time & datetime模块
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time
# print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来
# print(time.altzone) #返回与utc时间的时间差,以秒计算
# print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016",
# print(time.localtime()) #返回本地时间 的struct time对象格式
# print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式
# print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
#print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上
# 日期字符串 转成 时间戳
# string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
# print(string_2_struct)
# #
# struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
# print(struct_2_stamp)
#将时间戳转为字符串格式
# print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
# print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
#时间加减
import datetime
# print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
#print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
# print(datetime.datetime.now() )
# print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
# print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
# print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
# print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
#
# c_time = datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #时间替换
OS模块
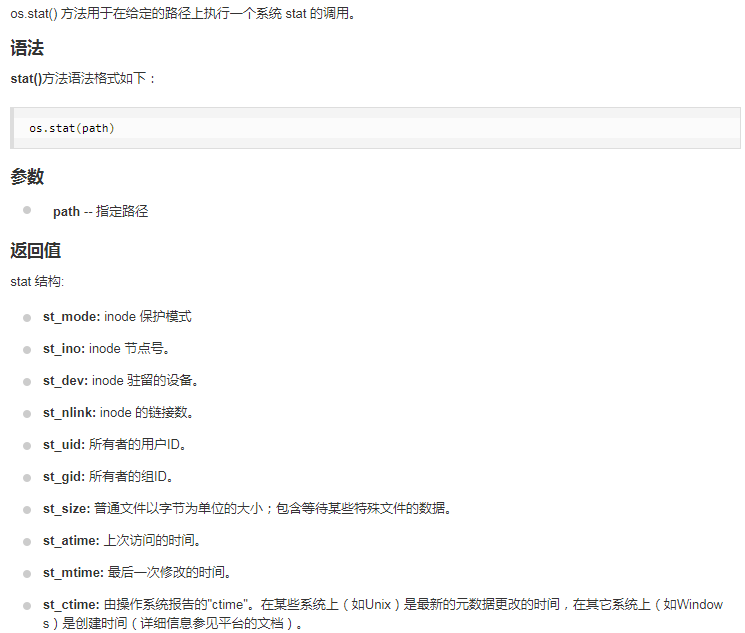
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" " os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间


sys模块 1 2 3 4 5 6 7 8 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write('please:') val = sys.stdin.readline()[:-1]
1 如果想用python生成一个文档,配置文件模块configparser 2 import configparser 3 4 config = configparser.ConfigParser() 5 config["DEFAULT"] = {'ServerAliveInterval': '45', 6 'Compression': 'yes', 7 'CompressionLevel': '9'} 8 9 config['bitbucket.org'] = {} 10 config['bitbucket.org']['User'] = 'hg' 11 config['topsecret.server.com'] = {} 12 topsecret = config['topsecret.server.com'] 13 topsecret['Host Port'] = '50022' # mutates the parser 14 topsecret['ForwardX11'] = 'no' # same here 15 config['DEFAULT']['ForwardX11'] = 'yes' 16 with open('example.ini', 'w') as configfile: 17 config.write(configfile)
1 import configparser 2 >>> config = configparser.ConfigParser() 3 >>> config.sections() 4 [] 5 >>> config.read('example.ini') 6 ['example.ini'] 7 >>> config.sections() 8 ['bitbucket.org', 'topsecret.server.com'] 9 >>> 'bitbucket.org' in config 10 True 11 >>> 'bytebong.com' in config 12 False 13 >>> config['bitbucket.org']['User'] 14 'hg' 15 >>> config['DEFAULT']['Compression'] 16 'yes' 17 >>> topsecret = config['topsecret.server.com'] 18 >>> topsecret['ForwardX11'] 19 'no' 20 >>> topsecret['Port'] 21 '50022' 22 >>> for key in config['bitbucket.org']: print(key) 23 ... 24 user 25 compressionlevel 26 serveraliveinterval 27 compression 28 forwardx11 29 >>> config['bitbucket.org']['ForwardX11'] 30 'yes'
configparser增删改查语法
[section1] k1 = v1 k2:v2 [section2] k1 = v1 import ConfigParser config = ConfigParser.ConfigParser() config.read('i.cfg') # ########## 读 ########## #secs = config.sections() #print secs #options = config.options('group2') #print options #item_list = config.items('group2') #print item_list #val = config.get('group1','key') #val = config.getint('group1','key') # ########## 改写 ########## #sec = config.remove_section('group1') #config.write(open('i.cfg', "w")) #sec = config.has_section('wupeiqi') #sec = config.add_section('wupeiqi') #config.write(open('i.cfg', "w")) #config.set('group2','k1',11111) #config.write(open('i.cfg', "w")) #config.remove_option('group2','age') #config.write(open('i.cfg', "w"))
haslib
import hashlib m = hashlib.md5() m.update(b"Hello") m.update(b"It's me") print(m.digest()) m.update(b"It's been a long time since last time we ...") print(m.digest()) #2进制格式hash print(len(m.hexdigest())) #16进制格式hash
re模块
'.' 默认匹配除
之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","
