一 引子
二 数字
三 字符串
四 列表
五 元组
六 字典
七 集合
八 数据类型总结
九 字符编码
十 作业
一 引子
1 什么是数据?
x=10,10是我们要存储的数据
2 为何数据要分不同的类型
数据是用来表示状态的,不同的状态就应该用不同的类型的数据去表示
3 数据类型
数字(整形,长整形,浮点型,复数)
字符串
字节串:在介绍字符编码时介绍字节bytes类型
列表
元组
字典
集合
4 按照以下几个点展开数据类型的学习
#一:基本使用
用途
定义方式
常用操作+内置的方法
#二:该类型总结
存一个值or存多个值
只能存一个值
可以存多个值,值都可以是什么类型
有序or无序
可变or不可变
!!!可变:值变,id不变。可变==不可hash
!!!不可变:值变,id就变。不可变==可hash
二 数字
#整型int
1 用途:年龄,等级,qq号等
2 定义方式
# age=18 #age=int(18)
# 浮点型float
1 用途:身高,体重,体质参数等
2 定义方式
# salary = 3.1 # salary=float(3.1)
# 了解:
# 长整型:python2中
x=3L
#复数
x=1+2j
print(x.real)
print(x.imag)
print(type(x))
总结:
1 存一个值or存多个值
只能存一个值
3 可变or不可变
!!!不可变
三 字符串
1、用途:姓名,性别,住址等描述性的数据
2、定义方式:‘’ , “”, ''' '''内定义的一串字符
msg='hello world'
#优先掌握的操作:
1、按索引取值(正向取+反向取) :只能取
print(msg[0],type(msg[0]))
print(msg[-1])
2、切片(顾头不顾尾,步长)
print(msg[0:3]) #>=0 <3
print(msg[0:7]) #>=0 <7
print(msg[0:7:1]) #>=0 <7
print(msg[0:7:2]) #hello w #hlow
print(msg[:])
print(msg[5:1:-1])
print(msg[-1::-1])
3、长度len
print(msg.__len__())
print(len(msg)) #msg.__len__()
4、成员运算in和not in
msg='hello world'
print('llo' in msg)
print('llo' not in msg)
5、移除空白strip
password=' alex3714 '
print(password.strip())
password=input('>>: ').strip()
password='alex 3714 '
print(password.strip())
6、切分split
user_info='root:x:0:0::/root:/bin/bash'
res=user_info.split(':')
print(res[0])
cmd='get /root/a/b/c/d.txt'
print(cmd.split())
file_path='C:\a\d.txt'
print(file_path.split('\',1))
file_path='C:\a\d.txt'
print(file_path.rsplit('\',1))
7、循环
msg='hel'
n=0
size=len(msg)
while n < size:
print(msg[n])
n+=1
for i in msg: #i=l
print(i)
for i in range(0,5,2): #0 2 4
print(i)
msg='hel'
for i in range(len(msg)): #0 1 2
print(msg[i])
for i in range(3):
print(i)
x='aaa'
print(id(x))
x='bbb'
print(id(x))
该类型总结
1 存一个值or存多个值
只能存一个值
2 有序
3 可变or不可变
!!!不可变:值变,id就变。不可变==可hash
#需要掌握的
1、strip,lstrip,rstrip 2、lower,upper 3、startswith,endswith 4、format的三种玩法 5、split,rsplit 6、join 7、replace 8、isdigit
#strip name='*egon**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) #lower,upper name='egon' print(name.lower()) print(name.upper()) #startswith,endswith name='alex_SB' print(name.endswith('SB')) print(name.startswith('alex')) #format的三种玩法 res='{} {} {}'.format('egon',18,'male') res='{1} {0} {1}'.format('egon',18,'male') res='{name} {age} {sex}'.format(sex='male',name='egon',age=18) #split name='root:x:0:0::/root:/bin/bash' print(name.split(':')) #默认分隔符为空格 name='C:/a/b/c/d.txt' #只想拿到顶级目录 print(name.split('/',1)) name='a|b|c' print(name.rsplit('|',1)) #从右开始切分 #join tag=' ' print(tag.join(['egon','say','hello','world'])) #可迭代对象必须都是字符串 #replace name='alex say :i have one tesla,my name is alex' print(name.replace('alex','SB',1)) #isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法 age=input('>>: ') print(age.isdigit())
1、strip,lstrip,rstrip
print("**alex****".strip('*'))
print("**alex****".lstrip('*'))
print("**alex****".rstrip('*'))
#2、lower,upper
print('ALeX'.lower())
print('aaa'.upper())
#3、startswith,endswith
msg='alex is SB'
print(msg.startswith('alex'))
print(msg.startswith('a'))
print(msg.endswith('SB'))
