1、前言
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个。比如说我们要查找年龄为39的所有文档
POST /bank/_search?pretty { "query": { "term": { "age": "39" } } }
结果:

另外再查询address=Avenue的文档,没有查到结果
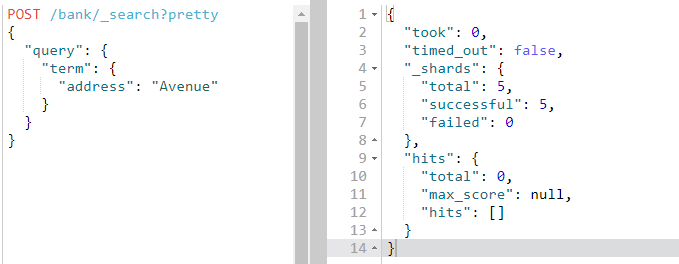
为什么?
字符串字段可以是文本类型(视为全文,如电子邮件正文)或关键字(视为精确值,如电子邮件地址或邮政编码)。精确值(如数字,日期和关键字)具有在添加到倒排索引的字段中指定的确切值,以使其可被搜索。
但是,分析文本字段。这意味着它们的值首先通过一个分析器产生一个项目列表,然后将其添加到倒排索引中。
分析文本的方法有很多种:默认的标准分析器会删除大部分的标点符号,将文本分解为单个的单词,并将其分解为小写字母。例如,标准分析仪会将字符串“Quick Brown Fox!”变成[quick,brown,fox]。
先看Avenue的分析

因为171 Putnam Avenue被分解为 171,putnam,avenue三个词,因此在Avenue时无法查询到,因为第一个字符是大写
下面做一个测试演示
首先,创建一个索引,指定字段映射,并索引一个文档
创建索引和索引数据
PUT my_index { "mappings": { "my_type": { "properties": { "full_text": { "type": "text" 1 }, "exact_value": { "type": "keyword" 2 } } } } } PUT my_index/my_type/1 { "full_text": "Quick Foxes!", 3 "exact_value": "Quick Foxes!" 4 }
1、full_text字段是文本类型,将被分析。
2、exact_value字段是关键字类型,不会被分析。
3、full_text倒排索引将包含术语:[quick,foxes]。
4、exact_value倒排索引将包含确切的术语:[Quick Foxes!]
现在,比较术语查询和匹配查询的结果:
GET my_index/my_type/_search { "query": { "term": { "exact_value": "Quick Foxes!" 1 } } } GET my_index/my_type/_search { "query": { "term": { "full_text": "Quick Foxes!" 2 } } } GET my_index/my_type/_search 3 { "query": { "term": { "full_text": "foxes" } } } GET my_index/my_type/_search 4 { "query": { "match": { "full_text": "Quick Foxes!" } } }
1、此查询匹配,因为exact_value字段包含确切的术语Quick Foxes !.
2、这个查询不匹配,因为full_text字段只包含quick和foxes这两个词。 它不包含确切的术语Quick Foxes !.
3、术语foxes的查询匹配full_text字段。
4、full_text字段上的匹配查询首先分析查询字符串,然后查找包含快速或狐狸或两者的文档。
再看看分析
GET /my_index/_analyze { "field": "exact_value", "text": "Quick Foxes!" } 结果: { "tokens": [ { "token": "Quick Foxes!", "start_offset": 0, "end_offset": 12, "type": "word", "position": 0 } ] }
GET /my_index/_analyze { "field": "full_text", "text": "Quick Foxes!" } 结果: { "tokens": [ { "token": "quick", "start_offset": 0, "end_offset": 5, "type": "<ALPHANUM>", "position": 0 }, { "token": "foxes", "start_offset": 6, "end_offset": 11, "type": "<ALPHANUM>", "position": 1 } ] }