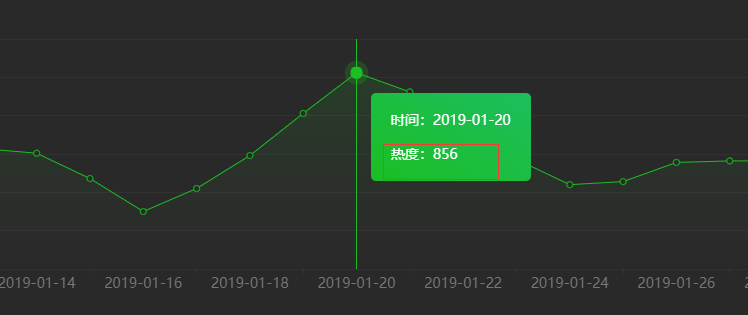
比如要抓取某网站折线图上数据,如下截图:
借助Chrome开发者工具Network。经过分析发现获取上面的热度数据,找到对应的事件url:https://pcw-api.iqiyi.com/video/video/trendcontent?ids=309006000&callback=jsonp_1548834448424_4474
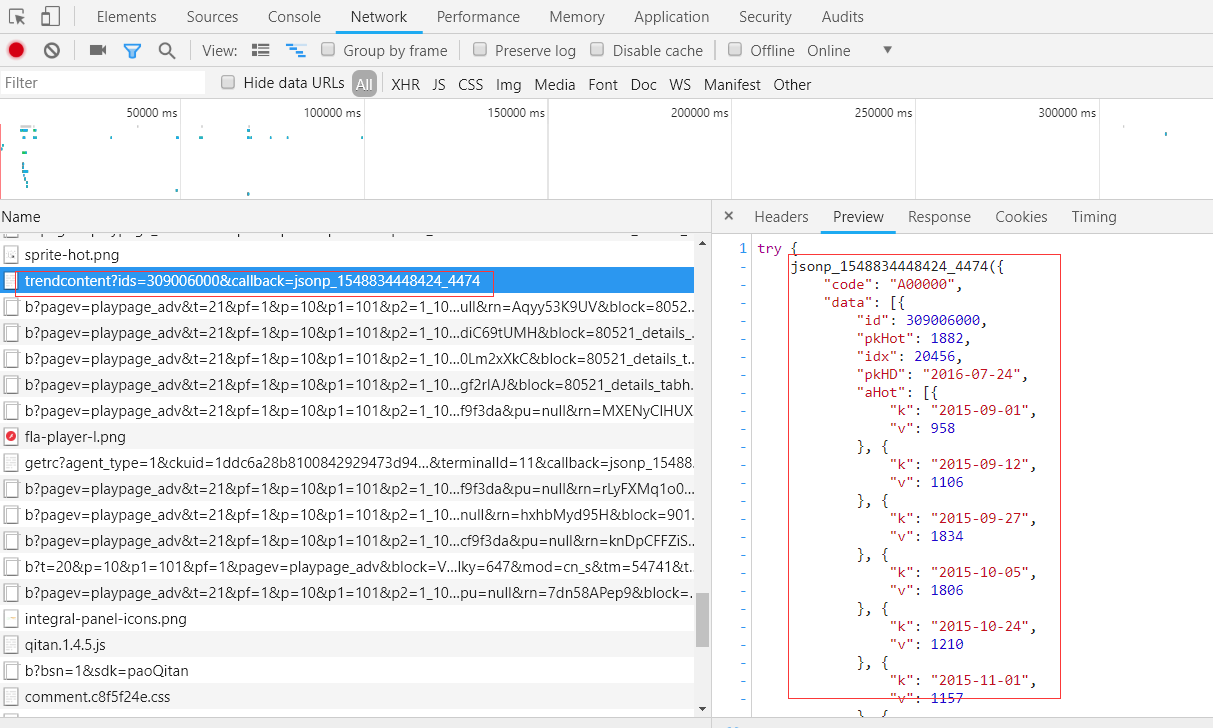
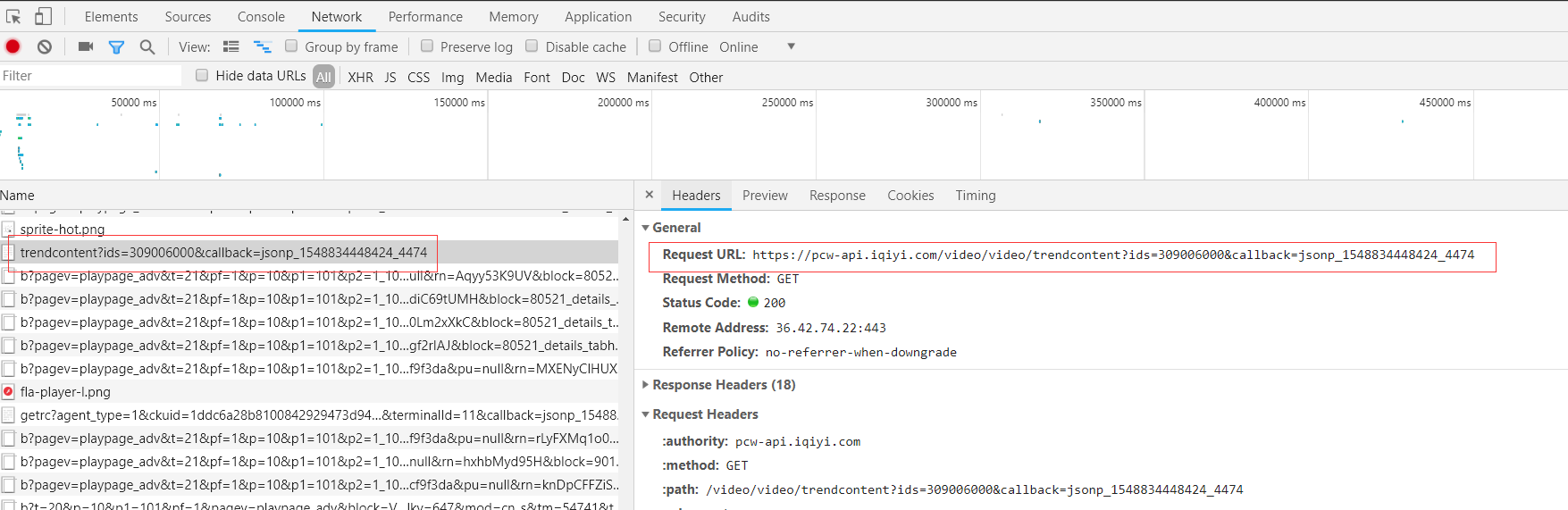
通过分析:https://pcw-api.iqiyi.com/video/video/trendcontent?ids=309006000&callback=jsonp_1548834448424_4474
发现,ids=309006000是个定值,1548834448424_4474是两个随机数
ids=309006000是个定值从网页中获取。
右键“查看网页源代码” 发现如下:
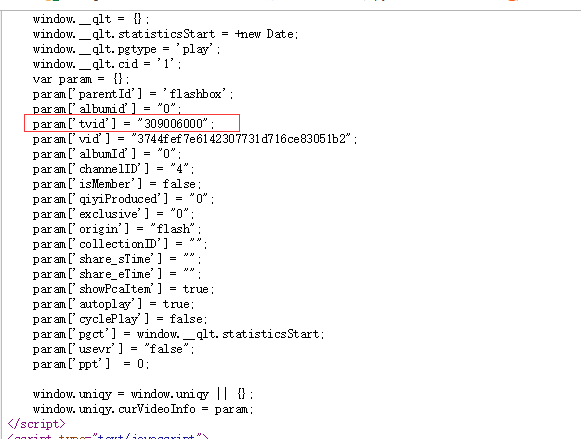
具体实现代码如下:
import random from urllib import request import requests import json class test: def __init__(self):
#插入合适的cookie值 self.mycookies = [] self.user_agent_list = [ 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36', 'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36', 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36', 'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36' ] def gettvid(self,url): tvid = '' try: cookie1 = random.choice(self.mycookies) # print(cookie1) UserAgent = random.choice(self.user_agent_list) header = {'User-Agent': UserAgent} # print(header) txt1 = requests.get(url, cookies=cookie1, headers=header).text print(txt1) response = request.urlopen(url) page = response.read() txt = str(page.decode('utf-8')) # cookie1 = random.choice(self.mycookies) # txt = requests.get(keyurl, cookies=cookie1).text txts = txt.split(' ') # print(txts) index = len(txts) - 1 while index > 0: t = txts[index] if t.find("param['tvid']") > -1: tt = t.replace('"', '').replace(' ', '') start = tt.find("=")+1 