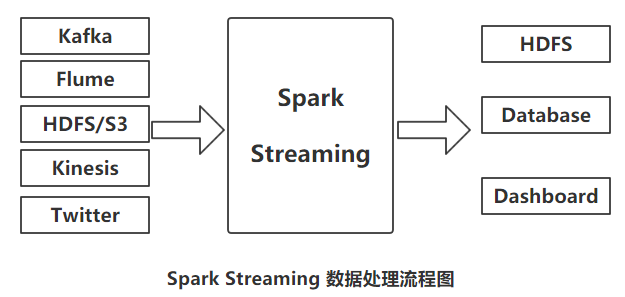
同其他流处理框架一样,Spark Streaming从Kafka、Flume、Twitter、ZeroMQ、Kinesis等源头获取数据,并map、reduce、join、window等组成的复杂算法计算出期望的结果,处理
后的结果数据可被推送到文件系统,数据库、实时仪表盘中,当然,也可以将处理后的数据应用到Spark的机器学习算法、图处理算法中。整个的数据处理流程如下:
3.1、Spark Streaming基本原理
Spark Streaming 中基本的抽象是离散流(即DStream).DStream代表一个连续的数据流。在Spark Streaming内部中,DStream实际上是由一系列连续RDD组成。每个RDD包含确定
时间间隔内的数据,这些离散的RDD连在一起,共同组成了对应的DStream。
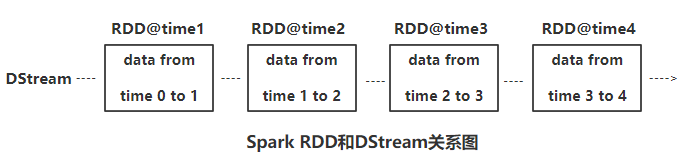
实际上任何,任何对DStream的操作都转换成了对DStream隐含的一系列对应RDD的操作,如上图中对lines DStream是的flatMap操作,实际上应用于lines对应每个RDD的操作,并生成了
对应的work DStream的RDD。
也就是上面所说的,Spark Streaming底层依赖于Spark Core的RDD实现。从本质上来说,Spark Streaming只不过是将流式的数据流根据设定的间隔分成了一系列的RDD,然后在每个RDD上
应用相应的各种操作和协作,所以Spark Streaming底层的运行引擎实际上是Spark Core。
3.2、Spark Streaming核心API
SparkStreaming完整的API包括StreamingContext、DStream输入、DStream上的各种操作和动作、DStream输出等。
1、StreamingContext
为了初始化Spark Streaming程序,必须创建一个StreamingContext对象,该对象是Spark Streaming所有流操作的主要入口。一个StreamingContext对象可以用SparkConf对象创建:
import org.apache.spark.*;
import org.apache.spark.streaming.api.Java.*;
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaStreamingContext ssc = new JavaStreamingContext(conf, new Duration(1000));
2、DStream输入
DStream输入表示从数据源获取的原始数据流。每个输入流DStream和一个接收器(receiver)对象相关联,这个Receiver从源中获取数据,并将数据存入内存中用于处理。
Spark Streaming有两类数据源:
基本源(basic source):在StreamingContext API中直接可用的源头,例如文件系统、套接字连接、Akka的actor等。
高级源(advanced source):包括 Kafka、Flume、Kinesis、Tiwtter等,他们需要通过额外的类来使用。
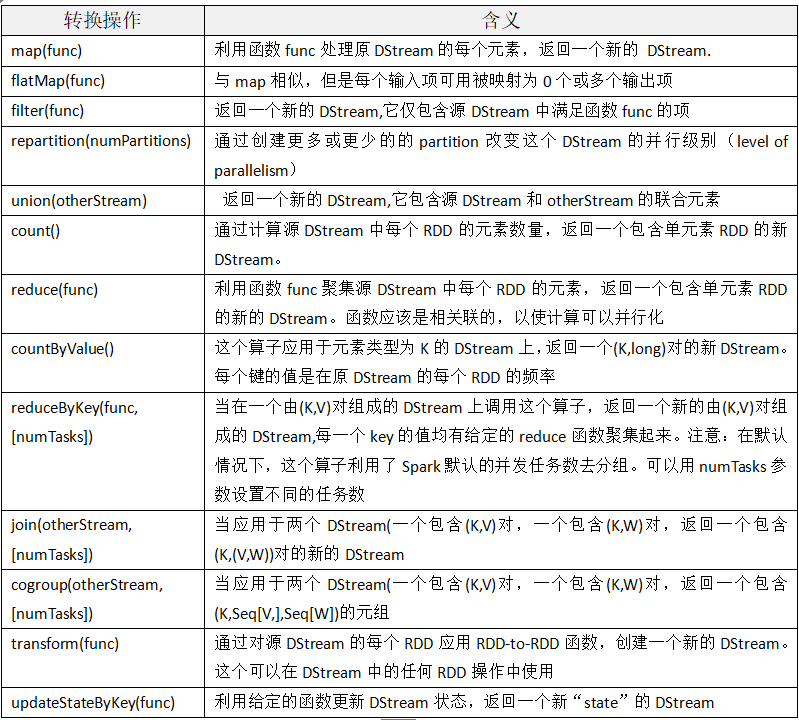
3、DStream的转换
和RDD类似,transformation用来对输入DStreams的数据进行转换、修改等各种操作,当然,DStream也支持很多在Spark RDD的transformation算子。
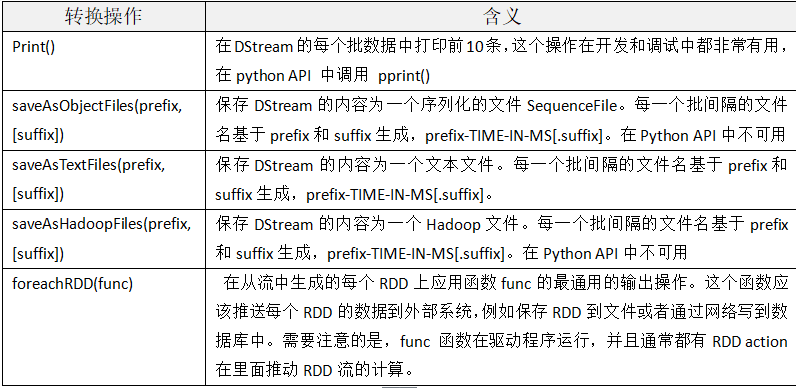
4、DStream的输出
和RDD类似,Spark Streaming允许将DStream转换后的结果发送到数据库、文件系统等外部系统中。目前,定义了Spark Streaming的输出操作:
4、Spark Streaming实时开发实例
下面用字符计数这个例子来说明 Spark Streming
首先,导入 Spark Streaming的相关类到环境中,这些类(如DStream)提供了流操作很多有用的方法,StreamingContext是Spark所有流操作的主要入口。
其次,创建一个具有两个执行线程以及1秒批间隔时间(即以秒为单位分隔数据流)的本地StreamingContext.