abc
eee",flags=re.MULTILINE)'$' 匹配字符结尾,或e.search("foo$","bfoo
sdfsf",flags=re.MULTILINE).group()也可以'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?' 匹配前一个字符1次或0次'{m}' 匹配前一个字符m次'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c'A' 只从字符开头匹配,re.search("Aabc","alexabc") 是匹配不到的'' 匹配字符结尾,同$'d' 匹配数字0-9'D' 匹配非数字'w' 匹配[A-Za-z0-9]'W' 匹配非[A-Za-z0-9]'s' 匹配空白字符、 、
、
, re.search("s+","ab c1
3").group() 结果 ' 're.match 从头开始匹配
re.search 匹配包含re.findall 把所有匹配到的字符放到以列表中的元素返回re.splitall 以匹配到的字符当做列表分隔符re.sub 匹配字符并替换六、序列化
Python中用于序列化的两个模块
- json 用于【字符串】和 【python基本数据类型】 间进行转换
- pickle 用于【python特有的类型】 和 【python基本数据类型】间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
详解Python的装饰器
Python中的装饰器是你进入Python大门的一道坎,不管你跨不跨过去它都在那里。
为什么需要装饰器#
我们假设你的程序实现了say_hello()和say_goodbye()两个函数。
def say_hello():
print "hello!"
def say_goodbye():
print "hello!" # bug here
if __name__ == '__main__':
say_hello()
say_goodbye()但是在实际调用中,我们发现程序出错了,上面的代码打印了两个hello。经过调试你发现是say_goodbye()出错了。老板要求调用每个方法前都要记录进入函数的名称,比如这样:
[DEBUG]: Enter say_hello()
Hello!
[DEBUG]: Enter say_goodbye()
Goodbye!好,小A是个毕业生,他是这样实现的。
def say_hello():
print "[DEBUG]: enter say_hello()"
print "hello!"
def say_goodbye():
print "[DEBUG]: enter say_goodbye()"
print "hello!"
if __name__ == '__main__':
say_hello()
say_goodbye()很low吧? 嗯是的。小B工作有一段时间了,他告诉小A可以这样写。
def debug():
import inspect
caller_name = inspect.stack()[1][3]
print "[DEBUG]: enter {}()".format(caller_name)
def say_hello():
debug()
print "hello!"
def say_goodbye():
debug()
print "goodbye!"
if __name__ == '__main__':
say_hello()
say_goodbye()是不是好一点?那当然,但是每个业务函数里都要调用一下debug()函数,是不是很难受?万一老板说say相关的函数不用debug,do相关的才需要呢?
那么装饰器这时候应该登场了。
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
概括的讲,装饰器的作用就是为已经存在的函数或对象添加额外的功能。
怎么写一个装饰器#
在早些时候 (Python Version < 2.4,2004年以前),为一个函数添加额外功能的写法是这样的。
def debug(func):
def wrapper():
print "[DEBUG]: enter {}()".format(func.__name__)
return func()
return wrapper
def say_hello():
print "hello!"
say_hello = debug(say_hello) # 添加功能并保持原函数名不变上面的debug函数其实已经是一个装饰器了,它对原函数做了包装并返回了另外一个函数,额外添加了一些功能。因为这样写实在不太优雅,在后面版本的Python中支持了@语法糖,下面代码等同于早期的写法。
def debug(func):
def wrapper():
print "[DEBUG]: enter {}()".format(func.__name__)
return func()
return wrapper
@debug
def say_hello():
print "hello!"这是最简单的装饰器,但是有一个问题,如果被装饰的函数需要传入参数,那么这个装饰器就坏了。因为返回的函数并不能接受参数,你可以指定装饰器函数wrapper接受和原函数一样的参数,比如:
def debug(func):
def wrapper(something): # 指定一毛一样的参数
print "[DEBUG]: enter {}()".format(func.__name__)
return func(something)
return wrapper # 返回包装过函数
@debug
def say(something):
print "hello {}!".format(something)这样你就解决了一个问题,但又多了N个问题。因为函数有千千万,你只管你自己的函数,别人的函数参数是什么样子,鬼知道?还好Python提供了可变参数*args和关键字参数**kwargs,有了这两个参数,装饰器就可以用于任意目标函数了。
def debug(func):
def wrapper(*args, **kwargs): # 指定宇宙无敌参数
print "[DEBUG]: enter {}()".format(func.__name__)
print 'Prepare and say...',
return func(*args, **kwargs)
return wrapper # 返回
@debug
def say(something):
print "hello {}!".format(something)至此,你已完全掌握初级的装饰器写法。
高级一点的装饰器#
带参数的装饰器和类装饰器属于进阶的内容。在理解这些装饰器之前,最好对函数的闭包和装饰器的接口约定有一定了解。(参见https://betacat.online/posts/2016-10-23/python-closure/)
带参数的装饰器#
假设我们前文的装饰器需要完成的功能不仅仅是能在进入某个函数后打出log信息,而且还需指定log的级别,那么装饰器就会是这样的。
def logging(level):
def wrapper(func):
def inner_wrapper(*args, **kwargs):
print "[{level}]: enter function {func}()".format(
level=level,
func=func.__name__)
return func(*args, **kwargs)
return inner_wrapper
return wrapper
@logging(level='INFO')
def say(something):
print "say {}!".format(something)
# 如果没有使用@语法,等同于
# say = logging(level='INFO')(say)
@logging(level='DEBUG')
def do(something):
print "do {}...".format(something)
if __name__ == '__main__':
say('hello')
do("my work")是不是有一些晕?你可以这么理解,当带参数的装饰器被打在某个函数上时,比如@logging(level='DEBUG'),它其实是一个函数,会马上被执行,只要这个它返回的结果是一个装饰器时,那就没问题。细细再体会一下。
基于类实现的装饰器#
装饰器函数其实是这样一个接口约束,它必须接受一个callable对象作为参数,然后返回一个callable对象。在Python中一般callable对象都是函数,但也有例外。只要某个对象重载了__call__()方法,那么这个对象就是callable的。
class Test():
def __call__(self):
print 'call me!'