#4、format的三种玩法
print('my name is %s my age is %s' %('alex',18))
+print('my name is {} my age is {}'.format('alex',18))
print('my name is {} my age is {}'.format(18,'alex'))
+print('{0} {1} {0}'.format('alex',18))
+print('my name is {name} my age is {age}'.format(age=18,name='male'))
#5、split,rsplit
info='root:x:0:0'
l=info.split(':')
print(l)
#6、join
print(':'.join(l))
l=[1,2,3]
' '.join(l) #报错:只有在列表内的元素全是字符串类型,才能用join拼接
#7、replace
msg='alex say my name is alex ,alex have on tesla'
msg=msg.replace('alex','SB',1)
print(msg)
#8、isdigit
age=input('>>: ').strip()
print(age.isdigit()) #age='123'
if age.isdigit():
age=int(age)
else:
print('必须输入数字')
#了解
1、find,rfind,index,rindex,count 2、center,ljust,rjust,zfill 3、expandtabs 4、captalize,swapcase,title 5、is数字系列 6、is其他
#find,rfind,index,rindex,count name='egon say hello' print(name.find('o',1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引,就找一个 # print(name.index('e',2,4)) #同上,但是找不到会报错
# ->->->->->->->->->->->->->->->->->->->->->->->->->无值即报错
print(name.count('e',1,3)) #顾头不顾尾,如果不指定范围则查找所有 #center,ljust,rjust,zfill name='egon' print(name.center(30,'-')) print(name.ljust(30,'*')) print(name.rjust(30,'*')) print(name.zfill(50)) #用0填充 #expandtabs name='egon hello' print(name) print(name.expandtabs(1)) #把字符串中的 tab 符号(' ')转为空格,tab 符号(' ')默认的空格数是 8 #captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg='egon say hi' print(msg.title()) #每个单词的首字母大写 #is数字系列 #在python3中 num1=b'4' #bytes num2=u'4' #unicode,python3中无需加u就是unicode num3='四' #中文数字 num4='Ⅳ' #罗马数字 #isdigt:bytes,unicode print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #isdecimal:uncicode #bytes类型无isdecimal方法 print(num2.isdecimal()) #True print(num3.isdecimal()) #False print(num4.isdecimal()) #False #isnumberic:unicode,中文数字,罗马数字 #bytes类型无isnumberic方法 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True #三者不能判断浮点数 num5='4.3' print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric()) ''' 总结: 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 如果要判断中文数字或罗马数字,则需要用到isnumeric ''' #is其他 print('===>') name='egon123' print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isidentifier()) print(name.islower()) print(name.isupper()) print(name.isspace()) print(name.istitle())
#1、find,rfind,index,rindex,count
msg='hello world'
print(msg.find('wo'))
print(msg.find('SB'))
print(msg.index('wo'))
print(msg.index('SB')) #ValueError: substring not found
print(msg.count('l'))
print(msg.count('SB'))
#2、center,ljust,rjust,zfill
print('egon'.center(30,'*'))
print('egon'.ljust(30,'*'))
print('egon'.rjust(30,'*'))
print('egon'.zfill(30))
#3、expandtabs
print('hello world'.expandtabs(10))
#4、captalize,swapcase,title
print('i am egon'.capitalize())
print('i am egon'.title())
print('AbC'.swapcase())
#5、is数字系列
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='壹' #中文数字
num4='Ⅳ' #罗马数字
#bytes,unicode
print(num1.isdigit())
print(num2.isdigit())
print(num3.isdigit())
print(num4.isdigit())
#unicode
print(num2.isdecimal())
print(num3.isdecimal())
print(num4.isdecimal())