import org.apache.spark.{*, SparkConf} import org.apache.spark.api.java.function.* import org.apache.spark.streaming.{*, Duration, Durations} import org.apache.spark.streaming.api.java.{*, JavaDStream, JavaStreamingContext} import scala.Tuple2; object streaming_test { def main(args: Array[String]): Unit = { //创建一个本地的StreamingContext上下文对象,该对象包含两个工作线程,批处理间隔为1秒 val conf = new SparkConf().setMaster("local[2]").setAppName("Network-WordCount"); val jssc = new JavaStreamingContext(conf,Durations.seconds(1)); //利用这个上下文,能够创建一个DStream,它表示从TCP源(主机为localhost,端口为9999)获取的流式数据 //创建一个连接到hostname:port的DStream对象,类似localhost:9999 val lines =jssc.socketTextStream("localhost",9999); //这个lines变量是一个DStream,表示即将从数据服务器或的数据流,这个DStream的每条记录都代表一行文本, // 接下来需要将DStream中的每行文本都切分为单词 val words =lines.flatMap(x:String => util.Arrays.asList(x.split(" ")).iterator()); val pairs =words.mapToPair<s=>new Tuple2<>(s,1)); val wordCounts =pairs.reduceByKey((i1,i2)=> i1+i2); wordCounts.print(); } }
4、Spark Streaming调优实践
Spark Streaming作业的调优通常都涉及作业开发的优化、并行度的优化和批大小以及内存等资源的优化。
1、作业开发优化
RDD复用:对于实时作业,尤其是链路较长的作业,要尽量重复使用RDD,而不是重复创建多个RDD。另外需要多次使用的中间RDD,可以将其持久化,以降低每次都需要重复计算的开销。
使用效率较高的shuffle算子:如同Hadoop中的作业一样,实时作业的shuffle操作会涉及数据重新分布,因此会耗费大量的内存、网络和计算等资源,需要尽量降低需要shuffle的数据量,
reduceByKey/aggregateByKey相比groupByKey,会在map端先进行预聚合,因此效率较高。
类似于Hive的MapJoin:对于实时作业,join也会涉及数据的重新分布,因此如果是大数据量的RDD和小数据量的RDD进行join,可以通过broadcast与map操作实现类似于Hive的MapJoin,
但是需要注意小数量的RDD不能过大,不然广播数据的开销也很大。
其它高效的例子:如使用mapPartitions替代普通map,使用foreachPartitions替代foreach,使用repartitionAndSortWithinPartitions替代repartition与 sort类操作等。
2、并行度和批大小
对于Spark Streaming这种基于微批处理和实时处理框架来说,其调优不外乎两点:
一是尽量缩短每一批次的处理时间
二是设置合适的batch size(即每批处理的数据量),使得数据处理的速度能够适配数据流入的速度。
第一点通常以设置源头、处理、输出的并发度来实现。
源头并发:如果源头的输入任务是实时作业的瓶颈,那么可以通过加大源头的并发度提供性能,来保证数据能够流入后续的处理链路。在Spark Streaming,可以通过如下代码来实现(
一Kafka源头为例):
int numStreams = 5;
List<JavaPairDStream<String,String>> kafkaStreams = new ArrayList<JavaPairDStream<String,String>>(numStreams );
for(int i=0;i<numStreams ;i++){
kafkaStreams.add(KafkaUtils.createStream(...));
}
JavaPairDStream<String,String> unifiedStream = streamingContext.union( kafkaStreams.get(0), kafkaStreams.subList(1, kafkaStreams.size()));
处理并发:处理任务的并发决定了实际作业执行的物理视图。Spark Streaming作业的默认并发度可以通过spark.default.parllelism来设置,但是实际中不推荐,建议针对每个任务单独设置
并发度进行精细控制。
输出并发:如图Hadoop作业一样,实时作业的shuffle操作会涉及数据重新分布,因此会耗费大量的内存、网络和计算等资源,因此需要尽量减少shuffle操作。
batch size:batch size主要影响系统的吞吐量和延迟。batch size 太小,一般处理延迟会降低,但是系统吞吐量会下降;batch size太大,吞吐量上去了,但是处理延迟会提高,同时要求的
内存也会增加,因此实际中需要找到一个平衡点,既能满足吞吐量也能满足延迟的要求,那么实际中如何设置batch大小呢?
参考资料:《离线和实时大数据开发实战》