t = Test()
t() # call me像__call__这样前后都带下划线的方法在Python中被称为内置方法,有时候也被称为魔法方法。重载这些魔法方法一般会改变对象的内部行为。上面这个例子就让一个类对象拥有了被调用的行为。
回到装饰器上的概念上来,装饰器要求接受一个callable对象,并返回一个callable对象(不太严谨,详见后文)。那么用类来实现也是也可以的。我们可以让类的构造函数__init__()接受一个函数,然后重载__call__()并返回一个函数,也可以达到装饰器函数的效果。
class logging(object):
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
print "[DEBUG]: enter function {func}()".format(
func=self.func.__name__)
return self.func(*args, **kwargs)
@logging
def say(something):
print "say {}!".format(something)带参数的类装饰器#
如果需要通过类形式实现带参数的装饰器,那么会比前面的例子稍微复杂一点。那么在构造函数里接受的就不是一个函数,而是传入的参数。通过类把这些参数保存起来。然后在重载__call__方法是就需要接受一个函数并返回一个函数。
class logging(object):
def __init__(self, level='INFO'):
self.level = level
def __call__(self, func): # 接受函数
def wrapper(*args, **kwargs):
print "[{level}]: enter function {func}()".format(
level=self.level,
func=func.__name__)
func(*args, **kwargs)
return wrapper #返回函数
@logging(level='INFO')
def say(something):
print "say {}!".format(something)内置的装饰器#
内置的装饰器和普通的装饰器原理是一样的,只不过返回的不是函数,而是类对象,所以更难理解一些。
@property#
在了解这个装饰器前,你需要知道在不使用装饰器怎么写一个属性。
def getx(self):
return self._x
def setx(self, value):
self._x = value
def delx(self):
del self._x
# create a property
x = property(getx, setx, delx, "I am doc for x property")以上就是一个Python属性的标准写法,其实和Java挺像的,但是太罗嗦。有了@语法糖,能达到一样的效果但看起来更简单。
@property
def x(self): ...
# 等同于
def x(self): ...
x = property(x)属性有三个装饰器:setter, getter, deleter ,都是在property()的基础上做了一些封装,因为setter和deleter是property()的第二和第三个参数,不能直接套用@语法。getter装饰器和不带getter的属性装饰器效果是一样的,估计只是为了凑数,本身没有任何存在的意义。经过@property装饰过的函数返回的不再是一个函数,而是一个property对象。
>>> property()
<property object at 0x10ff07940>@staticmethod,@classmethod#
有了@property装饰器的了解,这两个装饰器的原理是差不多的。@staticmethod返回的是一个staticmethod类对象,而@classmethod返回的是一个classmethod类对象。他们都是调用的是各自的__init__()构造函数。
class classmethod(object):
"""
classmethod(function) -> method
"""
def __init__(self, function): # for @classmethod decorator
pass
# ...
class staticmethod(object):
"""
staticmethod(function) -> method
"""
def __init__(self, function): # for @staticmethod decorator
pass
# ...装饰器的@语法就等同调用了这两个类的构造函数。
class Foo(object):
@staticmethod
def bar():
pass
# 等同于 bar = staticmethod(bar)至此,我们上文提到的装饰器接口定义可以更加明确一些,装饰器必须接受一个callable对象,其实它并不关心你返回什么,可以是另外一个callable对象(大部分情况),也可以是其他类对象,比如property。
装饰器里的那些坑#
装饰器可以让你代码更加优雅,减少重复,但也不全是优点,也会带来一些问题。
位置错误的代码#
让我们直接看示例代码。
def html_tags(tag_name):
print 'begin outer function.'