#unicode,中文,罗马
print(num2.isnumeric())
print(num3.isnumeric())
print(num4.isnumeric())
#6、is其他
name='egon123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print('print1111'.isidentifier())
print('abcA'.islower())
print(name.isupper())
print(' '.isspace())
print('Am Ia'.istitle())
练习
写代码,有如下变量,请按照要求实现每个功能 (共6分,每小题各0.5分) name = " aleX" 1) 移除 name 变量对应的值两边的空格,并输出处理结果 2) 判断 name 变量对应的值是否以 "al" 开头,并输出结果 3) 判断 name 变量对应的值是否以 "X" 结尾,并输出结果 4) 将 name 变量对应的值中的 “l” 替换为 “p”,并输出结果 5) 将 name 变量对应的值根据 “l” 分割,并输出结果。 6) 将 name 变量对应的值变大写,并输出结果 7) 将 name 变量对应的值变小写,并输出结果 8) 请输出 name 变量对应的值的第 2 个字符? 9) 请输出 name 变量对应的值的前 3 个字符? 10) 请输出 name 变量对应的值的后 2 个字符? 11) 请输出 name 变量对应的值中 “e” 所在索引位置? 12) 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。


# 写代码,有如下变量,请按照要求实现每个功能 (共6分,每小题各0.5分) name = " aleX" # 1) 移除 name 变量对应的值两边的空格,并输出处理结果 name = ' aleX' a=name.strip() print(a) # 2) 判断 name 变量对应的值是否以 "al" 开头,并输出结果 name=' aleX' if name.startswith(name): print(name) else: print('no') # 3) 判断 name 变量对应的值是否以 "X" 结尾,并输出结果 name=' aleX' if name.endswith(name): print(name) else: print('no') # 4) 将 name 变量对应的值中的 “l” 替换为 “p”,并输出结果 name=' aleX' print(name.replace('l','p')) # 5) 将 name 变量对应的值根据 “l” 分割,并输出结果。 name=' aleX' print(name.split('l')) # 6) 将 name 变量对应的值变大写,并输出结果 name=' aleX' print(name.upper()) # 7) 将 name 变量对应的值变小写,并输出结果 name=' aleX' print(name.lower()) # 8) 请输出 name 变量对应的值的第 2 个字符? name=' aleX' print(name[1]) # 9) 请输出 name 变量对应的值的前 3 个字符? name=' aleX' print(name[:3]) # 10) 请输出 name 变量对应的值的后 2 个字符? name=' aleX' print(name[-2:]) # 11) 请输出 name 变量对应的值中 “e” 所在索引位置? name=' aleX' print(name.index('e')) # 12) 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。 name=' aleX' a=name[:-1] print(a)
四 列表
#作用:多个装备,多个爱好,多门课程,多个女朋友等 #定义:[]内可以有多个任意类型的值,逗号分隔 # my_girl_friends=['alex','wupeiqi','yuanhao',4,5] #本质my_girl_friends=list([...]) # print(list('hello')) # print(int('123')) # print(str(123))
#优先掌握的操作: #1、按索引存取值(正向存取+反向存取):即可存也可以取 # my_girl_friends=['alex','wupeiqi','yuanhao',4,5] #2、切片(顾头不顾尾,步长) #3、长度 # print(my_girl_friends.__len__()) # print(len(my_girl_friends)) #4、成员运算in和not in # print('wupeiqi' in my_girl_friends) #5、追加 # my_girl_friends[5]=3 #IndexError: list assignment index out of range # my_girl_friends.append(6) # print(my_girl_friends) #6、删除 my_girl_friends=['alex','wupeiqi','yuanhao',4,5] #单纯的删除 # del my_girl_friends[0] # print(my_girl_friends) # res=my_girl_friends.remove('yuanhao') # print(my_girl_friends) # print(res) # print(my_girl_friends) #删除并拿到结果:取走一个值 # res=my_girl_friends.pop(2) # res=my_girl_friends.pop() # print(res) # my_girl_friends=['alex','wupeiqi','yuanhao',4,5] # print(my_girl_friends.pop(0)) #'alex' # print(my_girl_friends.pop(0)) #'wupeqi' # print(my_girl_friends.pop(0)) #'yuanhao' #7、循环 # my_girl_friends=['alex','wupeiqi','yuanhao',4,5] # i=0 # while i < len(my_girl_friends): # print(my_girl_friends[i]) # i+=1 # for item in my_girl_friends: # print(item) # for i in range(10): # if i== 3: # break # # continue # print(i) # else: # print('===>')
