问题现象:
ceph告警问题:”too many PGs per OSD”
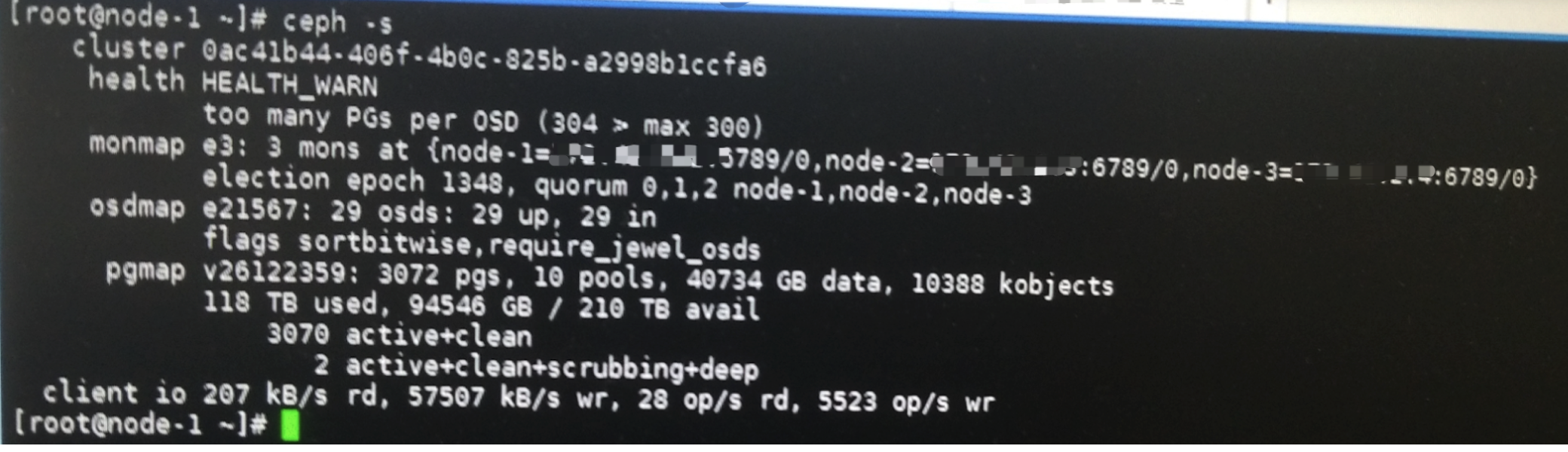
问题原因:
因为最近做了一些踢OSD盘的变更,导致ceph集群OSD数量变少了,所以每个OSD上的PG数量过多,导致ceph health_warn。
当前PG数量调整为了2048 。
当前5台存储节点,只有29个OSD,每个存储节点都有6个OSD,但是其中一台存储节点上缺少一个OSD。
【解决方案】
方法1.
再加1个OSD盘到集群即可。前提是有多余的可用磁盘。
方法2.
调整每个osd默认PG数,参数为mon_pg_warn_max_per_osd。
# ceph --show-config | grep mon_pg_warn_max_per_osd
mon_pg_warn_max_per_osd = 300
2.1 使用ceph tell的方式临时调整这个参数为400:
# ceph tell mon.* injectargs --mon_pg_warn_max_per_osd 400
2.2
1)修改配置文件永久调整配置
# cd /etc/ceph
# vim ceph.conf
[global]
.......
mon_pg_warn_max_per_osd = 400
2)将配置文件推到mon所在的其他节点
# ceph-deploy --overwrite-conf config push ceph1 ceph2
3)重启mon进程
# systemctl restart ceph-mon.target
重启后再查看:
# ceph --show-config | grep mon_pg_warn_max_per_osd
方法3.
删除一个不用的pool可以解决此问题。操作前已经和业务以及研发再次确认过这个pool可以删除。
ceph df查看,可以看到images pool 在环境中没有用处,所以这次通过删除这个pool来解决此问题。
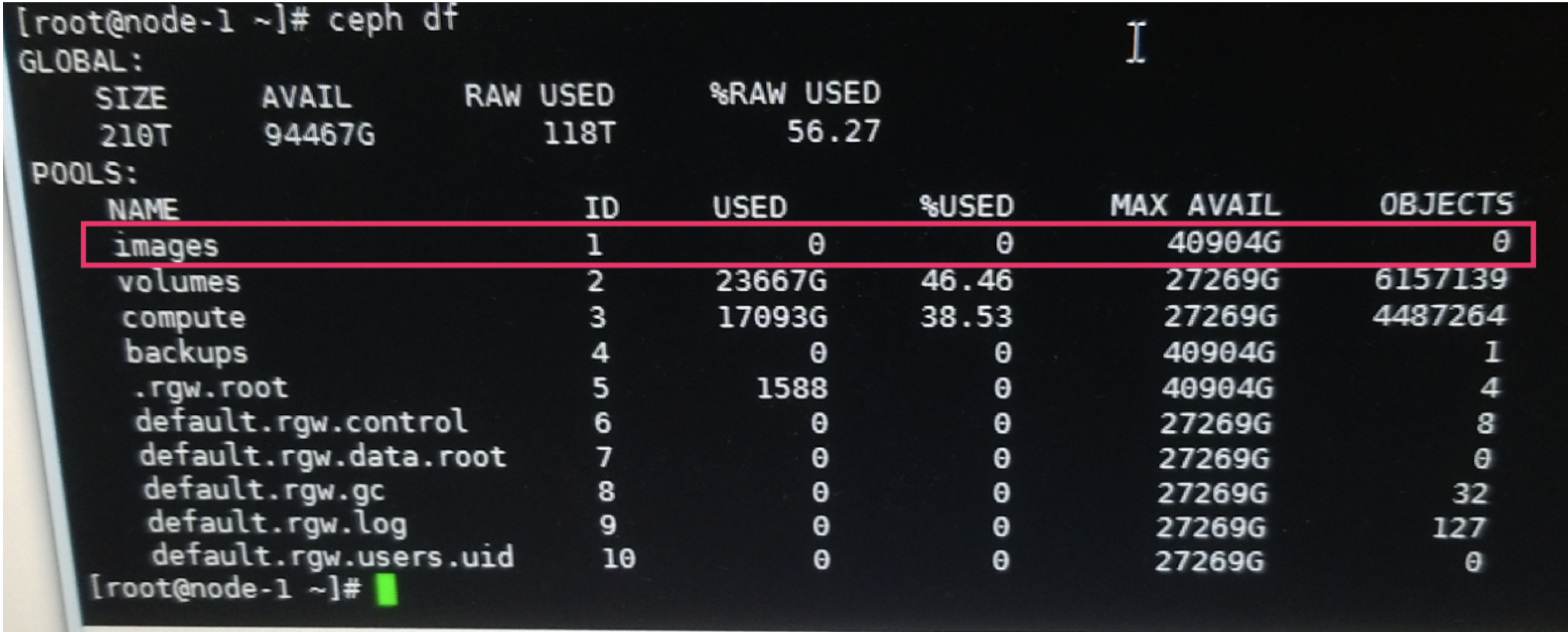
ceph osd pool images images --yes-i-really-really-mean-it
再次查看ceph -s ,可以看到health_ok。