def wrapper_(func):
print "begin of inner wrapper function."
def wrapper(*args, **kwargs):
content = func(*args, **kwargs)
print "<{tag}>{content}</{tag}>".format(tag=tag_name, content=content)
print 'end of inner wrapper function.'
return wrapper
print 'end of outer function'
return wrapper_
@html_tags('b')
def hello(name='Toby'):
return 'Hello {}!'.format(name)
hello()
hello()在装饰器中我在各个可能的位置都加上了print语句,用于记录被调用的情况。你知道他们最后打印出来的顺序吗?如果你心里没底,那么最好不要在装饰器函数之外添加逻辑功能,否则这个装饰器就不受你控制了。以下是输出结果:
begin outer function.
end of outer function
begin of inner wrapper function.
end of inner wrapper function.
<b>Hello Toby!</b>
<b>Hello Toby!</b>错误的函数签名和文档#
装饰器装饰过的函数看上去名字没变,其实已经变了。
def logging(func):
def wrapper(*args, **kwargs):
"""print log before a function."""
print "[DEBUG] {}: enter {}()".format(datetime.now(), func.__name__)
return func(*args, **kwargs)
return wrapper
@logging
def say(something):
"""say something"""
print "say {}!".format(something)
print say.__name__ # wrapper为什么会这样呢?只要你想想装饰器的语法糖@代替的东西就明白了。@等同于这样的写法。
say = logging(say)logging其实返回的函数名字刚好是wrapper,那么上面的这个语句刚好就是把这个结果赋值给say,say的__name__自然也就是wrapper了,不仅仅是name,其他属性也都是来自wrapper,比如doc,source等等。
使用标准库里的functools.wraps,可以基本解决这个问题。
from functools import wraps
def logging(func):
@wraps(func)
def wrapper(*args, **kwargs):
"""print log before a function."""
print "[DEBUG] {}: enter {}()".format(datetime.now(), func.__name__)
return func(*args, **kwargs)
return wrapper
@logging
def say(something):
"""say something"""
print "say {}!".format(something)
print say.__name__ # say
print say.__doc__ # say something看上去不错!主要问题解决了,但其实还不太完美。因为函数的签名和源码还是拿不到的。
import inspect
print inspect.getargspec(say) # failed
print inspect.getsource(say) # failed如果要彻底解决这个问题可以借用第三方包,比如wrapt。后文有介绍。
不能装饰@staticmethod 或者 @classmethod#
当你想把装饰器用在一个静态方法或者类方法时,不好意思,报错了。
class Car(object):
def __init__(self, model):
self.model = model
@logging # 装饰实例方法,OK
def run(self):
print "{} is running!".format(self.model)
@logging # 装饰静态方法,Failed
@staticmethod
def check_model_for(obj):
if isinstance(obj, Car):
print "The model of your car is {}".format(obj.model)
else:
print "{} is not a car!".format(obj)
"""
Traceback (most recent call last):
...
File "example_4.py", line 10, in logging
@wraps(func)
File "C:Python27libfunctools.py", line 33, in update_wrapper
setattr(wrapper, attr, getattr(wrapped, attr))
AttributeError: 'staticmethod' object has no attribute '__module__'
"""前面已经解释了@staticmethod这个装饰器,其实它返回的并不是一个callable对象,而是一个staticmethod对象,那么它是不符合装饰器要求的(比如传入一个callable对象),你自然不能在它之上再加别的装饰器。要解决这个问题很简单,只要把你的装饰器放在@staticmethod之前就好了,因为你的装饰器返回的还是一个正常的函数,然后再加上一个@staticmethod是不会出问题的。
class Car(object):
def __init__(self, model):
self.model = model
@staticmethod
@logging # 在@staticmethod之前装饰,OK
def check_model_for(obj):
pass如何优化你的装饰器#
嵌套的装饰函数不太直观,我们可以使用第三方包类改进这样的情况,让装饰器函数可读性更好。
decorator.py#
decorator.py 是一个非常简单的装饰器加强包。你可以很直观的先定义包装函数wrapper(),再使用decorate(func, wrapper)方法就可以完成一个装饰器。
from decorator import decorate
def wrapper(func, *args, **kwargs):
"""print log before a function."""