#掌握的方法 my_girl_friends=['alex','wupeiqi','yuanhao','yuanhao',4,5] # my_girl_friends.insert(1,'egon') # print(my_girl_friends) # my_girl_friends.clear() # print(my_girl_friends) # l=my_girl_friends.copy() # print(l) # print(my_girl_friends.count('yuanhao')) # l=['egon1','egon2'] # my_girl_friends.extend(l) # my_girl_friends.extend('hello') # print(my_girl_friends)
# ['alex', 'wupeiqi', 'yuanhao', 'yuanhao', 4, 5, 'egon1', 'egon2', 'h', 'e', 'l', 'l', 'o'] # my_girl_friends=['alex','wupeiqi','yuanhao','yuanhao',4,5] # print(my_girl_friends.index('wupeiqi')) # print(my_girl_friends.index('wupeiqissssss')) # ->->->->->->->->->->->->->->->->->->->->->->->->->无值即报错 # my_girl_friends.reverse() # my_girl_friends=['alex','wupeiqi','yuanhao','yuanhao',4,5] # my_girl_friends.reverse() # print(my_girl_friends) # l=[1,10,4,11,2,] # l.sort(reverse=True) # print(l) # x='healloworld' # y='he2' # print(x > y) # l=['egon','alex','wupei'] # l.sort() # print(l)
二:该类型总结
1 存一个值or存多个值
可以存多个值,值都可以是任意类型
2 有序
3 可变or不可变
!!!可变:值变,id不变。可变==不可hash
练习 # 1. 有列表data=['alex',49,[1900,3,18]],分别取出列表中的名字,年龄,出生的年,月,日赋值给不同的变量 # 2. 用列表模拟队列(先进先出) l=[] # l.append('alex') # l.append('wupeiqi') # l.append('yuanhao') # l.append('huowentian') # print(l) # print(l.pop(0)) # print(l.pop(0)) # print(l.pop(0)) # print(l.pop(0)) # l=[] # l.insert(0,'alex') # l.insert(0,'wupeqiqi') # l.insert(0,'yuanhao') # l.insert(0,'huowentian') # print(l) # # print(l.pop()) # print(l.pop()) # print(l.pop()) # print(l.pop()) # 3. 用列表模拟堆栈(先进后出,后进先出) # 4. 有如下列表,请按照年龄排序(涉及到匿名函数)
l=[
{'name':'alex','age':84},
{'name':'oldboy','age':73},
{'name':'egon','age':18},
]
答案: l.sort(key=lambda item:item['age']) print(l)
五 元组
#作用:存多个值,对比列表来说,元组不可变(是可以当做字典的key的),主要是用来读 #定义:与列表类型比,只不过[]换成() age=(11,22,33,44,55) #本质age=tuple((11,22,33,44,55)) # print(type(age)) # age[0]=12 # t=(1,2,['a','b']) # print(id(t[2])) # t[2][0]='A' # print(id(t[2])) # print(t)
#优先掌握的操作: #1、按索引取值(正向取+反向取):只能取 #2、切片(顾头不顾尾,步长) # age=(11,22,33,44,55) # print(age[0:3]) # print(age) #3、长度 # age=(11,22,33,44,55) # print(len(age)) #4、成员运算in和not in # age=(11,22,33,44,55) # print(11 in age) #5、循环 # for item in age: # print(item)
#掌握 # age=(11,22,33,44,55) # print(age.index(33)) # print(age.index(33333)) # ->->->->->->->->->->->->->->->->->->->->->->->->->无值即报错 # print(age.count(33))
二:该类型总结
1 存一个值or存多个值
可以存多个值,值都可以是任意类型
2 有序
3 可变or不可变
!!!不可变:值变,id就变。不可变==可hash
#简单购物车,要求如下: 实现打印商品详细信息,用户输入商品名和购买个数,则将商品名,价格,购买个数加入购物列表,如果输入为空或其他非法输入则要求用户重新输入 msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, }
msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, } goods_l=[] while True: for key,item in msg_dic.items(): print('name:{name} price:{price}'.format(price=item,name=key)) choice=input('商品>>: ').strip() if not choice or choice not in msg_dic:continue count=input('购买个数>>: ').strip() if not count.isdigit():continue goods_l.append((choice,msg_dic[choice],count)) print(goods_l)
六 字典
#用途:存放多个值,key:value,存取速度快
#定义:key必须是不可变类型(int,float,str,tuple),value可以是任意类型
