一、介绍
本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息。
给定关键字:打通;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
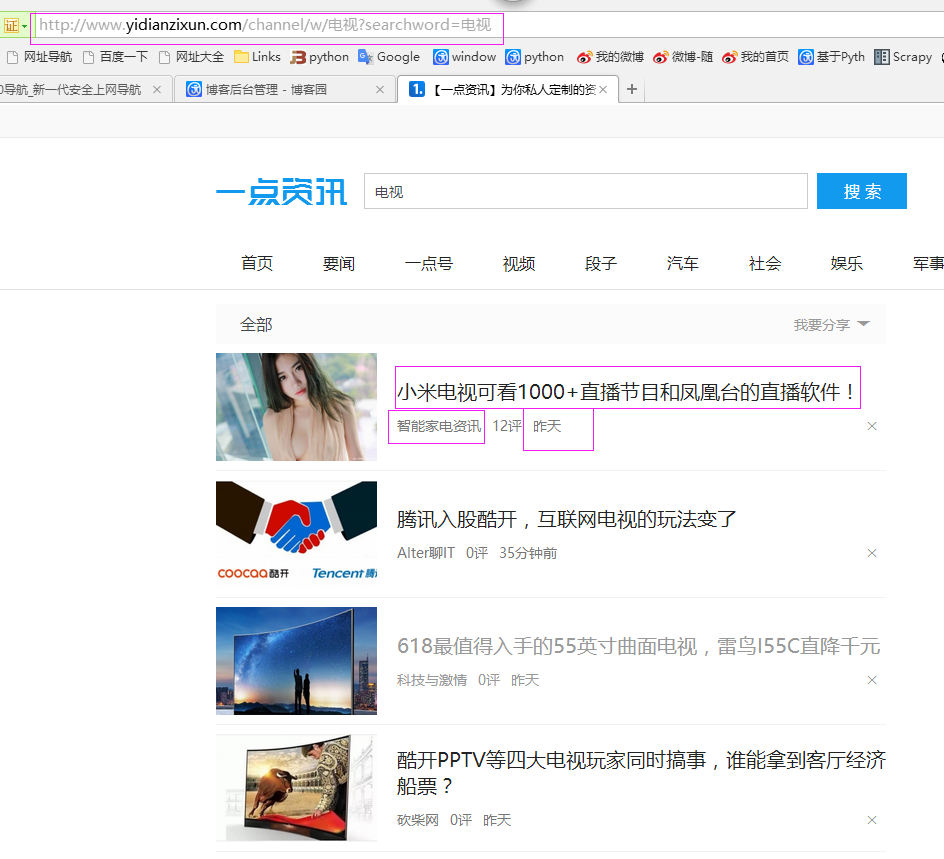
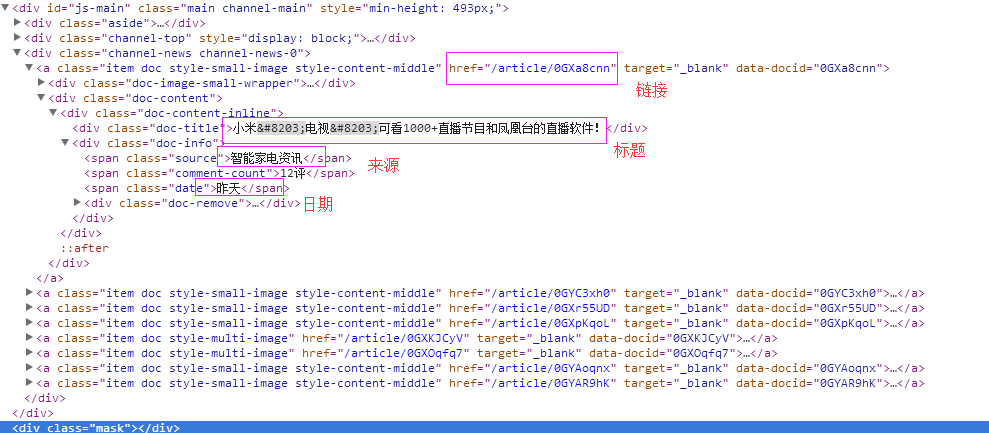

三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表,由于信息列表的class值有“item doc style-small-image style-content-middle” 和“item doc style-multi-image”两种情况,所以用contains包含item doc style-的语法来抓
抓取代码:sels = site.xpath('//a[contains(@class,"item doc style-")]')
2、抓取标题
抓取代码:titles = sel.xpath('.//div[@class="doc-title"]/text()')
3、抓取链接
抓取代码:it['url'] = 'http://www.yidianzixun.com' + sel.xpath('.//@href')[0].extract()
4、抓取日期
抓取代码:dates = sel.xpath('.//span[@class="date"]/text()')
5、抓取来源
抓取代码:it['source'] = sel.xpath('.//span[@class="source"]/text()')[0].extract()
四、完整代码
1、yidianzixunSpider
# -*- coding: utf-8 -*- import scrapy from scrapy import Request from scrapy.spiders import Spider from scrapy_splash import SplashRequest from scrapy_splash import SplashMiddleware from scrapy.http import Request, HtmlResponse from scrapy.selector import Selector from scrapy_splash import SplashRequest from splash_test.items import SplashTestItem import IniFile import sys import os import re import time reload(sys) sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class yidianzixunSpider(Spider): name = 'yidianzixun' start_urls = [ 'http://www.yidianzixun.com/channel/w/打通?searchword=打通', 'http://www.yidianzixun.com/channel/w/融合?searchword=融合', 'http://www.yidianzixun.com/channel/w/电视?searchword=电视' ] # request需要封装成SplashRequest def start_requests(self): for url in self.start_urls: print url index = url.rfind('=') yield SplashRequest(url , self.parse , args={'wait': '2'}, meta={'keyword': url[index + 1:]} ) def date_isValid(self, strDateText): ''' 判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内 :param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 ' :return: True:合法;False:不合法 ''' currentDate = time.strftime('%Y-%m-%d') if strDateText.find('分钟前') > 0 or strDateText.find('刚刚') > -1: return True, currentDate elif strDateText.find('小时前') > 0: datePattern = re.compile(r'd{1,2}') ch = int(time.strftime('%H')) # 当前小时数 strDate = re.findall(datePattern, strDateText) if len(strDate) == 1: if int(strDate[0]) <= ch: # 只有小于当前小时数,才认为是今天 return True, currentDate return False, '' def parse(self, response): site = Selector(response) keyword = response.meta['keyword'] it_list = [] sels = site.xpath('//a[contains(@class,"item doc style-")]') for sel in sels: dates = sel.xpath('.