print "[DEBUG] {}: enter {}()".format(datetime.now(), func.__name__)
return func(*args, **kwargs)
def logging(func):
return decorate(func, wrapper) # 用wrapper装饰func你也可以使用它自带的@decorator装饰器来完成你的装饰器。
from decorator import decorator
@decorator
def logging(func, *args, **kwargs):
print "[DEBUG] {}: enter {}()".format(datetime.now(), func.__name__)
return func(*args, **kwargs)decorator.py实现的装饰器能完整保留原函数的name,doc和args,唯一有问题的就是inspect.getsource(func)返回的还是装饰器的源代码,你需要改成inspect.getsource(func.__wrapped__)。
wrapt#
wrapt是一个功能非常完善的包,用于实现各种你想到或者你没想到的装饰器。使用wrapt实现的装饰器你不需要担心之前inspect中遇到的所有问题,因为它都帮你处理了,甚至inspect.getsource(func)也准确无误。
import wrapt
# without argument in decorator
@wrapt.decorator
def logging(wrapped, instance, args, kwargs): # instance is must
print "[DEBUG]: enter {}()".format(wrapped.__name__)
return wrapped(*args, **kwargs)
@logging
def say(something): pass使用wrapt你只需要定义一个装饰器函数,但是函数签名是固定的,必须是(wrapped, instance, args, kwargs),注意第二个参数instance是必须的,就算你不用它。当装饰器装饰在不同位置时它将得到不同的值,比如装饰在类实例方法时你可以拿到这个类实例。根据instance的值你能够更加灵活的调整你的装饰器。另外,args和kwargs也是固定的,注意前面没有星号。在装饰器内部调用原函数时才带星号。
如果你需要使用wrapt写一个带参数的装饰器,可以这样写。
def logging(level):
@wrapt.decorator
def wrapper(wrapped, instance, args, kwargs):
print "[{}]: enter {}()".format(level, wrapped.__name__)
return wrapped(*args, **kwargs)
return wrapper
@logging(level="INFO")
def do(work): pass关于wrapt的使用,建议查阅官方文档,在此不在赘述。
- http://wrapt.readthedocs.io/en/latest/quick-start.html
小结#
Python的装饰器和Java的注解(Annotation)并不是同一回事,和C#中的特性(Attribute)也不一样,完全是两个概念。
装饰器的理念是对原函数、对象的加强,相当于重新封装,所以一般装饰器函数都被命名为wrapper(),意义在于包装。函数只有在被调用时才会发挥其作用。比如@logging装饰器可以在函数执行时额外输出日志,@cache装饰过的函数可以缓存计算结果等等。
而注解和特性则是对目标函数或对象添加一些属性,相当于将其分类。这些属性可以通过反射拿到,在程序运行时对不同的特性函数或对象加以干预。比如带有Setup的函数就当成准备步骤执行,或者找到所有带有TestMethod的函数依次执行等等。
生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
生成器表达式(generator expression)
L = [x + 1 for x in range(10)]
print(L)
1
2
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
1
列表生成式
实现列表元素加1,列表生成式与其它方法比较:
#普通方法1
b = []
for i in range(10):
b.append(i+1)
print(b)
#普通方法2
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
for index,i in enumerate(a):
a[index] +=1
print(a)
#map,lambda
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = map(lambda x:x+1, a)
print(list(a))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
1
2
3
g = (x + 1 for x in range(10))
print(g)
1
2
<generator object <genexpr> at 0x7fe03ad859a8>
1
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数(or __next__())获得generator的下一个返回值:
next(g)
1
1
1
next(g)
1
2
1
next(g)
1
3
1
g.__next__()
1
4
1
g.__next__()
1
5
1
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误
上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
g = (x * x for x in range(10))
for n in g:
print(n,end=";")
1
2
3
0;1;4;9;16;25;36;49;64;81;
1
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误
通过使用yield关键字定义
生成器对象是通过使用yield关键字定义的函数对象,因此,生成器也是一个函数。生成器用于生成一个值得序列,以便在迭代器中使用。
"""
第一是直接作为脚本执行,
第二是import到其他的python脚本中被调用(模块重用)执行。
因此if __name__ == '__main__': 的作用就是控制这两种情况执行代码的过程,
在if __name__ == '__main__':下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的。
"""
def myYield(n):
while n>0:
print('开始生成。。。')
yield n
print('完成一次。。。')
n -= 1
if __name__ == '__main__':
a = myYield(3)
print('已经实例化生成器对象')
# a.__next__()
# print('第二次调用__next__()方法:')
# a.__next__()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
已经实例化生成器对象
1
yield 语句是生成器中的关键语句,生成器在实例化时并不会被执行,而是等待调用其__next__()方法才开始运行。并且当程序运行完yield语句后就会“吼(hold)住”,即保持当前状态且停止运行,等待下一次遍历时才恢复运行。
程序运行的结果中的空行后的输出“已经实例化生成器对象”之前,已经实例化了生成器对象,但生成器并没有运行(没有输出‘开始生成’)。当第一次手工调用__next__()方法之后,才输出‘开始生成’,标志着生成器已经运行,而在输出‘’第二次调用__next__()方法‘’之前并没有输出‘完成一次’,说明yield语句运行之后就立即停止了。而第二次调用__next__()方法之后,才输出‘完成一次’,说明生成器的回复运行是从yield语句之后开始运行的
return_value = a.__next__()
print(return_value)
1
2
开始生成。。。
3
1
2
print('第二次调用__next__()方法:')
1
第二次调用__next__()方法:
1
return_value = a.__next__()
print(return_value)
1
2
完成一次。。。
开始生成。。。
2
1
2
3