# info={'name':'egon','age':18,'sex':'male'} #info=dict({'name':'egon','age':18,'sex':'male'})
#了解
# info=dict(age=18,sex='male',name='egon')
# print(info)
# info=dict([('name','egon'),('age',18),('sex','male')])
# info=dict([['name','egon'],['age',18],['sex','male']])
# print(info)
# info={}.fromkeys(['name','age','sex'],None)
# info={}.fromkeys('hello',None)
# print(info)
#优先掌握的操作:
#1、按key存取值:可存可取
# d={'name':'egon'}
# print(d['name'])
#
# d['age']=18
# print(d)
#2、长度len
# info={'name':'egon','age':18,'sex':'male'}
# print(len(info))
#3、成员运算in和not in
# info={'name':'egon','age':18,'sex':'male'}
# print('name' in info)
#4、删除
info={'name':'egon','age':18,'sex':'male'}
# print(info.pop('name'))
# print(info)
# print(info.popitem()) #('sex', 'male')
# print(info)
#5、键keys(),值values(),键值对items() #了解
# print(info.keys())
# print(list(info.keys())[0])
# print(list(info.values()))
# print(list(info.items())) #获得由键和值组成的列表
#6、循环
# info={'name':'egon','age':18,'sex':'male'}
# for k in info:
# print(k,info[k])
#7、排序
l=[
{'name':'alex','age':84},
{'name':'oldboy','age':73},
{'name':'egon','age':18},
]
l.sort(key=lambda x:x['age'])
print(l)
dic.items() 获得由键和值组成的列表 for i in data.keys(): print i,data[i] for i in data: print i,data[i] <效率高> for i,val in data.items(): print i,val <效率低> for i in data: print i+":"+data[i]
防止因无键值报错 if data.has_key("name"): print data["name"] print data.get("name")
#其他需要掌握的方法
# info={'name':'egon','age':18,'sex':'male'}
# print(info['hobbies']) # ->->->->->->->->->->->->->->->->->->->->->->->->->无值即报错
# print(info.get('hobbies','没有')) #得到键k的值。 无键值不报错,返回空
# print(info.pop('name1',None))
# d={'x':1,'y':2,'name':'EGON'}
# info.update(d)
# print(info)
# info={'name':'egon','age':16,'sex':'male'}
# value=info.setdefault('age',18) #如果key存在,则不修改,返回已经有的key对应的value
# print(value)
# print(info)
info={'name':'egon',}
# info['hobbies']=[]
# info['hobbies'].append('music')
# info['hobbies'].append('read')
# print(info)
info={'name':'egon',}
# if 'hobbies' not in info:
# info['hobbies']=[]
# else:
# info['hobbies'].append('music')
# hobbies_list=info.setdefault('hobbies',[])
# print(hobbies_list)
# hobbies_list.append('play')
# hobbies_list.append('read')
#
# print(info)
二:该类型总结
1 存一个值or存多个值
可以存多个值,值都可以是任意类型,key必须是不可变类型
2 无序
3 可变or不可变
!!!可变:值变,id不变。可变==不可hash
1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中 即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
a={'k1':[],'k2':[]}
c=[11,22,33,44,55,66,77,88,99,90]
for i in c:
if i>66:
a['k1'].append(i)
else:
a['k2'].append(i)
print(a)
2 统计s='hello alex alex say hello sb sb'中每个单词的个数 结果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2}
s='hello alex alex say hello sb sb' l=s.split() dic={} for item in l: if item in dic: dic[item]+=1 else: dic[item]=1 print(dic)