end = start+9 tvid = tt[start:end] tvid = tvid.strip() break index -= 1 except Exception as ex: print(ex) # print(ex) return tvid def gethotdx(self,url): tvid =self.gettvid(url) # 产生7位随机数 id1=random.randint(1111111,9999999) # 产生5为随机数 id2 = random.randint(11111, 99999) link ='https://pcw-api.iqiyi.com/video/video/trendcontent?ids=%s&callback=jsonp_154881%d_%d'%(tvid,id1,id2) try: cookie1 = random.choice(self.mycookies) # print(cookie1) UserAgent = random.choice(self.user_agent_list) header = {'User-Agent': UserAgent} # print(header) txt = requests.get(link, cookies=cookie1, headers=header).text start = txt.find('(') + 1 end = txt.find(")") jsonstr = txt[start:end] data_json = json.loads(jsonstr) datas = data_json.get('data')[0] # print(data_json.get('data')) id = datas.get('id') print(id) print(' ') # # # 热度峰值 pkHot = datas.get('pkHot') print(pkHot) print(' ') # # # 热度峰值 日期 pkHD = datas.get('pkHD') print(pkHD) print(' ') # # # 热度值 print('30天内容热度') aHot = datas.get('aHot') # print(aHot) for item in aHot: print(item.get('k'), item.get('v')) print(' ') print('全部内容热度') mHot = datas.get('mHot') # print(aHot) for item in mHot: print(item.get('k'), item.get('v')) print(' ') print('30天播放指数') aidx = datas.get('aidx') # print(aHot) for item in aidx: print(item.get('k'), item.get('v')) print(' ') print('全部播放指数') midx = datas.get('midx') # print(aHot) for item in midx: print(item.get('k'), item.get('v')) except Exception as e1: print(e1) if __name__=="__main__": obj =test() url='https://www.iqiyi.com/v_19rrnbwrfg.html?vfm=m_103_txsp' obj.gethotdx(url)