引用计数法
【原理】
--->引用计数器是经典的也是最古老的垃圾收集防范。
--->实现原理:对于对象A,只要有任何一个对象引用A,则计数器加1.当引用失效时,计数器减1.只要对象A的计数器值为0时,则A的为垃圾。
--->引用计数器法存在两个缺陷:
(1)无法处理循环引用的情况。A中引用B,B中引用A。无第三方对象引用A和B。则A和B为垃圾,但A和B的计数器不为0.
(2)引用计数器要求在每次因引用产生和消除的时候,需要伴随一个加法操作和减法操作,对系统性能会有一定的影响。
--->java虚拟机并没有采用这样的垃圾回收算法
【名词解释】
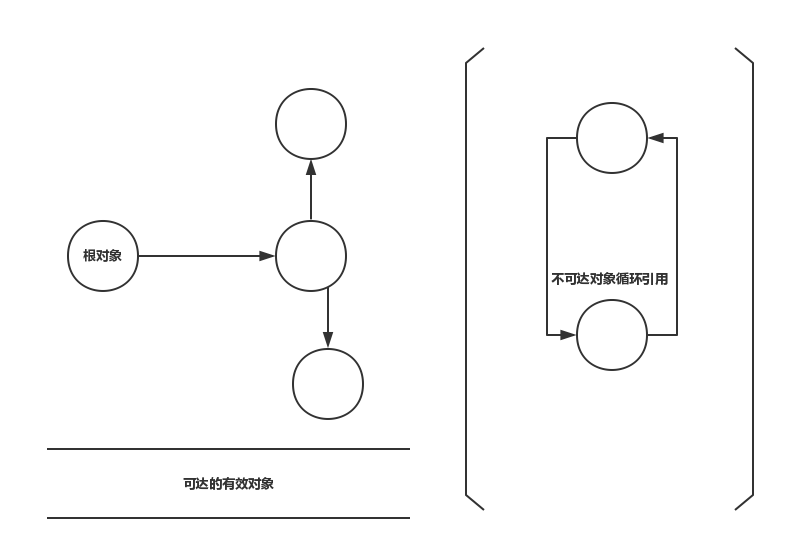
可达对象--->指通过根对象进行引用搜索,最终可以达到的对象。
不可达对象--->通过根对象进行引用搜索,最终没有被引用到的对象。
标记清除算法
--->在标记阶段,通过根节点,标记所有从根节点开始的可达对象。未被标记的就是垃圾对象可以被回收。
--->标记清除算法可能产生的最大问题是空间碎片。
--->回收后的空间是不连续的。在对象的堆空间分配过程中,尤其是大对象内存分配,不连续的内存空间的工作效率要低于连续的空间。
--->可作为GCroot的对象:
(1)虚拟机栈(栈帧中的本地变量表)中引用的对象
(2)方法区中类静态属性引用的对象
(3)方法区中常量引用的对象
(4)本地方法栈中(一般指Native方法)引用的对象
复制算法
【原理】
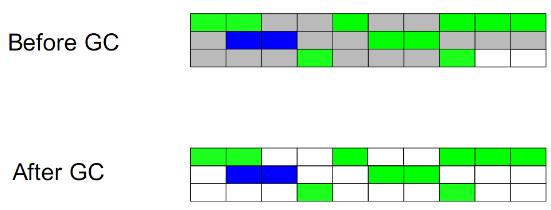
--->核心思想:将原有的内存空间分为两块,每次只使用一块。
--->在垃圾回收时,将正在使用中的内存中存活的对象复制到未使用的内存块中,之后,清除正在使用的内存块中所有的对象,交换两个内存的角色,完成垃圾回收。
--->在java新生代串行垃圾回收器中,使用了复制算法的思想。新生代分为eden空间,from空间和to空间三部分。其中from和to空间可视为用于复制的两块大小相同,地位相等,且可进行角色互换的空间块。from和to空间也称为survivor空间,即幸存者空间,用于存放未被回收的对象。
--->复制算法比较适用于新生代。因为在新生代,垃圾对象通常会多于存活对象。复制算法效果会比较好。
【名词解释】
新生代--->存放年轻对象的空间。年轻对象指刚刚创建的,或者经历垃圾回收次数不多的对象。
老年代--->存放老年对象的空间。老年对象指经历过多次垃圾回收依然存活的对象。

标记压缩法
--->复制算法的高效性,建立在存活对象少,垃圾对象多的前提下。这种情况在新生代经常发生。但是在老年代,更常见的情况是大部分对象都是存活对象。如果依然使用复制算法,由于存活的对象多,复制成本高。因此,基于老年代垃圾回收的特性,需要使用其他算法。
--->标记压缩法是一种老年代的回收算法。他在标记清除的算法基础上做了一些优化。和标记清除算法一样,标记压缩算法也首先需要从根结点开始,对所有可达对象做一次标记。但之后,它并不只是简单地清理未被标记的对象,而是将所有存活对象压缩到内存的一端,之后,清理边界外所有的空间。这样避免产生不连续内存碎片,又不需要两块相同的内存空间。
--->标记压缩法等同于标记清除算法执行完后,在进行一次内存碎片整理。

分代算法
--->分代算法,是将内存按对象的存活周期划分为新生代和老年代。从而进行回收。于之相对应的还有分区算法。
--->前文介绍了复制,标记清除,标记压缩等垃圾回收的算法。在所有这些算法中,并没有一种算法可以完全替代其他算法,他们都具有自己独特的优势和特点。因此根据垃圾回收对象的特性,使用合适的算法回收,才是明智的选择
--->一般来说,新生代的内存区,对象朝生夕死,90%的新建对象都会立马变成垃圾对象。也就是说,存活对象远远小于垃圾对象,比较适合使用复制算法。效率性能高。
--->而老年代内存区,对象的存活率几乎可达100%,如果依然使用复制算法,则需要对折内存外,还需要复制大量存活对象,而且都是大对象。效率性能低下,而且大大折扣了内存空间。因此使用标记压缩法比较合适。
--->新生代回收频率高,时间短。老年代回收频率低,时间长。但有的新生代对象,会因为占的内存大,直接进入老年代区域。每次新生代GC时,势必需要扫描老年代。这样时间就会被拖长。因此,对老年代的所有对象,有一个卡表的数据结构。相当于标记老年代内存区域所存放的对象是否是从新生代过来的。卡表(card table)数据结构,为一个比特位集合。
--->每一个比特位用来表示老年代的某一个区域中所有对象是否持有新生代对象的引用。这样在新生代GC时,不需要花大量的时间扫描老年代的对象,来确定每一个对象的引用关系。而可以先扫描卡表标记位为1的老年代区域,进行新生代完整GC。大大加快了新生代的GC
分区算法
--->一般来说,在相同条件下,堆空间越大,一次GC的时间就越长。从而产生的停顿时间也越长。
--->因此可以将内存区域进行划分为多个区域,每一个小区域,都独立使用,独立进行GC。这样可以控制一次GC回收多少个内存小区域。这样就可以更好控制GC带来的停顿时间。