s='hello alex alex say hello sb sb' dic={} words=s.split() print(words) for word in words: #word='alex' dic[word]=s.count(word) print(dic) #利用setdefault解决重复赋值 ''' setdefault的功能 1:key存在,则不赋值,key不存在则设置默认值 2:key存在,返回的是key对应的已有的值,key不存在,返回的则是要设置的默认值 d={} print(d.setdefault('a',1)) #返回1 d={'a':2222} print(d.setdefault('a',1)) #返回2222 ''' s='hello alex alex say hello sb sb' dic={} words=s.split() for word in words: #word='alex' dic.setdefault(word,s.count(word)) print(dic) #利用集合,去掉重复,减少循环次数 s='hello alex alex say hello sb sb' dic={} words=s.split() words_set=set(words) for word in words_set: dic[word]=s.count(word) print(dic) 其他做法(重点看setdefault的用法)
七 集合
#作用:去重,关系运算, #定义: 知识点回顾 可变类型是不可hash类型 不可变类型是可hash类型 #定义集合: 集合:可以包含多个元素,用逗号分割, 集合的元素遵循三个原则: 1:每个元素必须是不可变类型(可hash,可作为字典的key) 2:没有重复的元素 3:无序 注意集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
#优先掌握的操作: #1、长度len # s={1,2,3,1} #s=set({1,2,3,1}) # print(len(s)) #2、成员运算in和not in # names={'egon','alex'} # print('egon' in names) #3、|合集 pythons={'egon','axx','ysb','wxx'} linuxs={'egon','oldboy','oldgirl','smallboy','smallgirl'} #4、&交集:同时报名两门课程的学生 # print(pythons & linuxs) # print(pythons.intersection(linuxs)) #5、|合集:老男孩所有的学生 # print(pythons | linuxs) # print(pythons.union(linuxs)) #6、^对称差集:没有同时报名两门课程 # print(pythons ^ linuxs) # print(pythons.symmetric_difference(linuxs)) #7.1 -差集:只报名python课程的学生 # print(pythons - linuxs) # print(pythons.difference(linuxs)) #7.2 -差集:只报名linux课程的学生 # print(linuxs-pythons) #8 父集:>,>=,子集:<,<= # s1={1,2,3} # s2={1,2,} # print(s1 >= s2) # print(s1.issuperset(s2)) # print(s2.issubset(s1)) # linuxs={'egon','oldboy','oldgirl','smallboy','smallgirl'} # for student in linuxs: # print(student)
#了解的知识点 # s1={1,2,3} # s2={1,2,} # print(s1-s2) # print(s1.difference(s2)) # s1.difference_update(s2) #s1=s1.difference(s2) # print(s1) # s2={1,2,3,4,5,'a'} # print(s2.pop()) # s2.add('b') # print(s2) # s2.discard('b') # s2.remove('b') #删除的元素不存在则报错 # print(s2) # s1={1,2,3,4,5,'a'} # s2={'b','c',} # print(s1.isdisjoint(s2)) #两个集合没有共同部分时,返回值为True # s2={1,2,3,4,5,'a'} # s2.update({6,7,8}) # print(s2) # l=['a','b',1,'a','a'] # print(list(set(l))) # print(set('hello')) # print(set({'a':1,'b':2,'c':3}))
练习
一.关系运算 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合 pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'} linuxs={'wupeiqi','oldboy','gangdan'} 1. 求出即报名python又报名linux课程的学员名字集合 2. 求出所有报名的学生名字集合 3. 求出只报名python课程的学员名字 4. 求出没有同时这两门课程的学员名字集合
# 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合 pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'} linuxs={'wupeiqi','oldboy','gangdan'} # 求出即报名python又报名linux课程的学员名字集合 print(pythons & linuxs) # 求出所有报名的学生名字集合 print(pythons | linuxs) # 求出只报名python课程的学员名字 print(pythons - linuxs) # 求出没有同时这两门课程的学员名字集合 print(pythons ^ linuxs)
二.去重 1. 有列表l=['a','b',1,'a','a'],列表元素均为可hash类型,去重,得到新列表,且新列表无需保持列表原来的顺序 2.在上题的基础上,保存列表原来的顺序 3.去除文件中重复的行,肯定要保持文件内容的顺序不变 4.有如下列表,列表元素为不可hash类型,去重,得到新列表,且新列表一定要保持列表原来的顺序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ]