著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
1
2
3
4
5
6
7
注意,赋值语句:
a, b = b, a + b
1
相当于:
t = (b, a + b) # t是一个tuple
a = t[0]
b = t[1]
1
2
3
上面的函数可以输出斐波那契数列的前N个数:
fib(5)
1
1
1
2
3
5
'done'
1
2
3
4
5
6
7
8
9
10
11
上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max):
n,a,b = 0,0,1
while n < max:
#print(b)
yield b
a,b = b,a+b
n += 1
return 'well done'
1
2
3
4
5
6
7
8
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
f = fib(5)
print(f)
print(list(f))
#重新实例化生成器对象
f = fib(5)
1
2
3
4
5
6
<generator object fib at 0x7fe038493840>
[1, 1, 2, 3, 5]
1
2
print(f.__next__())
print(f.__next__())
print("干点别的事")
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
1
2
3
4
5
6
7
1
1
干点别的事
2
3
5
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-18-9609f54647c6> in <module>
5 print(f.__next__())
6 print(f.__next__())
----> 7 print(f.__next__())
StopIteration: well done
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
g = fib(6)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
1
2
3
4
5
6
7
8
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: well done
1
2
3
4
5
6
7
from itertools import islice
def fib():
a,b = 0,1
while True:
yield b
a,b = b,a+b
f = fib()
print(list(islice(f ,0,10)))
1
2
3
4
5
6
7
8
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
1
生成器在Python中是一个非常强大的编程结构,可以用更少地中间变量写流式代码,此外,相比其它容器对象它更能节省内存和CPU,当然它可以用更少的代码来实现相似的功能。现在就可以动手重构你的代码了,但凡看到类似
def something():
result= []
for ... in ...:
result.append(x)
return result
1
2
3
4
5
都可以用生成器函数来替换:
def iter_something():
result = []
for ... in ...:
yield x
1
2
3
4
杨辉三角
期待输出:
[1]
[1, 1]
[1, 2, 1]
[1, 3, 3, 1]
[1, 4, 6, 4, 1]
[1, 5, 10, 10, 5, 1]
[1, 6, 15, 20, 15, 6, 1]
[1, 7, 21, 35, 35, 21, 7, 1]
[1, 8, 28, 56, 70, 56, 28, 8, 1]
[1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
1
2
3
4
5
6
7
8
9
10
def triangles():
result = [1]
while True:
yield result
result = [1] + [result[i] + result[i+1] for i in range(len(result)-1)] + [1]
1
2
3
4
5
n = 0
results = []
for t in triangles():
print(t)
results.append(t)
n = n + 1
if n == 10:
break
if results == [
[1],
[1, 1],
[1, 2, 1],
[1, 3, 3, 1],
[1, 4, 6, 4, 1],
[1, 5, 10, 10, 5, 1],
[1, 6, 15, 20, 15, 6, 1],
[1, 7, 21, 35, 35, 21, 7, 1],
[1, 8, 28, 56, 70, 56, 28, 8, 1],
[1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
]:
print('测试通过!')
else:
print('测试失败!')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
[1]
[1, 1]
[1, 2, 1]
[1, 3, 3, 1]
[1, 4, 6, 4, 1]
[1, 5, 10, 10, 5, 1]
[1, 6, 15, 20, 15, 6, 1]
[1, 7, 21, 35, 35, 21, 7, 1]
[1, 8, 28, 56, 70, 56, 28, 8, 1]
[1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
测试通过!
1
2
3
4
5
6
7
8
9
10
11
生成器并行
前戏
def gen():
a = yield 1
print('yield a % s' % a)
b = yield 2
print('yield b % s' % b)
c = yield 3
print('yield c % s' % c)
return "happy ending"
r = gen()
x = next(r)
print('next x %s' % x)
y = r.send(10)
print('next y %s' %y)
z = next(r)
print('next z %s' % z)
try:
a = next(r)
except StopIteration as e:
print(e)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
next x 1
yield a 10
next y 2
yield b None
next z 3
yield c None
happy ending
1
2
3
4
5
6
7
运行过程说明:
第一步:r = gen(),实例化一个生成器对象
第二步:调用next() ,遇到yield 暂停,返回值1,赋值给x
第三步:打印x的值
第四步:传值10,在暂停处接受值10,赋值给a,继续运行,打印a的值,遇到第二个yield,暂停,返回值2,赋值给y
第五步:打印y的值
第六步:调用next() ,打印b值,遇到第三个yield暂停,返回值3,赋值给z
第七步:打印z值
第八步:调用next(),打印c的值,报StopIteration错误,用try。。。except捕获错误
高潮
import time
import random
food = ["韭菜鸡蛋","猪肉白菜","猪肉荠菜","羊肉白菜","猪肉大葱","虾仁海鲜"]
def consumer(name):
print("%s 准备吃包子啦!" %name)
while True:
baozi = yield 'n'
print("[%s]馅包子来了,被[%s]吃了!" %(baozi,name))
def producer(name):
c1 = consumer('大儿子')
c2 = consumer('小儿子')
c1.__next__()
c2.__next__()
print("%s开始准备做包子啦" % name)
for i in range(6):
print("第%d次做了%s个包子"%(i+1,len(food)))
time.sleep(random.randint(1,3))
f1 = food[i]
c1.send(f1)
food.append(f1)
random.shuffle(food)
c2.send(food[i])
producer('老子')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
大儿子 准备吃包子啦!
