重点就是三个配置文件
1、建立的data-config.xml
内容如下:
<dataConfig> <dataSource name="fileDataSource" type="FileDataSource" /> <!--<document> <entity name="tika-test" processor="TikaEntityProcessor" url="C:/docs/solr-word.pdf" format="text"> <field column="Author" name="author" meta="true"/> <field column="title" name="title" meta="true"/> <field column="text" name="text"/> </entity> </document>--> <dataSource name="urlDataSource" type="BinURLDataSource" /> <!--baseDir="D:/work/Solr/solr-6.6.0/ImportDoc" fileName=".*.(doc)|(pdf)|(docx)|(txt)"--> <document> <entity name="files" dataSource="null" rootEntity="false" processor="FileListEntityProcessor" baseDir="D:/work/Solr/solr-6.6.0/ImportDoc" fileName=".*.(json)|(txt)|(csv)|(xml)" onError="skip" recursive="true"> <field column="file" name="id"/> <field column="fileAbsolutePath" name="filePath" /> <field column="fileSize" name="size" /> <field column="fileLastModified" name="lastModified" /> <entity processor="PlainTextEntityProcessor" name="txtfile" url="${files.fileAbsolutePath}" dataSource="fileDataSource"> <field column="plainText" name="text"/> </entity> </entity> </document> </dataConfig>
2、修改managed-schema文件
增加如下内容:
<!-- mmseg4j fieldType--> <fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" /> </analyzer> </fieldType> <fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" /> </analyzer> </fieldType> <fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" /> </analyzer> </fieldType> <field name="text" type="text_mmseg4j_complex" indexed="true" stored="true" omitNorms="true" multiValued="false"/> <field name="fileName" type="string" indexed="true" stored="true" /> <field name="filePath" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="size" type="long" indexed="true" stored="true" /> <field name="lastModified" type="date" indexed="true" stored="true" />
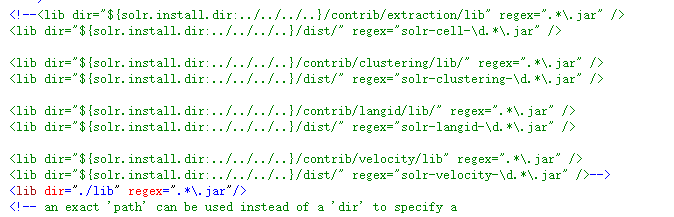
3、修改solrconfig.xml文件
<lib dir="./lib" regex=".*.jar"/>
4、导入文件
注意,txt文件编码请保证是UTF-8编码,默认txt文件的编码是GBK
5、查询
导入成功后,查询
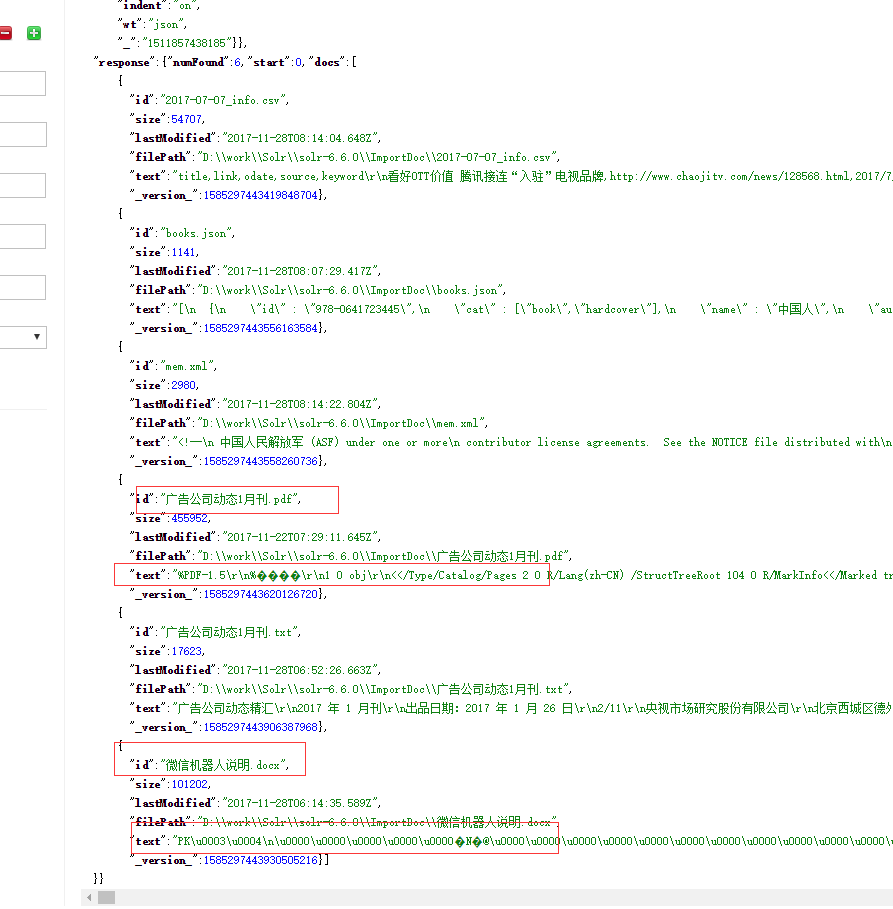
从上面可以看到,pdf和word文件是乱码,必须用其它Processor进行处理