#去重,无需保持原来的顺序 l=['a','b',1,'a','a'] print(set(l)) #去重,并保持原来的顺序 #方法一:不用集合 l=[1,'a','b',1,'a'] l1=[] for i in l: if i not in l1: l1.append(i) print(l1) #方法二:借助集合 l1=[] s=set() for i in l: if i not in s: s.add(i) l1.append(i) print(l1) #同上方法二,去除文件中重复的行 import os with open('db.txt','r',encoding='utf-8') as read_f, open('.db.txt.swap','w',encoding='utf-8') as write_f: s=set() for line in read_f: if line not in s: s.add(line) write_f.write(line) os.remove('db.txt') os.rename('.db.txt.swap','db.txt') #列表中元素为可变类型时,去重,并且保持原来顺序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ] # print(set(l)) #报错:unhashable type: 'dict' s=set() l1=[] for item in l: val=(item['name'],item['age'],item['sex']) if val not in s: s.add(val) l1.append(item) print(l1) #定义函数,既可以针对可以hash类型又可以针对不可hash类型 def func(items,key=None): s=set() for item in items: val=item if key is None else key(item) if val not in s: s.add(val) yield item print(list(func(l,key=lambda dic:(dic['name'],dic['age'],dic['sex']))))
八 数据类型总结
按存储空间的占用分(从低到高)
数字 字符串 集合:无序,即无序存索引相关信息 元组:有序,需要存索引相关信息,不可变 列表:有序,需要存索引相关信息,可变,需要处理数据的增删改 字典:无序,需要存key与value映射的相关信息,可变,需要处理数据的增删改
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
| 不可变 | 数字,字符串,元组 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
九 字符编码
1.计算机基础知识
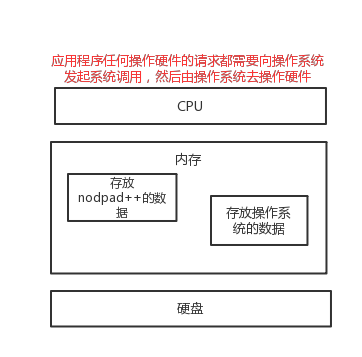
2.文本编辑器存取文件的原理(nodepad++,pycharm,word)
#1、打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失 #2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。 #3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。3.python解释器执行py文件的原理 ,例如python test.py
#第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器 #第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名) #第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")
4.总结python解释器与文件本编辑的异同
#1、相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样 #2、不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法。
5.什么是字符编码
计算机要想工作必须通电,即用‘电’驱使计算机干活,也就是说‘电’的特性决定了计算机的特性。电的特性即高低电平(人类从逻辑上将二进制数1对应高电平,二进制数0对应低电平),关于磁盘的磁特性也是同样的道理。结论:计算机只认识数字 很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符? 必须经过一个过程: #字符--------(翻译过程)------->数字 #这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
6.以下两个场景下涉及到字符编码的问题
#1、一个python文件中的内容是由一堆字符组成的,存取均涉及到字符编码问题(python文件并未执行,前两个阶段均属于该范畴) #2、python中的数据类型字符串是由一串字符组成的(python文件执行时,即第三个阶段)
7.总结字符编码的发展可分为三个阶段(重要)
#阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符 ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了 #阶段二:为了满足中文和英文,中国人定制了GBK GBK:2Bytes代表一个中文字符,1Bytes表示一个英文字符 为了满足其他国家,各个国家纷纷定制了自己的编码 日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里 #阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。如何解决这个问题呢??? #!!!!!!!!!!!!非常重要!!!!!!!!!!!! 说白了乱码问题的本质就是不统一,如果我们能统一全世界,规定全世界只能使用一种文字符号,然后统一使用一种编码,那么乱码问题将不复存在, ps:就像当年秦始皇统一中国一样,书同文车同轨,所有的麻烦事全部解决 很明显,上述的假设是不可能成立的。很多地方或老的系统、应用软件仍会采用各种各样的编码,这是历史遗留问题。于是我们必须找出一种解决方案或者说编码方案,需要同时满足: #1、能够兼容万国字符 #2、与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码 这就是unicode(定长), 统一用2Bytes代表一个字符, 虽然2**16-1=65535,但unicode却可以存放100w+个字符,因为unicode存放了与其他编码的映射关系,准确地说unicode并不是一种严格意义上的字符编码表,下载pdf来查看unicode的详情: 链接:https://pan.baidu.com/s/1dEV3RYp 很明显对于通篇都是英文的文本来说,unicode的式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的) 于是产生了UTF-8(可变长,全称Unicode Transformation Format),对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存 #总结:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。 !!!重点!!!