小儿子 准备吃包子啦!
老子开始准备做包子啦
第1次做了6个包子
[韭菜鸡蛋]馅包子来了,被[大儿子]吃了!
[韭菜鸡蛋]馅包子来了,被[小儿子]吃了!
第2次做了7个包子
[韭菜鸡蛋]馅包子来了,被[大儿子]吃了!
[猪肉大葱]馅包子来了,被[小儿子]吃了!
第3次做了8个包子
[韭菜鸡蛋]馅包子来了,被[大儿子]吃了!
[猪肉大葱]馅包子来了,被[小儿子]吃了!
第4次做了9个包子
[猪肉白菜]馅包子来了,被[大儿子]吃了!
[羊肉白菜]馅包子来了,被[小儿子]吃了!
第5次做了10个包子
[虾仁海鲜]馅包子来了,被[大儿子]吃了!
[韭菜鸡蛋]馅包子来了,被[小儿子]吃了!
第6次做了11个包子
[韭菜鸡蛋]馅包子来了,被[大儿子]吃了!
[虾仁海鲜]馅包子来了,被[小儿子]吃了!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
迭代器
迭代器概述
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list,tuple,dict,set,str等
一类是generator ,包括生成器和带yeild的generator function
这些可以 直接作用于for循环的对象统称为可迭代对象:Iterable
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
a = [i for i in range(10)]
next(a)
1
2
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-23-8981550fe3e0> in <module>
1 a = [i for i in range(10)]
----> 2 next(a)
TypeError: 'list' object is not an iterator
1
2
3
4
5
6
7
8
9
10
list,dict,str虽然是Iterable,却不是Iterator
from collections import Iterator
from collections import Iterable
print(isinstance(a,Iterator))
print(isinstance(a,Iterable))
print(isinstance({},Iterable))
print(isinstance('abc',Iterable))
1
2
3
4
5
6
False
True
True
True
1
2
3
4
生成器就是一个迭代器
a = (i for i in range(10))
print(next(a))
print(isinstance(a,Iterator))
1
2
3
0
True
1
2
iter()函数 创建迭代器
iter(iterable)#一个参数,要求参数为可迭代的类型
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
print(isinstance({},Iterator))
print(isinstance('abc',Iterator))
print(isinstance(iter({}),Iterator))
print(isinstance(iter('abc'),Iterator))
1
2
3
4
False
False
True
True
1
2
3
4
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
print(x,end=',')
1
2
1,2,3,4,5,
1
实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
print(x,end=',')
except StopIteration:
# 遇到StopIteration就退出循环
break
1
2
3
4
5
6
7
8
9
10
11
12
1,2,3,4,5,
1
创建一个迭代器(类)
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。
如果你已经了解的面向对象编程,就知道类都有一个构造函数,Python 的构造函数为 __init__(), 它会在对象初始化的时候执行
__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成。
from itertools import islice
class Fib:
def __init__(self):
self.prev = 0
self.curr = 1
def __iter__(self):
return self
def __next__(self):
self.prev,self.curr = self.curr,self.prev+self.curr
return self.curr
f = Fib()
print(list(islice(f ,0,10)))
1
2
3
4
5
6
7
8
9
10
11
12
[1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
1
Fib既是一个可迭代对象(因为它实现了 __iter__方法),又是一个迭代器(因为实现了 __next__方法)
StopIteration
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 next() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
在 20 次迭代后停止执行:
class MyNumbers:
def __init__(self):
self.a = 1
def __iter__(self):
return self
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNumbers()
myiter = MyNumbers()
# myiter = iter(myclass)
for x in myiter:
print(x,end=",")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,
1
内置迭代器工具
比如 itertools 函数返回的都是迭代器对象
count无限迭代器
from itertools import count
counter = count(start=10)
print(next(counter))