//span[@class="date"]/text()') if len(dates) > 0: flag, date = self.date_isValid(dates[0].extract()) if flag: titles = sel.xpath('.//div[@class="doc-title"]/text()') if len(titles) > 0: title = str(titles[0].extract()) if title.find(keyword) > -1: it = SplashTestItem() it['title'] = title it['url'] = 'http://www.yidianzixun.com' + sel.xpath('.//@href')[0].extract() it['date'] = date it['keyword'] = keyword it['source'] = sel.xpath('.//span[@class="source"]/text()')[0].extract() it_list.append(it) if len(it_list) > 0: return it_list
2、SplashTestItem
import scrapy class SplashTestItem(scrapy.Item): #标题 title = scrapy.Field() #日期 date = scrapy.Field() #链接 url = scrapy.Field() #关键字 keyword = scrapy.Field() #来源网站 source = scrapy.Field()
3、SplashTestPipeline
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import codecs import json class SplashTestPipeline(object): def __init__(self): # self.file = open('data.json', 'wb') self.file = codecs.open( 'spider.txt', 'w', encoding='utf-8') # self.file = codecs.open( # 'spider.json', 'w', encoding='utf-8') def process_item(self, item, spider): line = json.dumps(dict(item), ensure_ascii=False) + " " self.file.write(line) return item def spider_closed(self, spider): self.file.close()
4、settings.py
# -*- coding: utf-8 -*- # Scrapy settings for splash_test project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html ITEM_PIPELINES = { 'splash_test.pipelines.SplashTestPipeline':300 } BOT_NAME = 'splash_test' SPIDER_MODULES = ['splash_test.spiders'] NEWSPIDER_MODULE = 'splash_test.spiders' SPLASH_URL = 'http://192.168.99.100:8050' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'splash_test (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, } DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'splash_test.middlewares.SplashTestSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'splash_test.middlewares.MyCustomDownloaderMiddleware': 543, #} # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'splash_test.pipelines.SplashTestPipeline': 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'