软件工程——第二次作业(2)
作业要求: https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
代码: https://git.coding.net/ss505072461/wf.git
————————————————————————————————————————————————————
项目要求是编写出一个拥有“词频统计”功能的小程序,作为一个小程序,若只是实现基本的词频统计功能,其实并不是很难。但是,如果再附加一些需求和功能的话就会让我感到有点难度了,更何况为了以后课程的要求,我选择使用Visual Studio 2015编译器和C#语言这两种从未学过的工具,在4-5天之内共10个小时左右(预计,但是实际上确实是花了更多时间……)的时间里一边学习C#语言一边去做一个小程序,并且尝试着完成更多的需求和功能,这对我来说是一次充满挑战的作业。
这次作业项目,我碰到的第一个难点就是我选择的C#语言是我从来未用过的语言,这考验着我的短期学习能力(毕竟需要做的作业是有时限的,当然这次作业之后学习还会继续的)和消化能力(理解参考书中的内容后运用出来),所以当我周四下课后就立刻开始查询C#语言的学习参考书和调查其常用的编译环境,幸好我有过Pascal、C和C++的语言学习经历,我对于新语言的学习还是很有信心的。通过参考书、百度,以及实际项目的实践,我认为C#语言是一种很好的语言,简洁便利,依靠基本的类库等就能实现相当多的功能。比如,Split就能用特定字符筛选,将一个字符串分割成一个字符串数组;ToLower能直接将字符串中所有大写英文字母转化为小写字母,等等。当然,我还未学会很多东西,比如我还未学会如何在函数中调用主程序中获得的字符串数组等,导致我的程序其实全部都被塞在main主程序中,程序结构很不美观……
我对于这个程序项目的理解,认为这个程序首先要做到的是“词频统计”这个功能。C#语言Split语言便利地分割了被读入的string类型的文章text,将其转化成一个string型一维数组textArray,之后只需要进行词频统计,我选择使用了从第一个词textArray[0],使其与之后的所有词进行对比,存在的每个相同的词,都会使对应的统计数组countWord[0](初值为1)+1,然后为了避免重复统计,而将之后的词向前移动,将被统计过的单词覆盖掉,之后是第二个词textArray[1],对应着countWord[1],一直进行下去。这个部分的代码如下:
1 for (int i = 0; i < sWord; i++) 2 { 3 countWord[i] = 1; 4 for (int j = i + 1; j < sWord; j++) 5 { 6 if (textArray[i].Equals(textArray[j])) 7 { 8 countWord[i]++; 9 for (int k = j + 1; k < sWord; k++) 10 textArray[k - 1] = textArray[k];//覆盖掉被查重过的单词 11 sWord--;//被查重的单词已被剔除,最后sWord将是不重复单词数量 12 j--; 13 } 14 } 15 }
之后,我注意到从功能2开始,由于文章词汇量巨大,所以只需要输出词频前10个的单词及其数量,因此在输出之前,要对词频进行排序整理,之前将词和频一一对应也正是为了这个。在词频统计和词频排序方面,我已经完成了这个小程序最基础的功能。
实现功能的截图如下:
第一个测试用例文章:
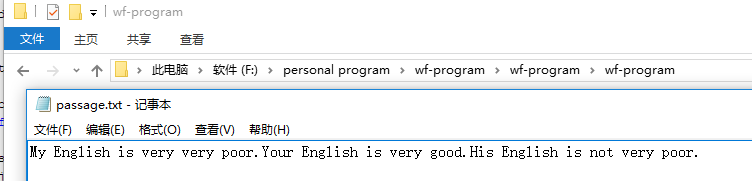
第一个样例的结果如下,其中为了测试输入的内容是否如同预期(最上方句子),被识别出来的单词数量(17)被暂时加入到代码中:
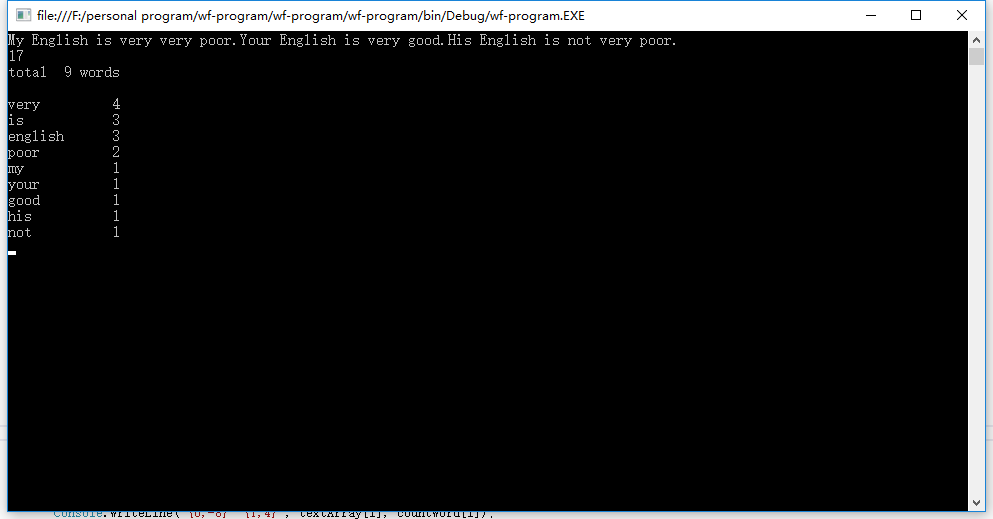
之后我准备了第二个测试用文章:

其测试结果如下,其中总词数(189)是符合作业提供的数据的:
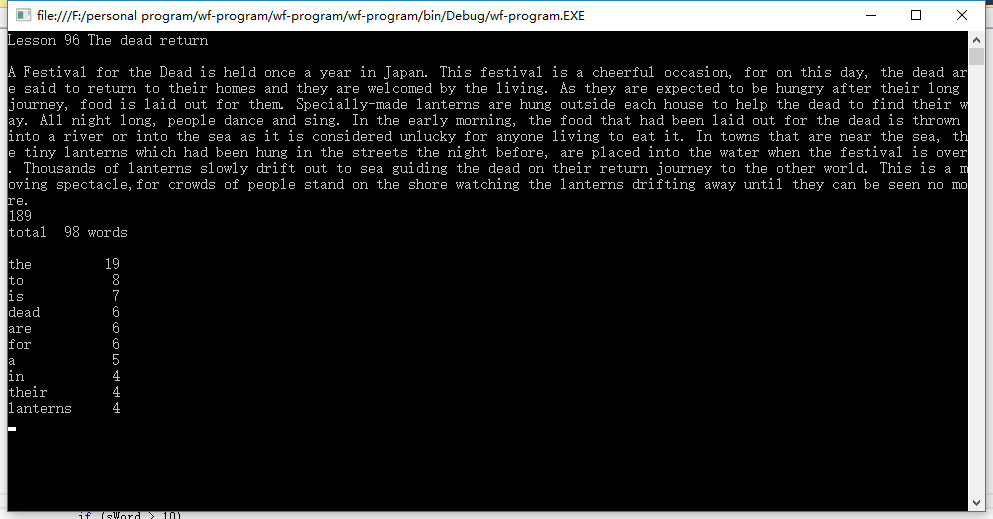
我之后也曾使用了老师提供的那篇很长的测试文章(War and Peace),然而因为我的程序初步设计只是为了达成基本功能,统计的算法极其简陋,因此运行了5分钟左右(时间不是很准确,我截图应该是慢了几秒的)才输出结果,而且总词数统计与老师的数据(568286)不同……是574756(之前我将-也作为分割标准,结果是53万左右,后来认为连词符-应该不算分割单词的依据)
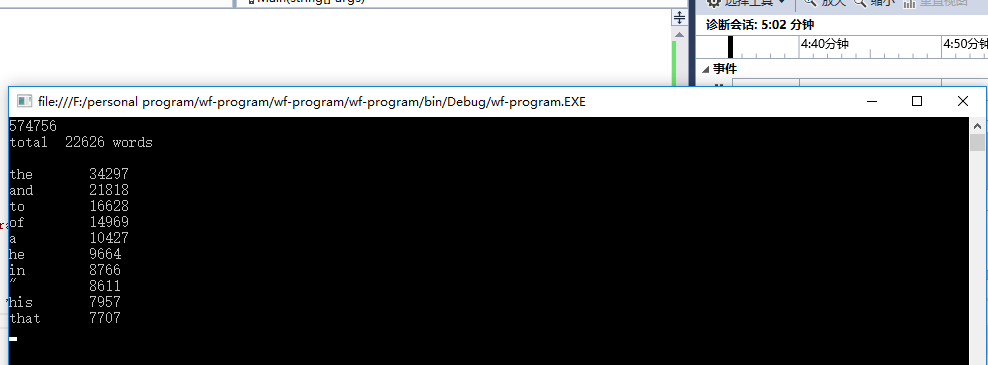
在之后我尝试了命令行的识别输入,但是由于我C#语言尚未学习透彻,因此在尝试了数小时后未果便放弃了……
————————————————————————————————————————————————
个人PSP