print(next(counter)) #python内建函数next()对itertools创建的迭代器进行循环
1
2
3
4
10
11
1
2
cycle 无限迭代器,从一个有限序列中生成无限序列:
from itertools import cycle
colors = cycle(['red','black','blue'])
print(next(colors))
print(next(colors))
print(next(colors))
print(next(colors))
print(next(colors))
1
2
3
4
5
6
7
red
black
blue
red
black
1
2
3
4
5
itertools的子模块 islice 控制无限迭代器输出的方式
islice的第二个参数控制何时停止迭代,迭代了11次后停止,从无限的序列中生成有限序列:
from itertools import count
counter = count(start=10)
i=4
print(next(counter))
while i > 0:
print(next(counter))
i -= 1
1
2
3
4
5
6
7
10
11
12
13
14
1
2
3
4
5
from itertools import count
for i in count(10):
if i > 14 :
break
else:
print(i)
1
2
3
4
5
6
10
11
12
13
14
1
2
3
4
5
from itertools import islice
from itertools import count
for i in islice(count(10),5):
print(i)
1
2
3
4
10
11
12
13
14
1
2
3
4
5
from itertools import cycle
from itertools import islice
colors = cycle(['red','black','blue'])
limited = islice(colors,0,4)
for x in limited:
print(x)
1
2
3
4
5
6
red
black
blue
red
1
2
3
4
装饰器
器,代表函数的意思
装饰器:本质是函数(装饰其他函数)就是为其他函数添加附加功能
每个人都有的内裤主要功能是用来遮羞,但是到了冬天它没法为我们防风御寒,咋办?我们想到的一个办法就是把内裤改造一下,让它变得更厚更长,这样一来,它不仅有遮羞功能,还能提供保暖,不过有个问题,这个内裤被我们改造成了长裤后,虽然还有遮羞功能,但本质上它不再是一条真正的内裤了。于是聪明的人们发明长裤,在不影响内裤的前提下,直接把长裤套在了内裤外面,这样内裤还是内裤,有了长裤后宝宝再也不冷了。装饰器就像我们这里说的长裤,在不影响内裤作用的前提下,给我们的身子提供了保暖的功效。
原则:
1 不能修改被装饰的函数的源代码
2 不能修改被装饰的函数的调用方式
实现装饰器知识储备:
1 函数即“”变量“”
2 高阶函数
a 把一个函数名当做实参传给另一个函数
b 返回值中包含函数名
高阶函数
import time
def bar():
time.sleep(3)
print('in the bar')
def test2(func):
print(func)
return func
print(test2(bar)) #调用test2,打印bar的内存地址,返回bar的内存地址,又打印
1
2
3
4
5
6
7
8
9
<function bar at 0x7fe03849e620>
<function bar at 0x7fe03849e620>
1
2
bar=test2(bar) # 返回的bar的内存地址,赋值给bar
bar() #run bar
1
2
<function bar at 0x7fe03849e620>
in the bar
1
2
嵌套函数
x = 0
def grandpa():
x = 1
print(x)
def dad():
x =2
print(x)
def son():
x =3
print(x)
son()
dad()
grandpa()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
3
1
2
3
一、字符集
字符集:就是用来定义字符在数据库中的编码的集合。
常见的字符集:utf8、Unicode、GBK、GB2312(支持中文)、ASCCI(不支持中文)
作者本人用的是utf8_general_ci
-
后缀ci (case insensitive)意味不区分大小写(大小写不敏感),后缀cs (case sensitive)区分大小写(大小写敏感)
-
utf8_bin 规定每个字符串用二进制编码存储,区分大小写,可以直接存储二进制的内容
-
如ci情况下:select name,age from userinfo; 等价于SELECT NAME,AgE FROM userinfo; 大小写字符判断是一样的
-
而在cs情况下:假设字段名严格为name, age,表名:UserInfo。那么就必须:select name,age from UserInfo; 大小写字符判断有区分
-
而bin意思是二进制,所以小写u和大写U会被区别
例如你运行:
SELECT name FROM UserInfo WHERE name = 'Lina'
那么在utf8_bin中你就找不到 name = 'lina' 的那一行, 在utf8_general_ci 下可以.
1. utf8_general_ci 不区分大小写,这个你在注册用户名和邮箱的时候就要使用。
2. utf8_general_cs 区分大小写,如果用户名和邮箱用这个 就会照成不良后果
3. utf8_bin:字符串每个字符串用二进制数据编译存储。 区分大小写,而且可以存二进制的内容
utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。
utf8_general_ci校对速度快,但准确度稍差。
utf8_unicode_ci准确度高,但校对速度稍慢。
utf8_unicode_ci比较准确,utf8_general_ci速度比较快。通常情况下 utf8_general_ci的准确性就够我们用的了,在我看过很多程序源码后,发现它们大多数也用的是utf8_general_ci,所以新建数据 库时一般选用utf8_general_ci就可以了
总结:
排序规则,就是指字符比较时是否区分大小写,以及是按照字符编码进行比较还是直接用二进制数据比较。