8.文本编辑器之nodpad++ 乱码分析
首先明确概念 #1、文件从内存刷到硬盘的操作简称存文件 #2、文件从硬盘读到内存的操作简称读文件 乱码的两种情况: #乱码一:存文件时就已经乱码 存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存, 本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败 但当我们硬要存的时候,编辑并不会报错(难道你的编码错误,编辑器这个软件就跟着崩溃了吗???),但毫无疑问,不能存而硬存,肯定是乱存了,即存文件阶段就已经发生乱码 而当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了 #用open模拟编辑器的过程 可以用open函数的write可以测试,f=open('a.txt','w',encodig='shift_jis' f.write('你瞅啥 何を見て ') #'你瞅啥'因为在shiftjis中没有找到对应关系而无法保存成功,只存'何を見て '可以成功 #以任何编码打开文件a.txt都会出现其余两个无法正常显示的问题 f=open('a.txt','wb') f.write('何を見て '.encode('shift_jis')) f.write('你愁啥 '.encode('gbk')) f.write('你愁啥 '.encode('utf-8')) f.close() #乱码二:存文件时不乱码而读文件时乱码 存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了,
9.文本编辑器之python解释器
文件test.py以gbk格式保存,内容为: x='林' 无论是 python2 test.py 还是 python3 test.py 都会报错(因为python2默认ascii,python3默认utf-8) 除非在文件开头指定#coding:gbk
10.!!!总结非常重要的两点!!!
#1、保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码 #2、在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。
只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode

#补充: 浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器 如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的结果。
11.执行python程序的三个阶段
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
此时,python解释器会读取test.py的第一行内容,#coding:utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码, 可以用sys.getdefaultencoding()查看,如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的 python2中默认使用ascii,python3中默认使用utf-8
阶段三:读取已经加载到内存的代码(unicode编码格式),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"

内存的编码使用unicode,不代表内存中全都是unicode, 在程序执行之前,内存中确实都是unicode,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode的格式存放于内存中的 但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间)用来存放python的数据类型的值,而python的字符串类型又涉及到了字符的概念 比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放字符串类型的值,至于该字符串类型的值被识别成何种编码存放,这就与python解释器的有关了,而python2与python3的字符串类型又有所不同。
12.python2与python3字符串类型的区别
在python2中有两种字符串类型str和unicode
在python3 中也有两种字符串类型str和bytes
python3中 str默认是unicode
#coding:gbk
x='上' #当程序执行时,无需加u,'上'也会被以unicode形式保存新的内存空间中,
print(type(x)) #<class 'str'>
#x可以直接encode成任意编码格式
print(x.encode('gbk')) #b'xc9xcf'
print(type(x.encode('gbk'))) #<class 'bytes'>
很重要的一点是:看到python3中x.encode('gbk') 的结果xc9xcf正是python2中的str类型的值,而在python3是bytes类型,在python2中则是str类型
python3中 str默认是unicode
python2中的str类型默认就是python3的bytes类型
十 作业
#作业一: 三级菜单
#要求:
打印省、市、县三级菜单
可返回上一级
可随时退出程序
menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, '汽车之家':{}, 'youku':{}, }, '上地':{ '百度':{}, }, }, '昌平':{ '沙河':{ '老男孩':{}, '北航':{}, }, '天通苑':{}, '回龙观':{}, }, '朝阳':{}, '东城':{}, }, '上海':{ '闵行':{ "人民广场":{ '炸鸡店':{} } }, '闸北':{ '火车战':{ '携程':{} } }, '浦东':{}, }, '山东':{}, } exit_flag = False current_layer = menu layers = [menu] while not exit_flag: for k in current_layer: print(k) choice = input(">>:").strip() if choice == "b": current_layer = layers[-1] #print("change to laster", current_layer) layers.pop() elif choice not in current_layer:continue else: layers.append(current_layer) current_layer = current_layer[choice] 三年菜单文艺青年版
#作业二:请闭眼写出购物车程序 #需求: 用户名和密码存放于文件中,格式为:egon|egon123 启动程序后,先登录,登录成功则让用户输入工资,然后打印商品列表,失败则重新登录,超过三次则退出程序 允许用户根据商品编号购买商品 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒 可随时退出,退出时,打印已购买商品和余额