前言
数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据。然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了解如何从pdf文件中提取数据,并将数据转换为诸
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
如“csv”之类的格式,以便用于分析或构建模型。
在本文中,我们将重点讨论如何从pdf文件中提取数据表。类似的分析可以用于从pdf文件中提取其他类型的数据,如文本或图像。我们将说明如何从pdf文件中提取数据表,然后将其转换为适合于进一步分析和构建模型的格式。我们将给出一个实例。
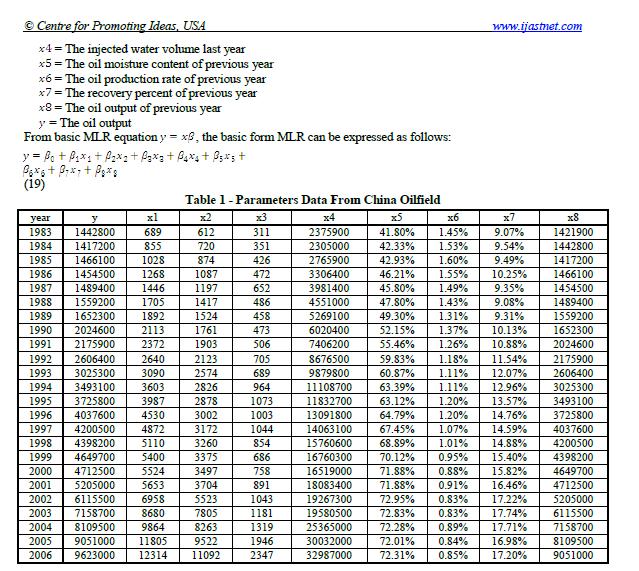
示例:使用Python从PDF文件中提取一个表格
a) 将表复制到Excel并保存为table_1_raw.csv
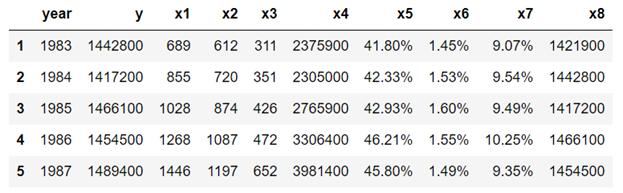
数据以一维格式存储,必须进行重塑、清理和转换。
b) 导入必要的库
- import pandas as pd
- import numpy as np
c) 导入原始数据,重新定义数据
- df=pd.read_csv("table_1_raw.csv", header=None)
- df.values.shape
- df2=pd.DataFrame(df.values.reshape(25,10))
- column_names=df2[0:1].values[0]
- df3=df2[1:]
- df3.columns = df2[0:1].values[0]
- df3.head()
d) 使用字符串处理工具进行数据纠缠
我们从上面的表格中注意到,x5、x6和x7列是用百分比表示的,所以我们需要去掉percent(%)符号:
- df4['x5']=list(map(lambda x: x[:-1], df4['x5'].values))
- df4['x6']=list(map(lambda x: x[:-1], df4['x6'].values))
- df4['x7']=list(map(lambda x: x[:-1], df4['x7'].values))
e) 将数据转换为数字形式
我们注意到列x5、x6和x7的列值数据类型为string,因此我们需要将它们转换为数值数据,如下所示:
- df4['x5']=[float(x) for x in df4['x5'].values]
- df4['x6']=[float(x) for x in df4['x6'].values]
- df4['x7']=[float(x) for x in df4['x7'].values]
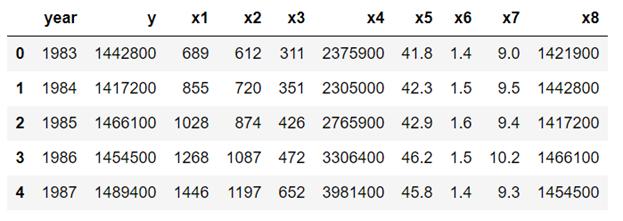
f) 查看转换数据的最终形式
- df4.head(n=5)
g) 导出最终数据到一个csv文件
- df4.to_csv('table_1_final.csv',index=False)